


- 作者/開
人工智慧棋手 AlphaGo 先後戰勝了兩位頂尖圍棋高手李世乭和柯潔。在這場猛烈風暴席捲了世界後,AlphaGo 宣布不再和人下棋。但它的製造者並没有因此停下腳步,AlphaGo 還在成長,今天 Deepmind 又在《自然》期刊上發表了關於 AlphaGo 的新論文。

這篇論文中的 AlphaGo 是全新的、它不是戰勝柯潔的那個最强的 Master,但卻是它的孿生兄弟。它的名字叫 AlphaGo Zero,是AlphaGo 的最新版本。
和以前的 AlphaGo 相比,它:
- 從零開始學習,不需要任何人類的經驗
- 使用更少的算力得到了更好的结果
- 發現了新的圍棋定式
- 將策略網路和值網路合併
- 使用了深度殘差網路
- 白板理論(Tabula rasa)
哲學上有種觀點認為,嬰兒生下來是白板一塊,通過不斷訓練、成長獲得知識和智力。
作為 AI 領域的先驅,圖靈使用了這個想法。在提出了著名的「圖靈測試」的論文中,他從嬰兒是一塊白板出發,認為只要能用機器製造一個類似小孩的 AI,然後加以訓練,就能得到一個近似成人智力,甚至超越人類智力的 AI。
現代科學了解到的事實並不是這樣,嬰兒生下來就有先天的一些能力,他們偏愛高熱量的食物,餓了就會哭鬧希望得到注意。這是 DNA 在億萬年的演化中學来的。
監督和無監督學習
計算機則完全不同,它沒有億萬年的演化,因此也没有這些先天的知識,是真正的「白板一塊」。監督學習和無監督學習(Supervised & Unsupervised Learning)是鏡子的兩面,兩者都想解决同一個問題——如何讓機器從零開始獲得智慧?
監督學習認為人要把自己的經驗教给機器。拿分辨猫猫和狗狗的 AI 來說,你需要準備幾千張照片,然後手把手教機器——哪張照片是猫,哪張照片是狗。機器會從中學習到分辨猫狗的细節,從毛髮到眼睛到耳朵,然後舉一反三得去判斷一張它從沒見過的照片是猫猫還是狗狗。
而無監督學習認為機器要去自己摸索,自己發現規律。人的經驗或許能幫助機器掌握智慧,但或許人的經驗是有缺陷的,不如讓機器自己發現新的,更好的規律。人的經驗就放一邊吧。

從無知到無敵
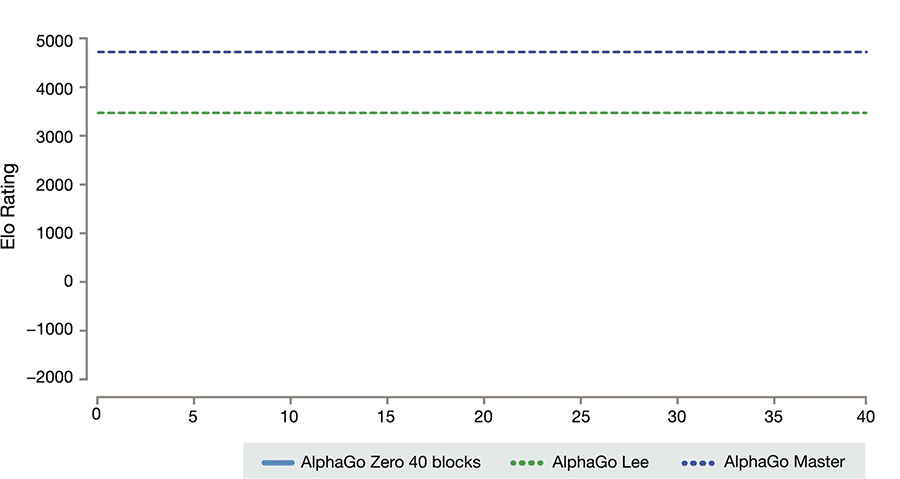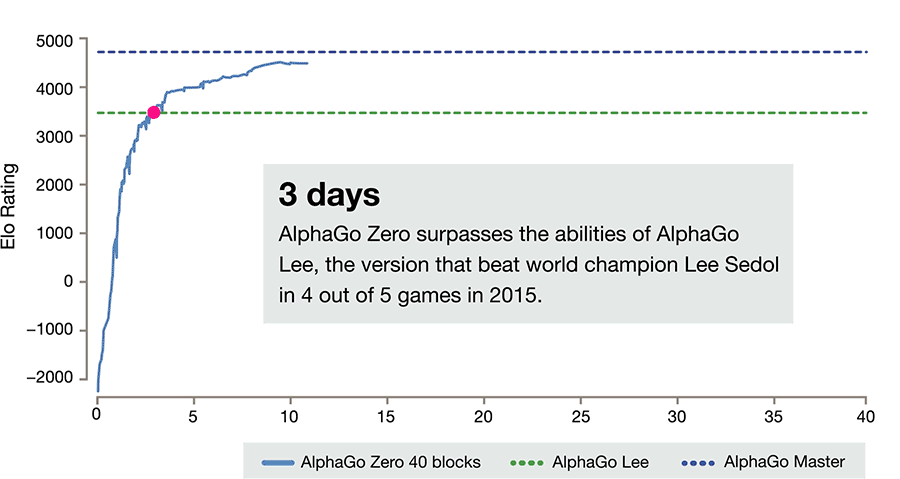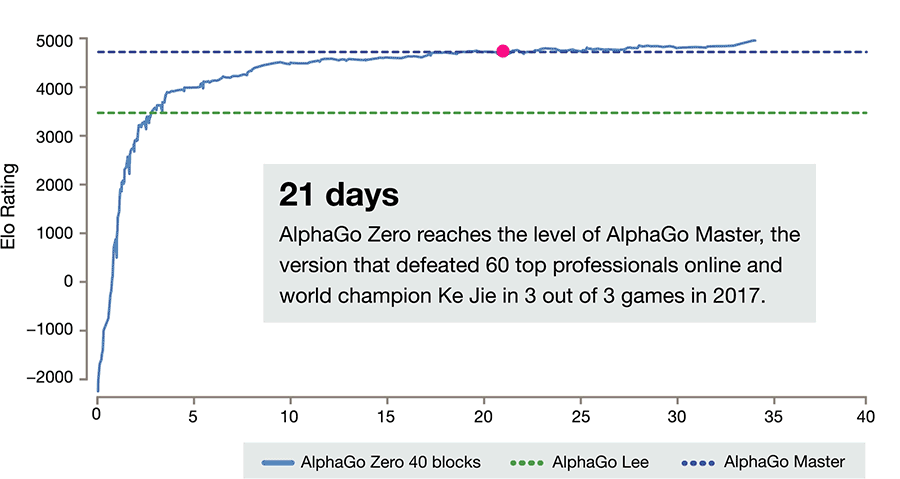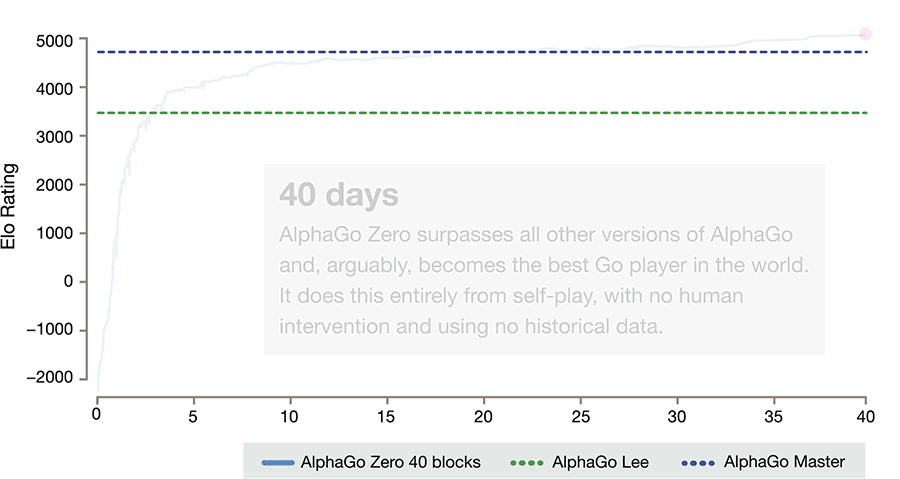
就像這篇新論文中講述的那樣。AlphaGo Zero 是無監督學習的產物,而它的雙胞胎兄弟 Master 則用了監督學習的方法。在訓練了 72 小時後 AlphaGo Zero 就能打敗戰勝李世乭的 AlphaGo Lee,相比較 AlphaGo Lee 訓練了幾個月。而 40 天後,它能以 89:11 的成積,將戰勝了所有人類高手的 Master 甩在後面。
圖靈的白板假設雖然無法用在人身上,但是 AlphaGo Zero 證明了,一個白板 AI 能夠被訓練成超越人類的圍棋高手。
强化學習
强化學習(Reinforcement Learning)是一種模仿人類學習方式的模型,它的基本方法是:要是機器得到了好的结果就能得到獎勵,要是得到差的结果就得到懲罰。AlphaGo Zero 並没有像之前的兄弟姐妹一樣被教育了人類的圍棋知識。它只是和不同版本的自己下棋,然後用勝者的思路来訓練新的版本,如此不斷重複。
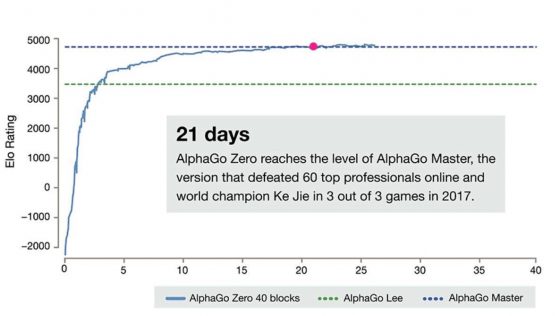
通過這一方法,AlphaGo Zero 完全自己摸索出了開局,收官,定式等以前人類已知的圍棋知識,也摸索出了新的定势。
算法和性能
如何高效合理得利用計算資源?這是算法要解决的一個重要問题。AlphaGo Lee 使用了 48 個 TPU,更早版本的 AlphaGo Fan 使用了 176 個 GPU,而 Master 和 AlphaGo Zero 僅僅用了 4 個 TPU,也就是說一台電腦足夠!
AlphaGo Zero 在 72小時内就能超越 AlphaGo Lee 也表明,優秀的算法不僅僅能降低能耗,也能極大提高效率。另外這也說明,圍棋問題的複雜度並不需要動用大規模的計算能力,那只是浪費。
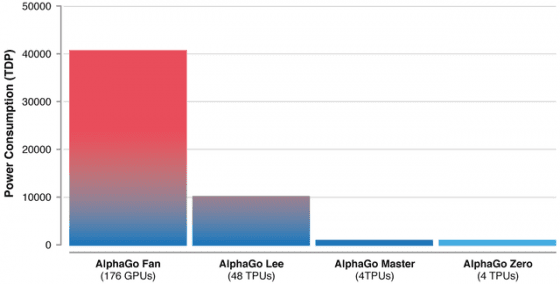
憑借硬件性能的不斷升级和算法的不斷優化,AlphaGo 後期版本的運算效率明顯優於最初的版本,圖/by DeepMind。
AlphaGo Zero 的算法有兩處核心優化:將策略網路(計算下子的概率)和值網路(計算勝率)這兩個神經網路结合,其實在第一篇 AlphaGo 的論文中,這兩種網路已經使用了類似的架構。另外,引入了深度殘差網路(DeepResidual Network),比起之前的多層神經網路效果更好。
Deepmind 的歷程

這不是 Deepmind 第一次在《自然》期刊上投稿,他們還發表過《利用深度神經網路和搜索樹的圍棋 AI》和《AI 電腦遊戲大師》等幾篇論文。
我們可以從中一窺 Deepmind 的思路,他們尋找人類還没有理解原理的遊戲,遊戲比起現實世界的問題要簡單很多。然後他們選擇了兩條路,一條道路是優化算法,另外一條道路是讓機器不受人類先入為主經驗的影響。
這兩條路交匯的终點,是那個超人的 AI。

結語
這是 AlphaGo 的终曲,也是一個全新的開始,相關技術將被用於造福人類,幫助科學家認識蛋白質折疊,製造出治療疑難雜症的藥物,開發新材料,以製造以出更好的產品。(編輯:明天)
本文版權屬於果殼網(微信公眾號:Guokr42),原文為〈從零開始,全憑自學,它用 40 天完虐 AlphaGo!〉,禁止轉載。如有需要,請聯繫sns@guokr.com。









































{kind=link}
{kind=link}
{kind=link}
{kind=link}