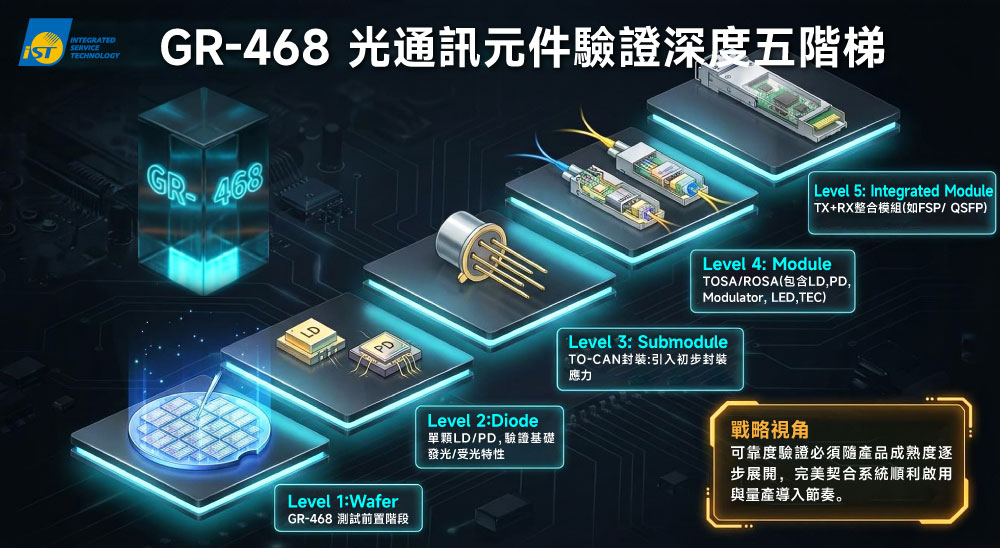
英國研究人員發現,藉由逐層堆疊石墨烯(graphene)之類的二維(2D)材料,有可能打造出具完美電子結構的三維(3D)新穎材料。此意想不到的研究結果有助於製作精密複雜的 3D 晶片結構,用來發展更快的資訊處理以及更大容量的資料儲存設備。
由諾貝爾獎得主 Andre Geim 與 Kostya Novoselov 領導的曼徹斯特大學團隊先將以膠帶法剝下的 2D 石墨烯層堆疊起來以,接著在石墨烯層間插入原子級薄的六方氮化硼(hexagonalboron nitride, hBN)晶體,並接上金屬電極以供後續電性量測。研究人員測量電子傳輸性質來檢驗其結構,並將效能表現最佳的區域以聚焦離子束(focused ion beam)切割分離出來,最後以高解析掃瞄穿透式電子顯微(TEM)鏡觀察每一層石墨烯在元件中的位置。
圖片來源:nanotechweb.org
團隊成員 Sarah Haigh 表示,TEM 影像顯示團隊已組裝出具有界線鮮明的原子級介面的新穎 3D 異質結構。更重要的是,他們發現雜質等污染物會分離形成孤立區塊。雜質粒子總是出現於 2D 晶體的上方,並且會在組裝 3D 結構時侷限於夾層之間。Haigh 解釋,這些吸附物不只會降低元件的電子性質,同時也意味著此人造層狀晶體無法僅藉由凡得瓦力形成,而是由各層間的吸附物扮演黏著劑的角色。污染雜質聚集成孤立區塊反而使內部介面乾淨無暇並且有原子級的平坦度,因此具有優良的電子性質。
Haigh 表示,透過此方式以 2D 材料製作 3D 結構,意味著他們能創造出具特定設計性質的電子元件。傳統的電子晶片主要受限於 2D 幾何結構,而此新穎結構將可望用來製作精密複雜的 3D 晶片架構。應用範圍包含更快速的資料處理以及更大的儲存容量。該團隊目前計畫探討更為複雜的層狀結構,以期能瞭解不同組成如何影響石墨烯元件的電子、熱學以及機械性質。詳見 Nature Materials |DOI:10.1038/nmat3386。
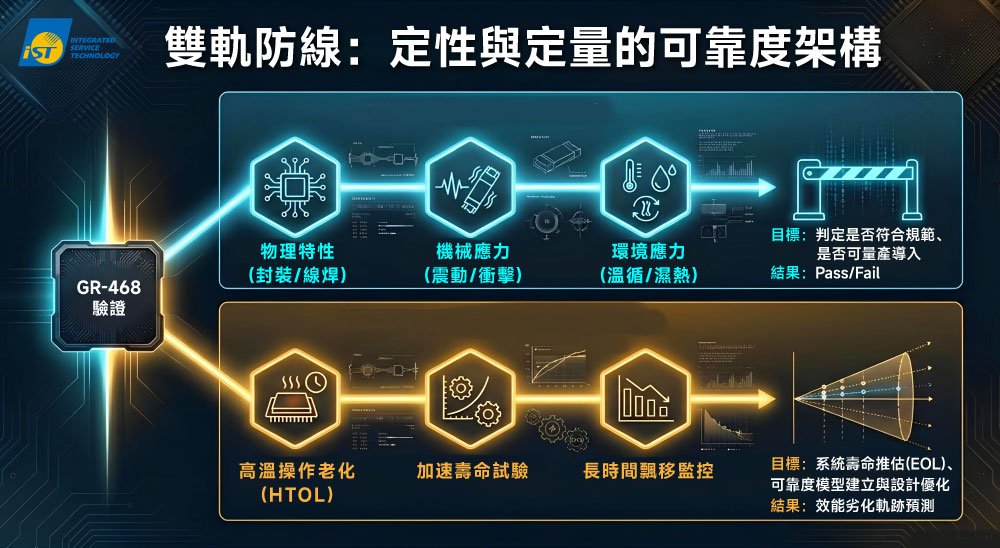
例如,應用於資料中心機房的設備,長期處於溫控環境,溫度與濕度波動小,應力條件相對溫和,驗證重點在於長時間的穩定運作。而隨著 AI 應用場域的擴張,例如:馬斯克計畫將 AI 運算中心送入外太空,若設備處於戶外或無空調環境(Uncontrolled Environment, UNC),將面臨劇烈的溫度波動、濕熱與高環境應力,極端溫差將嚴苛考驗封裝材質與光學對位的穩定度。