編按:去年六月,《科學》期刊上發表了一篇〈全球公民誠信度 (Civic honesty around the globe)〉的論文,當中的實驗和論點引起軒然大波,各界議論紛紛,也提出諸多看法和駁斥,到底是怎麼一回事呢?
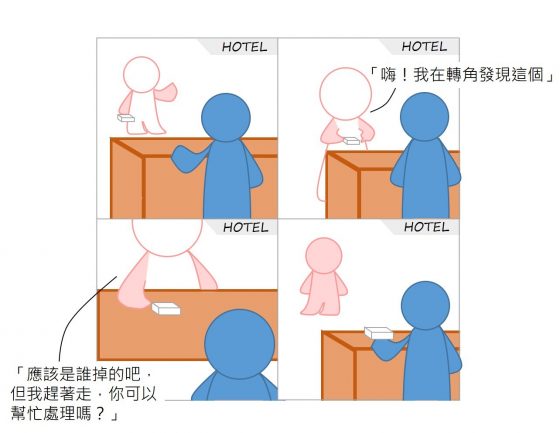
進行這項實驗的研究團隊在全球 40 個國家、355 座城市,做了共計 17,303 次「遺失錢包」的實驗,並為每一個錢包都建立獨立的電子信箱做為聯絡方式,記錄從「遺失錢包」的第一天起,一百天內收到的電子郵件,以「收到錢包的人是否會藉由資訊連絡以進行歸還」來當作實驗評估的指標。

本實驗主要以錢包中「沒錢」和「有錢」為操作變因,來進行「通報歸還率」的比較,並將此結果作為論文中「公民誠信 (civic honesty)」的程度代表。
看到這裡,你可能已經發現,直接將「聯繫歸還的通報率」當成「公民誠信度」似乎不太精準,這便是引起爭議的其中一點。另外還有「各國使用電子信箱的比例不同」、「可能放到失物招領處了」、「風俗文化」等各界對實驗方式的駁斥與質疑。
那麼先撇開這些爭議點,我們能透過這項實驗看到什麼呢?
在錢愈多時,錢包越可能被通報歸還?
從各國通報率的比較圖可以看到,絕大多數的國家在錢包「有錢」的狀況下通報率比較高,這個出人意料的結果,讓研究團隊懷疑起一個最基本的原因:
是錢不夠多嗎?(還不夠多到具有經濟意義上的重要性)
為了測試這樣的可能性,研究團隊在美國、英國、波蘭增加進行了「很多錢」的實驗組。然而如下圖所示,三個國家在「很多錢」的狀況下通報率都更高,總和三個國家的數據平均下來,通報率由低至高依序為「沒錢」的 46%、「有錢」的 61%,以及「很多錢」的 72%。
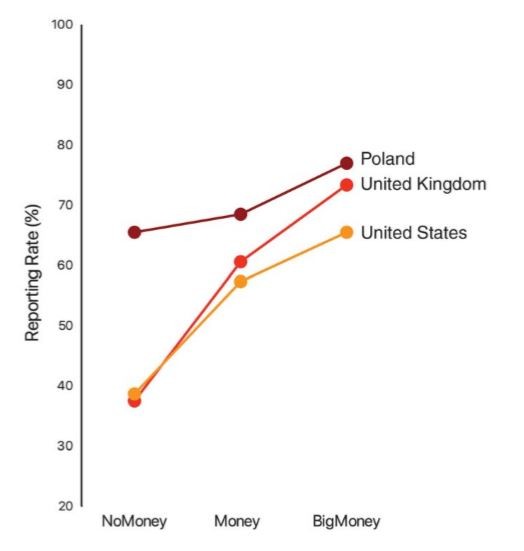
錢愈多,反而通報率愈高,為什麼會這樣子?
對此研究團隊提出了三種解釋:
- 收到錢包的人擔心會因為「沒有歸還」而受到法律上的懲罰,錢愈多的時候愈是如此。
- 實驗僅以錢包的通報率作為評估指標,但收到的人可能私吞了裡面的金錢後才歸還。
- 收到錢包的人希望能夠獲得報酬,並認為錢愈多報酬愈高。
然而在進行了解、調查之後,研究團隊對於以上三種解釋並沒有找到足夠充足的證據支持。

除了以上的可能性,還有別的因素可以解釋實驗結果嗎?
研究團隊重新檢視分析整個實驗的結構,認為實驗結果主要由四個因素相互影響:
- 留著錢包的經濟效益
- 聯絡失主所耗費的心力和時間
- 為了錢包失主的無私著想
- 自我意象的負面代價,也就是覺得自己像個小偷一樣,即「偷竊厭惡 (theft aversion)」
並由此列出了公式,同時進行一個簡單的行為模型測試,來對比原實驗數據。研究團隊認為,一個人(實驗對象)會依據上述四個因素,為了達到下列公式的最大值而做出「不歸還 (a = 0)」或「歸還 (a = 1)」的決定
max {(1-a)m + aα (m+v)-(1-a)γm–ac}.
a 為是否採取歸還錢包的行動,只有兩個數值:0 為不歸還,1 為歸還;m 為錢包裡的金額量;α 為「無私著想」的程度;v 為錢包裡除了錢以外的其他東西;γ 為「偷竊厭惡」的程度;c 為歸還錢包所耗費的心力。
將此公式套入實驗後,研究團隊將收到錢包的人簡單分為以下四類:
- A. 低無私著想、低偷竊厭惡的人(低 α 低 γ ):
只受到物質上自利 (self-interest) 的刺激,無論什麼情況下都不會歸還錢包。 - B. 高無私著想、高偷竊厭惡的人(高 α 高 γ ):
只要此二者大於歸還所花費的心力,無論什麼情況下都會歸還錢包。 - C. 高無私著想、低偷竊厭惡的人(高 α 低 γ ):
會在錢少的時候歸還錢包,但在足夠多錢時不會歸還。 - D. 低無私著想、高偷竊厭惡的人(低 α 高 γ ):
錢少的時候不會歸還,但在足夠多錢時會歸還錢包。
這四種類型在所有收到的人當中的分布數量決定了「錢包通報歸還率」與「錢包裡的金額」本質上的關係。
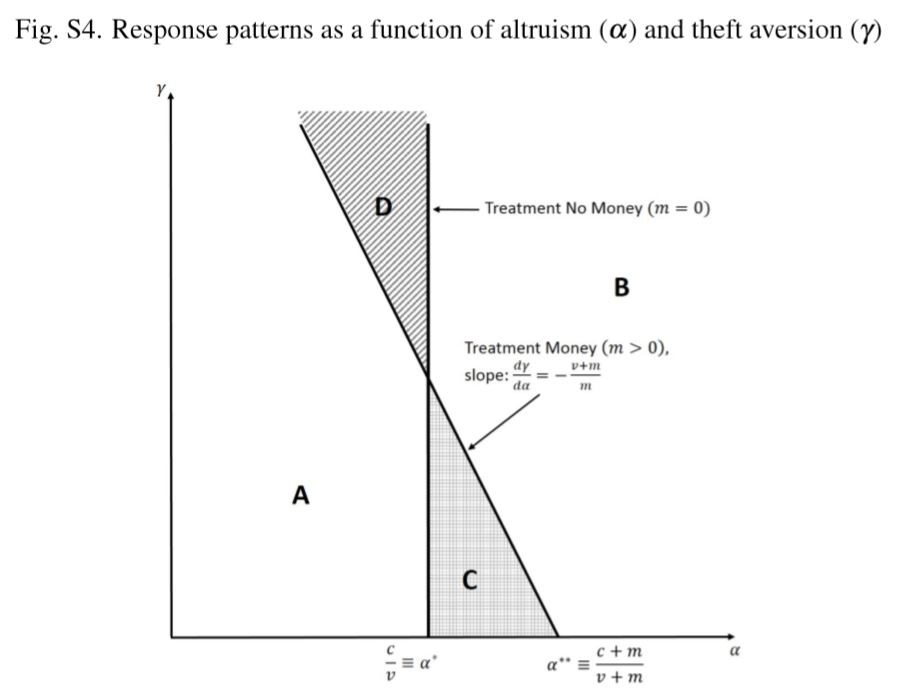
根據上圖可以歸納出:在「有錢」狀況下的通報率為 (B+D) / (A+B+C+D);在「沒錢」的狀況下通報率為 (B+C) / (A+B+C+D)。結合原實驗結果:「有錢」通報率較高,我們可以得知:D 區的人數比 C 區的人數更多。
也就是,高偷竊厭惡的人比高無私著想的人還多
那麼,「無私著想」和「偷竊厭惡」到底代表什麼呢?團隊做出以下解釋:「無私著想」會考量到錢包中「只對失主具有價值」的內容物,例如鑰匙;「偷竊厭惡」則只考量錢包中「對收到的人有價值」的內容物,例如錢。
為了區別此二因素對行為的影響程度,研究團隊設計了不同的實驗和調查。

首先,他們在英國、波蘭、美國另外進行了相同金額下,錢包中「有」和「沒有」鑰匙的實驗,就三國實驗的平均結果而言,「有鑰匙」的通報率比「沒鑰匙」的通報率高 9.2%。從這樣的結果推得:收到錢包的人之所以會歸還,有部分是基於對他人的「無私著想」,他們在乎若自己沒有通報,會對失主所造成的傷害。
而關於「偷竊厭惡」,同樣在英國、波蘭、美國進行了調查,請受訪者一一想像實驗過的四種狀況:「沒錢」、「有錢」、「有錢沒鑰匙」、「很多錢」,並評定各種狀況下「若沒有歸還錢包,會讓自己感覺像在偷竊一樣」的程度,從 0 到 10,數字愈高表示程度愈重。
據受訪者們的調查資料顯示,在錢包中「很多錢」的狀況下沒有歸還,最讓人感覺像在偷竊,其次則為「有錢」,最後才是「沒錢」。這便代表著:因為沒有歸還錢包而付出的自我意象負面代價(即偷竊厭惡),會隨著金額升高而增加,此調查結果亦與之前實驗通報率的行為資料一致。
然而,對比「有錢」與「有錢、沒鑰匙」的調查結果,卻未觀察到偷竊厭惡程度上的確切差異,這可能表示了「偷竊厭惡」這樣的想法,與「只對失主有價值的內容物」無關。
儘管調查的反應結果不能完全概論真實行為與動機,不過這些結果的確和研究團隊的假說一致:
「由不誠所得到的金錢效益愈大,跟心理上負面代價的增加有關」
甚至在取捨時,「避免心理上負面代價的增加」比「透過不誠行為得到微量的經濟獲益」來得更為重要。
我們會不知不覺誇大他人的「自私自利」?
在研究的最後,團隊找來一般民眾與經濟學家,讓他們預測實驗結果。以美國的實驗數據為預測目標,一般民眾認為「沒錢」的通報率最高,「有錢」次之,「很多錢」最低;經濟學者則預測「沒錢」跟「有錢」的通報率都較高,「很多錢」的通報率較低。
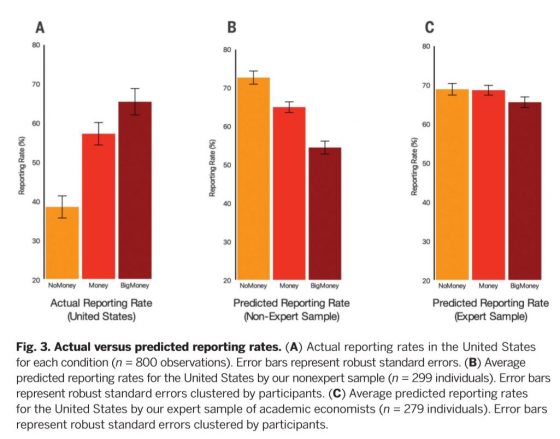
然而不論是大眾或專家,預測都跟實際情形有明顯的差異,這也帶給研究團隊另一啟發 ── 這其實反映了「誇大自利作用」的人類行為心智模型:
當錢越多,大家越會預期「自利心態」增加、對失主的「無私著想」逐漸消失,並認為「偷竊厭惡」對通報率造成的影響很小。

最後,團隊還從實驗結果發現一件事:儘管已盡量客觀地進行實驗,仍能看出「各國」歸還錢包的比率,其間的差距相當可觀,範圍從 14% 分布到 76%。就算將國家 GDP 也考量到實驗設計中(依 GDP 調整錢包金額),這樣的差異還是普遍存在。
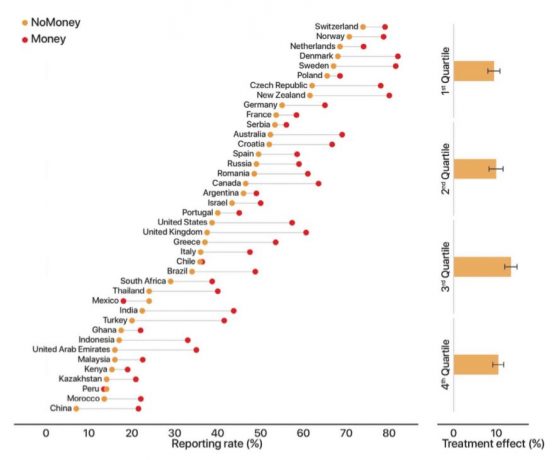
如此結果在某種程度上也顯示出,除了國家財力,還存在著其他因素影響了通報率,同時,理論模型也需要考量除了無私著想和偷竊厭惡之外,其他可能影響的動機再進行修正。
對此研究團隊分析,對經濟上有利的地理條件,包括政治制度 (political institution)、國民教育 (national education)、強調「道德規範超越個人的內團體 (in-group)1」的文化價值等等,也同樣與公民誠信度具有正向相關 (positively associated)。期許未來的研究能夠更進一步分辨這些「其他因素」究竟如何促成人們行為上的社會差異 (societal differences)。
註解:
- 內團體 (in-group):指具共同利益關係,成員間彼此具有歸屬感,並且密切結合的社會群體,類似小圈子或自己人的概念。
資料來源:
- Alain Cohn, Michel André Maréchal, David Tannenbaum, Christian Lukas Zünd (2019) Civic honesty around the globe. Science. Volume 365, Issue 6448, pp. 70-73
- 維基百科:自利、自我意象、內團體與外團體
- 國家教育研究院雙語詞彙、學術名詞暨辭書資訊網:political institution