下載 Youtube 影片、自動生成影片逐字稿、AI 智慧翻譯、匯出雙語 SRT 字幕、字幕內嵌 MP4 影片,甚至是把你的電腦當成 AI 運算伺服器、使用多模態 AI 模型來做圖片辨識……這一切的一切通通都免費,敢有可能 (Kám ū khó-lîng)?
今天的影片要來跟你分享開源 AI 套件 Ollama,這個開源套件AJ 最近上課演講工作坊逢人必教。
今天的影片,我們要手把手教你使用 Ollama 在你的電腦裡執行各種免費開源 AI 模型,希望你能跟我一樣成為 AI 暈船仔……Ollama 真香……啊扯遠了,我們沒有點數可以送。
今天的影片會分成三個部分:
- Ollama 安裝與模型下載
- 結合 Memo 翻譯影片字幕
- 用多模態模型做圖片辨識
Ollama 安裝與模型下載
首先我們要先安裝 Ollama:
來到 ollama.com 點選 Download,下載適合自己的版本後進行安裝,安裝完畢之後,啟動 Ollama。以我的電腦來說右上角就會出現一個小小的 Ollama 圖示,這樣就成功安裝囉!
接著我們需要下載 AI 模型到你的電腦:
回到 Ollama 首頁,點選右上角 Models,這邊就會列出所有官方支援的模型,比如最近很流行的 Meta LLAMA 3、微軟的 Phi3、法國 Mistral AI 公司的 Mistral、Google Gemini 模型的開源版 Gemma 都有,你可以挑選喜歡的來測試。
比如我點選 LLAMA 3 的連結,模型頁面有兩個地方要注意:一是模型大小,LLAMA3 是 4.7G,一般而言要玩大模型,電腦記憶體至少 16G,預算夠就 24G 不嫌多;如果你是使用一般文書電腦,記憶體 8G 的話,建議你現在馬上停止你的任何動作。我有測試過電腦會直接當機……不要說我沒有提醒你。
點開 Latest 選單可以依照需求選擇不同版本的模型:
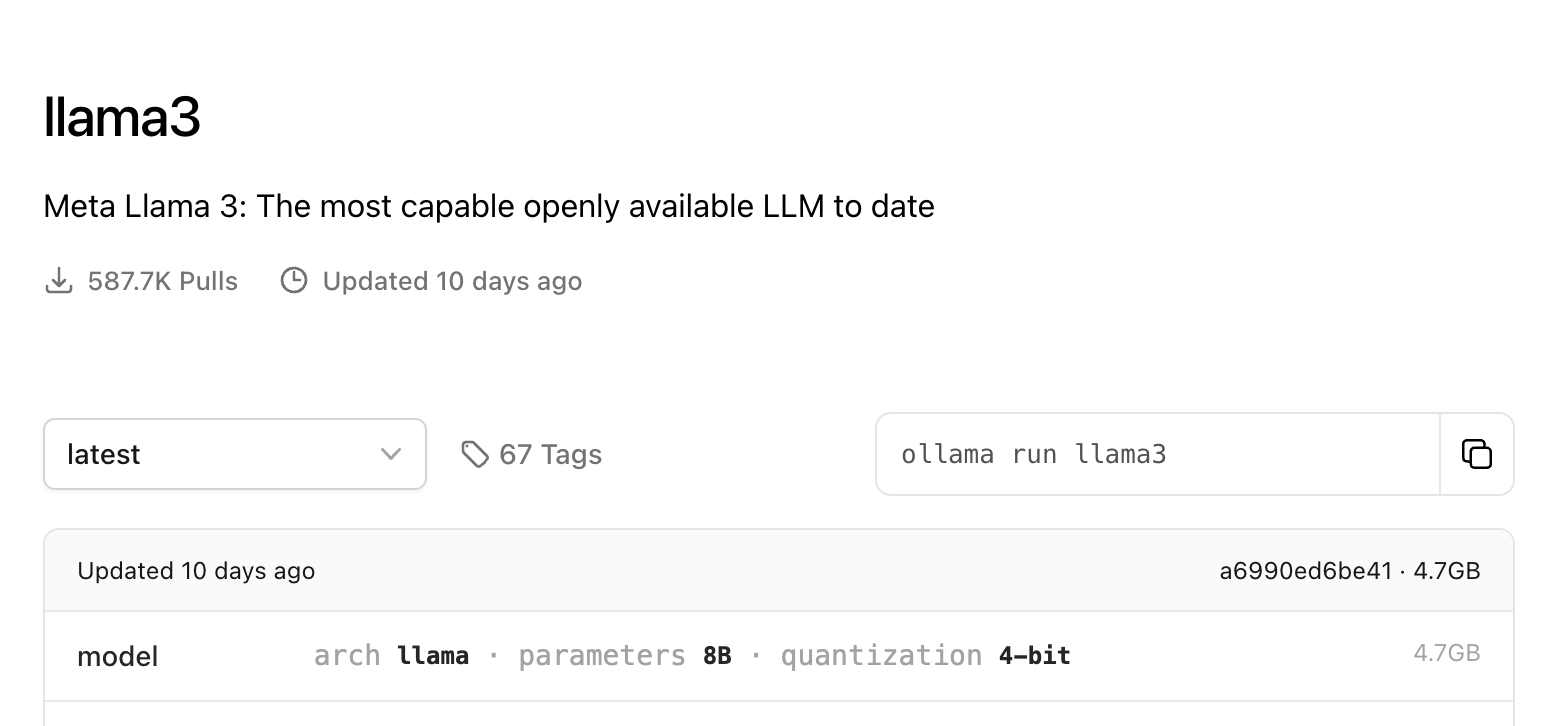
不過我們直接點選最右邊複製執行指令,打開電腦的終端機程式,或著命令提示字元,貼上,這樣電腦就會開始下載並且自動安裝囉。
你可以用 ollama list 指令查看現在電腦內有哪些模型,如果硬碟容量有限,用 ollama rm 後面加上模型名稱可以刪除模型。比如:ollama rm llama3。我們這邊另外安裝 llava 模型:ollama run llava,這樣準備工作就完成囉。
Ollama + memo
最近只要演講上課,我一定會分享 Memo 這套好用的軟體,我們之前也有一支影片分享他的用法。
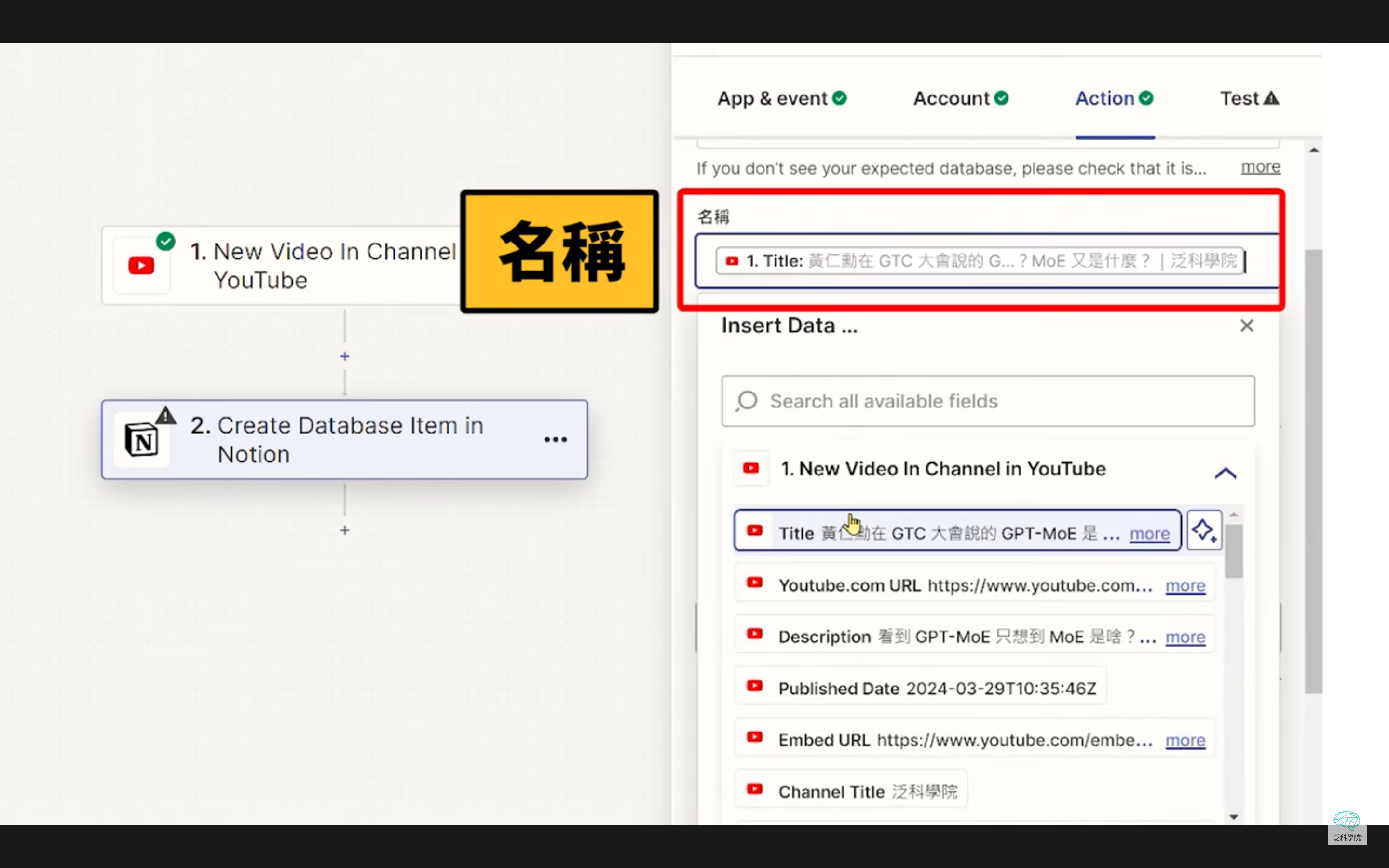
最近 Memo 更新之後,我們就可以直接使用 Ollama 結合特定的模型來進行字幕的翻譯。舉例來說,我們打開 memo,複製 Youtube 網址;我們用這支 楊立昆 的演講,貼上網址,開始下載,下載完畢後使用電腦進行語音辨識,接著我們就可以使用 Ollama 搭配剛剛準備好的 LLama3 模型來做翻譯!
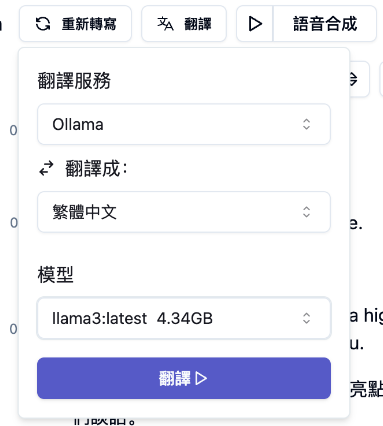
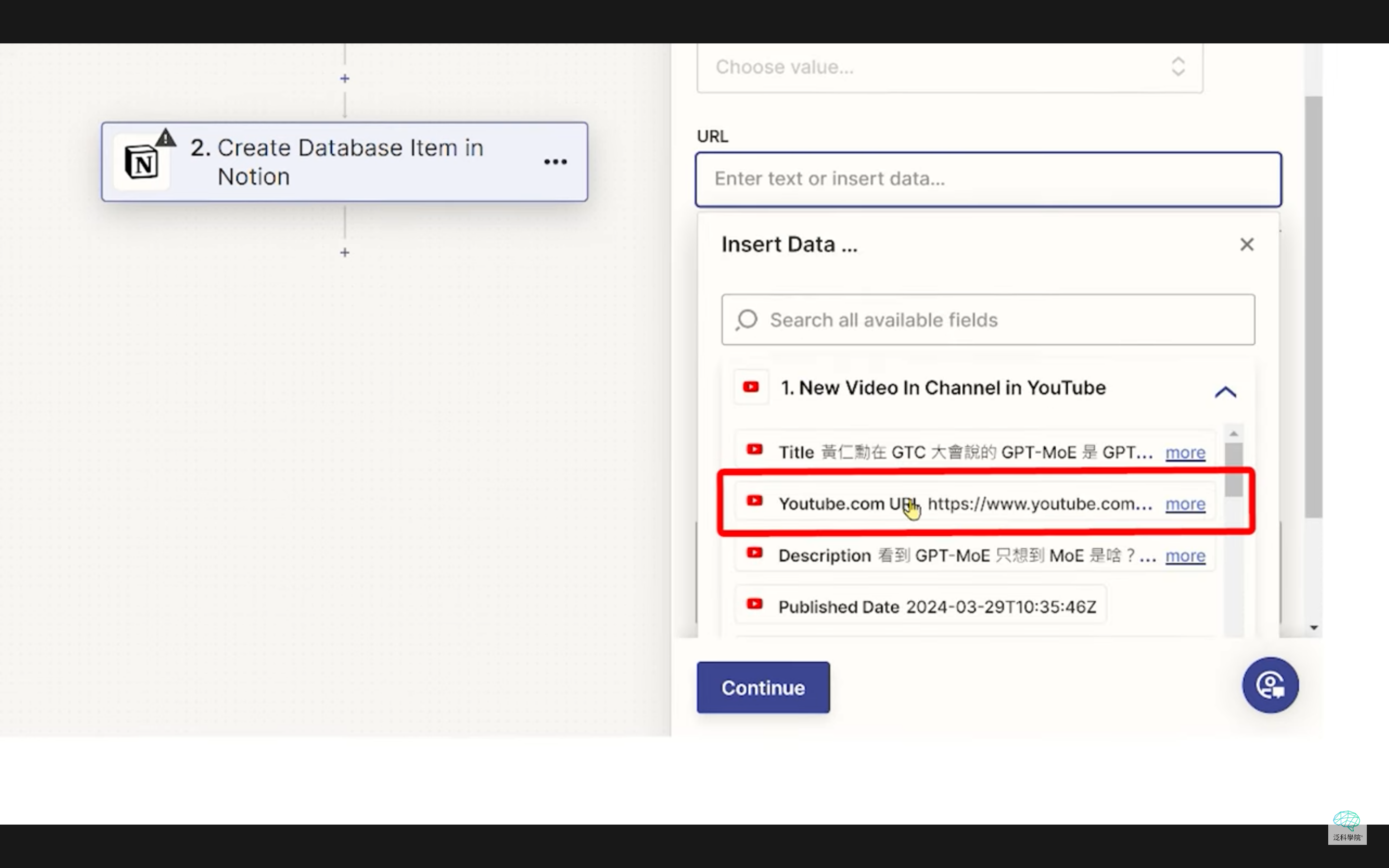
翻譯完畢之後就可以匯出 SRT 字幕
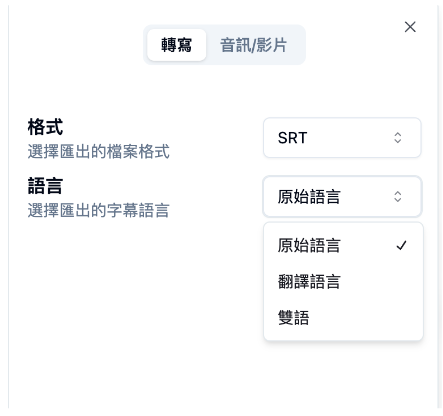
如果你本身是影片創作者,這招就可以輕鬆製作你的 SRT 字幕,再也不用花時間對字幕時間軸了。
或者你要把影片字幕直接內嵌在做簡報的時候播放影片:
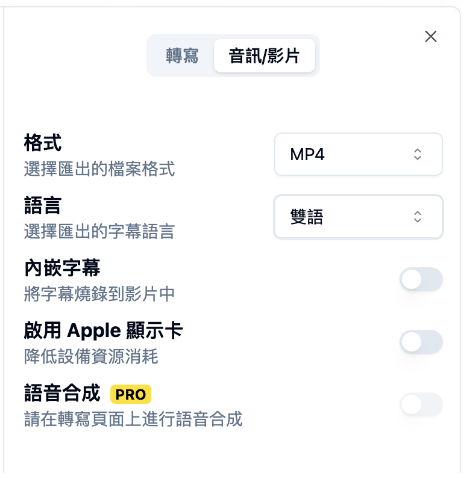
匯出 MP4 格式,語言選雙語。如果你還沒用過這招處理影片,我強烈建議你一定要試試看!
Ollama + Enchanted
接下來我們要分享另一套非常實用的工具——Enchanted。他也是開源,可以讓原本是文字介面的 Ollama
提供類似 ChatGPT 的對話視窗,甚至支援圖片辨識的多模態模型 llava,Mac 用戶可以直接去 App Store 免費安裝。
同時開啟 Ollama 跟 Enchanted LLM:
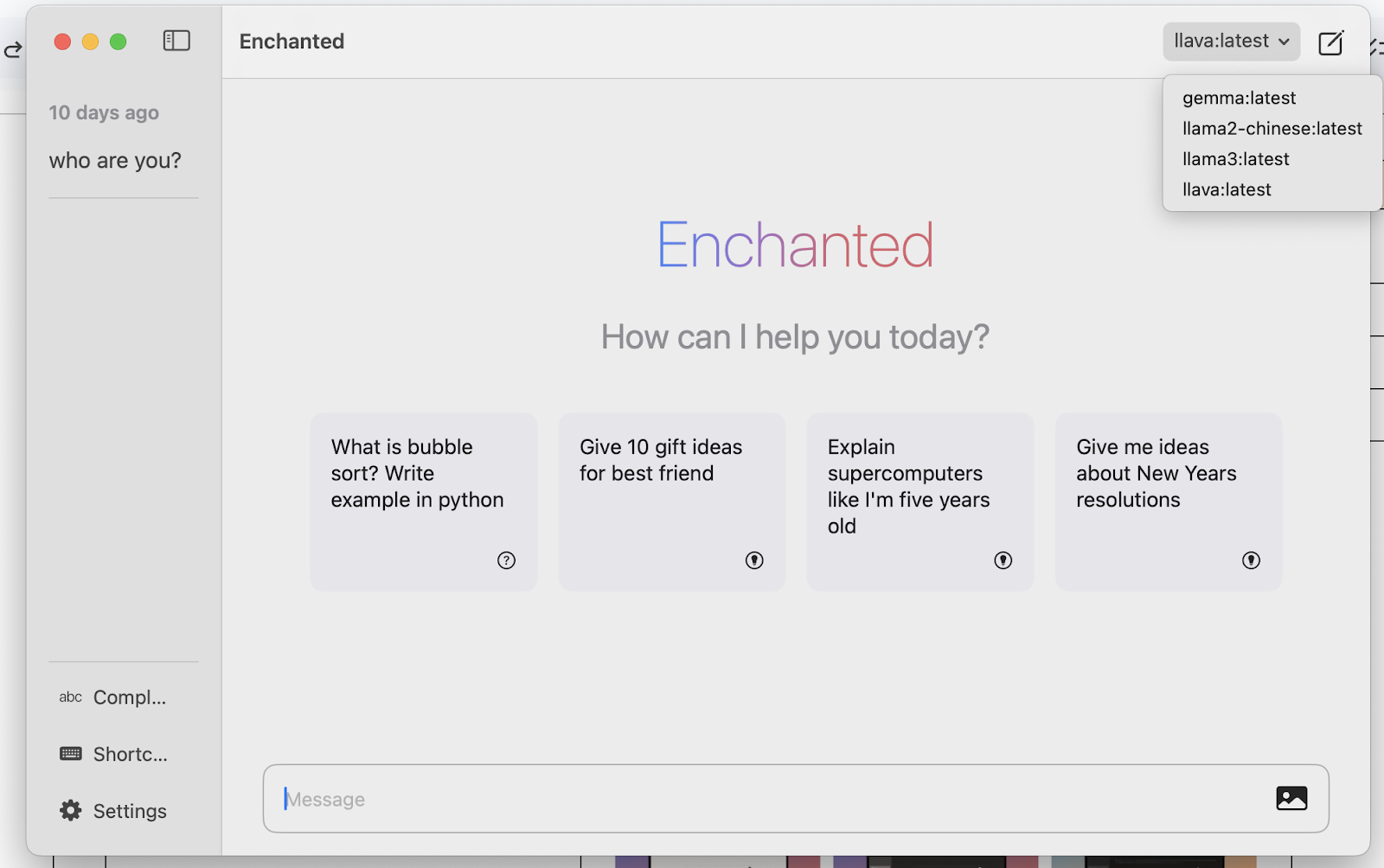
就擁有一個漂亮的視窗介面,可以優雅的啟用各種想要測試的 AI 模型,他甚至有手機版 APP!用手機連線自己的蘋果電腦跑 AI 模型?這……這,真的可以免費用嗎?
讓我來試試看!
首先要先安裝 ngrok 這套程式,選擇自己的作業系統然後下載。Windows 用戶應該直接安裝就可以了,Mac 的用戶在終端機執行這行 Sudo 指令把程式解壓縮到 user local bin 資料夾,接著註冊一個免費的 ngrok 帳號。
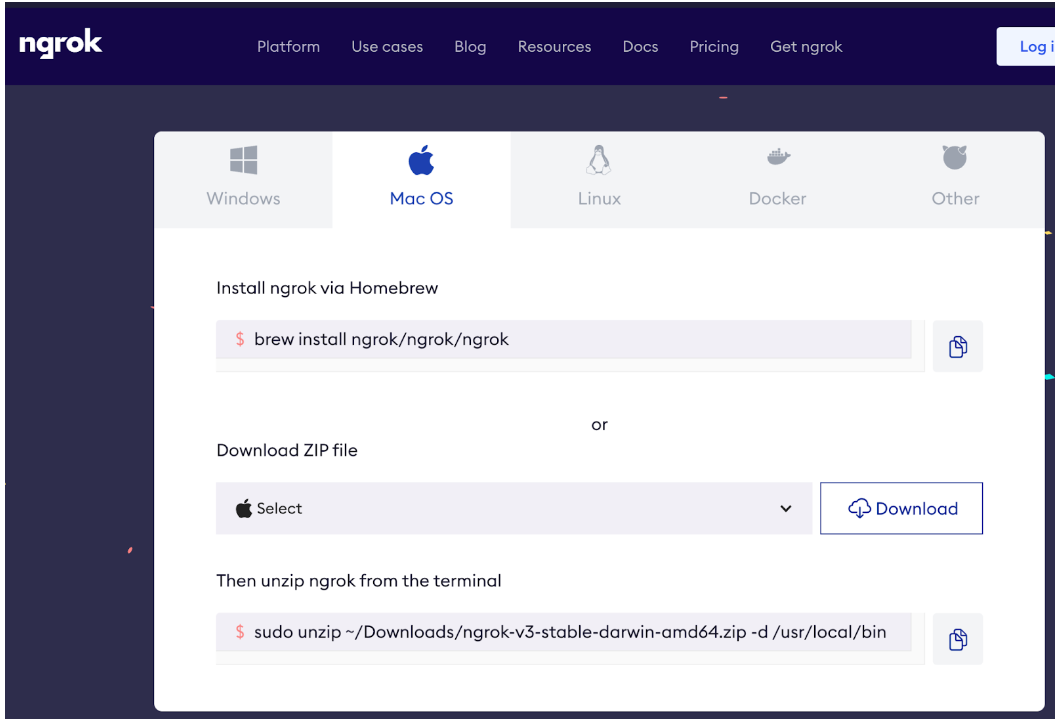
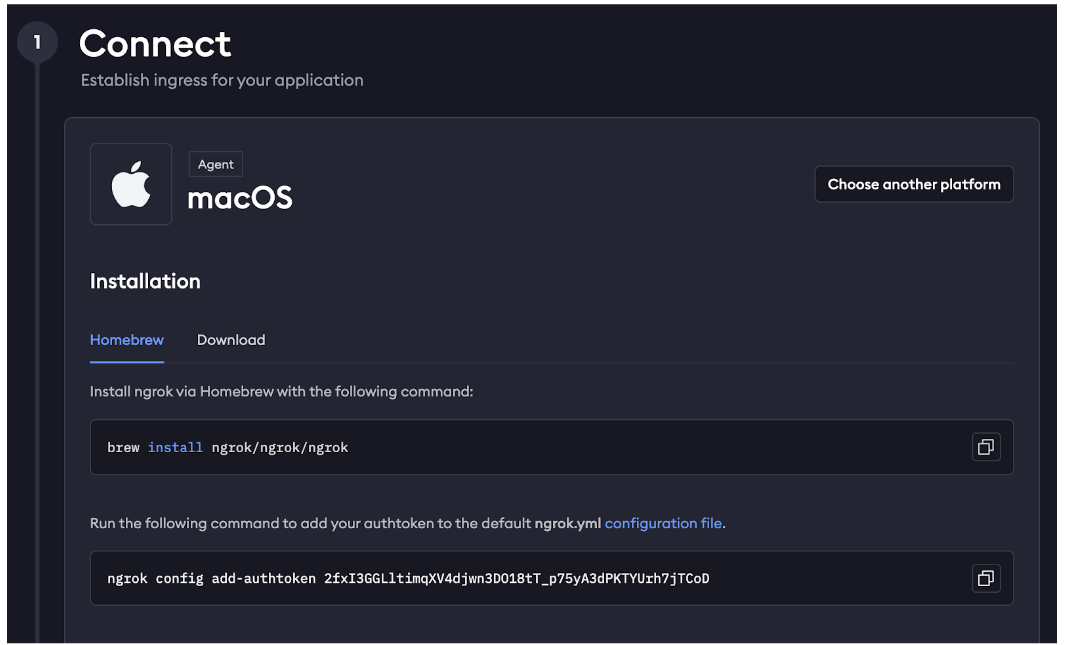
複製 ngrok config 指令,貼回自己電腦的終端機,把連線金鑰寫入自己的電腦。
最後一步,啟動連線,指令是:ngrok http 11434 –host-header=”localhost:11434″
一切順利的話就會看到類似這個畫面。
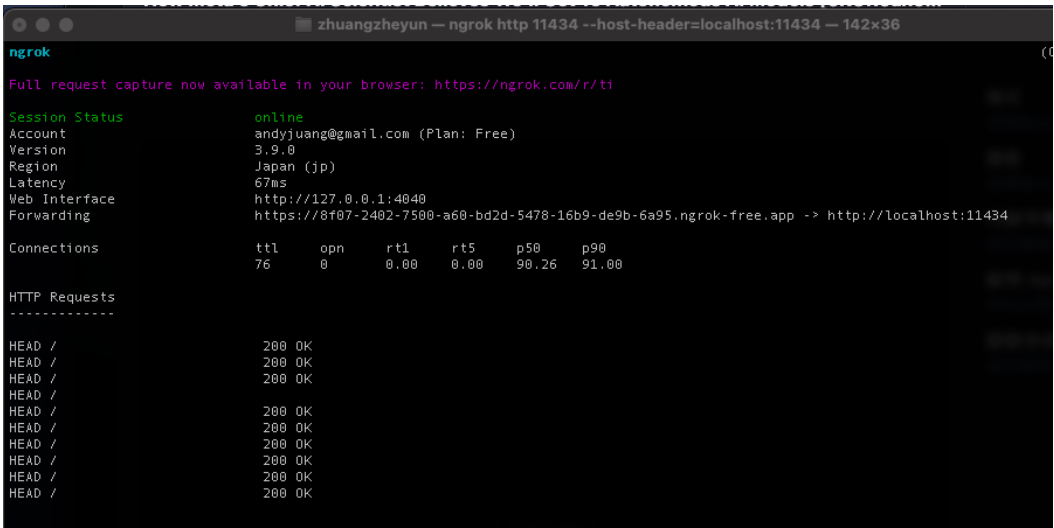
然後把 forwarding 的網址複製,打開 iPhone 或 iPad 的 Enchanted app,在設定 Setting 裡面把 Ollama 網址貼上,這樣就可以遠端調用電腦的 Ollama 來使用 AI 模型,比如選用稍早下載的 LLava 多模態模型。
傳一張照片,問它這是什麼?
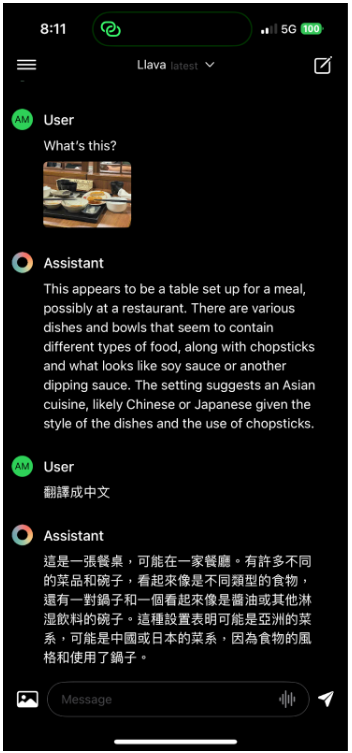
是不是非常神奇呢?
快練習把 ollama、ngrok 跟 Enchanted 串起來跟朋友炫耀吧!
總結
今天的影片跟各位分享了基於 Ollama 這個開源 AI 套件的各種有趣應用,你是否有成功在 iphone 上打造自己的 AI 服務呢?
- 太複雜了我決定躺平
- 笑話,我可是尊榮的 GPT Plus 用戶
- 沒有 Mac 電腦不能玩……嗚嗚嗚
- 你怎麼不介紹那個 ooxx Ollama 套件
如果有其他想看的 AI 工具測試或相關問題,也可以留言告訴我們~
更多、更完整的內容,歡迎上泛科學院的 youtube 頻道觀看完整影片,並開啟訂閱獲得