文/郭長祐

談及「自駕車」,或許會有人天真地認為,行車電腦只要運用前後保險桿上的超音波測距器(俗稱倒車雷達)來偵測前後車距離,以此來調控車速,以及用類似技術使汽車保持在車道內行駛不偏離,以及能在避障情況下完成改變車道、轉彎、停車等動作,就是完滿的自駕技術與程序。事實上,實現自駕車的技術與考驗遠大過於此。
難解的電車難題
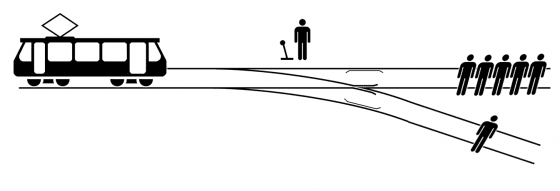
或許上述的例子過於特殊,實務上很難遇到,但確實點出自駕車實際上路,必然要面對複雜多變的情境。又如一個小女生為了追一個皮球而跑到馬路上,這時若不改變方向女孩將被車輾過,右轉則會撞向其他路人,左轉有可能就撞上水泥牆,車內乘客也會受傷,或者是一隻狗跑到馬路上,或前方貨車的油桶鬆綁滾到馬路上,這些情境自駕車都必須事先備妥研判能力,事發時才能正確快速因應,例如爆胎時只能讓汽車放開油門,緩緩向前到耗盡慣性而停止,若這時嘗試踩煞車或轉動方向盤,反而可能招致全車翻滾的危險。
科學家、工程師努力卸除社會對自駕車上路的心防
即便自駕車具有克服各種車況、情境的能力,自駕車上路依然有其他層面的挑戰,其中社會接納度至為關鍵。根據調查,有 78% 的受訪者表示不敢搭乘自駕車,以及有 41% 的汽車駕駛不願意跟自駕車一同上路,深怕自駕車出狀況殃及他們。
關於此,自駕車業者與研發團隊必須付出更多努力、甚至更有創意的做法才能使社會接受。過去百事可樂曾有一個蒙眼試驗廣告,邀請一群人蒙上眼睛後試喝兩種可樂,實驗證明單憑口感很難精準分辨可口可樂與百事可樂,表示消費者認為先出現的可口可樂口味更佳是種迷思,進而使百事可樂的銷售大增。
根據相似的心理學,或許在自駕車技術成熟後,可以安排實驗證實一般人無法分辨自駕車與人工駕駛的行為;甚至安排一個逼真的假駕駛,悄然在路上行駛一段時間後再告知大眾,以展現自駕車與一般駕駛幾無差別,或許可以說服社會大眾卸除部分心防與多慮。

當然,除了心理層面外,實質上也要讓自駕車的互動更逼近人為駕駛,例如變換車道會打方向燈,前車過近會按喇叭,對向來車有危險行為時,會讓大燈遠近交替切換作為警示。其他如砂石車經過會刻意保持較遠距離避免意外,同時當關上車窗,因為很多高速行駛的砂石車常有砂石掉落,高速下噴濺起的砂石有時會傷到車內的乘客,或者前方有大型車輛時當把車內空調改成封閉循環,避免吸到大車排出的廢氣,維持車內空氣品質,保障乘客健康。做到這些,人們才能逐漸接納自駕車。
另外,人們也擔心行車電腦是否會被駭客入侵並操控,輕則癱瘓交通重則犯罪,畢竟真人是不會被駭的,但電腦會。這一樣有待人工智慧科學家、工程師的努力,才能讓社會大眾接受與肯定自駕車的上路安全性。
目前自駕車的發展還是有些卡關的地方?
談及自駕車面臨的挑戰,除了需要提升緊急狀況的因應能力以及社會觀感外,自駕車的自駕基本功也有待磨練。美國汽車工程師學會(Society of Automotive Engineers,簡稱 SAE)把自駕程度分成六級:
零級(level 0):完全人為操作。
第一級(level 1):某些自動化功能可單獨作用,例如定速巡航,駕駛設定好想要的車速後腳就可以放開油門,讓汽車自動以定速操控油門;
第二級(level 2):多個自動化功能同時作用,但仍需要駕駛關注,必要時仍需要人為介入,例如自動停車;
第三級(level 3):汽車幾乎可全程自主駕駛,必要時才有人為介入;
第四級(level 4):完全不用人為介入,但僅限高速公路或車輛較少時才能如此;
第五級(level 5):一切自動,堪稱終極的自駕。
目前車廠已可達三級水準,若干宣稱達四級,但尚無人宣示已實現第五級,僅有晶片商宣稱已推出可滿足第五級自駕車所需運算力的車用電腦系統。
上述為行車電腦自主駕駛的程度,但人們關切的自駕車安全程度則仍待商確。目前業界確實有一些初步討論,有科學家發表論文,期望用數學公式(Shai Shalev-Shwartz et. al, 2017 )來釐清自駕車碰撞事故的責任歸屬,不過論文發表後有許多爭議與質疑聲浪 ,可能還需要一段時間發展。

另外政府也必須針對自駕車上路而增訂、修訂法規,目前世界各國政府都在拉高車輛安全要求,過去已要求汽車一定要有霧燈與前座安全氣囊才能出廠,現在也開始要求輪胎一定要安裝胎壓感測監督系統(Tire Pressure Monitoring System,簡稱 TPMS)才能出廠,進一步要求一定要配置防翻滾系統等,自駕車也當比照辦理。
有了自駕車,世界可能會很不一樣
談及自駕車,難道所設想的都是例外狀況與災禍嗎?答案應該為否,除弊之外自然也有興利的部分。自駕車若真能實現,也可能帶來更多的美好與便利。未來自駕車預先檢視全程路況,並對進行最佳化路程規劃,自動避開車潮,反而比人為習慣駕駛、記憶駕駛更快到目的地,甚更省行車能源,甚因行車操控更佳使零件更長壽而降低保修次數與花費,或因更佳、更可預設的行車狀況而降低車險費用。
就社會層面的考量,自駕車絕對不可能違反交通規則如超速或闖紅燈,自然可以省下讓交通警察舉發開單的社會成本;甚至更完善的大型自駕車系統可以調節車流分配,從而降低交通顛峰時間的塞車情況,節省龐大的時間成本。

進一步的,若自駕車夠普及,其實可以實現共享自駕車的願景,如同現在路上有 O-bike 就可以騎,只要針對使用的路程付費即可。而完全自主駕駛後,車內座位也可以完全打通,成為行動辦公室,或在車內共桌用餐、玩牌等,都有機會實現。在愛心傘夠多的情況下,就不再需要自己買傘,同理,到處都有車可搭,還有人要買私家車嗎?而免去私家車自然也就減少了相關的成本,包括每台車閒置時的成本、私人停車場的土地空間、甚至高額的停車費支出等。
最後,各位想像的自駕車未來又是怎樣呢?還有哪些挑戰呢?也請各位不吝與我們分享!
參考資料:
- Shalev-Shwartz, S., Shammah, S., & Shashua, A. (2017). On a Formal Model of Safe and Scalable Self-driving Cars. arXiv preprint arXiv:1708.06374.
《做車的人》系列內容由裕隆集團委託,泛科學企劃執行