今年蘋果 WWDC 大會上發表的 Vision Pro,在市場上引起軒然大波。除此之外,蘋果新推出的 Mac Pro、Mac Studio 也都十分吸睛
,他們的共同特點,就是我都買不起。他們的共同的特點,就是裏頭都搭載了 M 系列晶片。從 M2、M2 Max 到 M2 Ultra,除了強大的效能,其輕巧的設計,也讓這些裝置保持輕量。Vision Pro 的重量也可以維持維持在500g,不影響穿戴體驗。要在如此小的晶片中發揮跟電腦一樣效能,除了我們介紹過的 DUV 與 EUV 微縮顯影,一路從 7 奈米、5 奈米、3 奈米向下追尋外。在 M 系列這種系統晶片中,「先進封裝」技術,其實扮演更重要的角色,但到底「封裝」是什麼?它如何幫助 M2 達到高效能、小體積的成果?
晶片又更小了,摩爾定律依舊存在?
M2 晶片的效能已被消費者認可,一顆小小的晶片中,就同時包含了 8 核心 CPU、10 核心 GPU、16 核心的神經網路晶片以及記憶體,麻雀雖小,五臟俱全。這可說又是摩爾定律向前邁進的一步。

今年 3 月 24 日,Intel 共同創辦人戈登.摩爾,逝世於夏威夷的家中,享耆壽 94 歲。他生前提出的摩爾定律,在引領半導體產業發展近 60 年之後,也逐漸走向極限。摩爾定律預測,積體電路上的電晶體數目,在相同面積下,每隔約 18 個月數量就會增加一倍,晶片效能也會持續提升。
隨著晶片尺寸越來越小,似乎小到無法再小,「摩爾定律已死」的聲音越來越大。然而事實是,業界的領頭羊們如台積電、英特爾和三星等公司,依然認為摩爾定律可以延續下去,並且仍積極投入大量金錢、人力及資源,期盼能夠打贏這場奈米尺度的晶片戰爭。
打贏戰爭的方法,包含研發各式各樣的電晶體,例如鰭式場效電晶體(FinFET)、環繞式閘極(GAAFET)電晶體及互補式場效電晶體(CFET);或是大手筆引進艾司摩爾開發的極紫外光(EUV)曝光機,在微縮顯影上做突破,這部分可以回去複習我們的這一集;除此之外,從材料下手也同步進行中,新興的半導體材料,像是過渡金屬二硫族化合物或奈米碳管。這些持續挑戰物理極限的方式稱為「深度摩爾定律(More Moore)」。
然而這條路可不是康莊大道,而是佈滿了荊棘,或是亂丟的樂高積木,先進製程開發的複雜度和投入資金呈指數型增加,且投資與回報往往不成正比。我們都知道「不要把雞蛋都放在同一個籃子裡」,同理,半導體巨擘們也開始找尋新解方,思索如何躺平,在不用縮小電晶體的情況下,提升晶片整體效能。

答案也並不難,既然在平面空間放不下更多電晶體了,那麼就把他們疊起來吧!如此一來,相同面積上的電晶體數量也等效的增加了。這就像是在城市裡,因為人口稠密而土地面積有限,因而公寓大廈林立,房子一棟蓋得比一棟高一樣。像這樣子不是以微縮電晶體,而是透過系統整合的方式,層層堆疊半導體電路以提升晶片效能的方法,屬於「超越摩爾定律(More than Moore)」,而其技術關鍵,就在於「封裝」。
什麼是封裝?
當一片矽晶圓經過了多重製程的加工後,我們會得到這張表面佈滿了成千上萬積體電路。別小看它,光是這一片的價值,可能就高達2萬美元!

然而這麼大片當然無法放進你的手機裡,還必須經過「封裝(packaging)」的步驟,才會搖身一變成為大家所熟知的半導體晶片。
簡單來說,封裝是一種技術,任務是把積體電路從晶圓上取下,放在載板上,讓積體電路可以與其他電路連接、交換訊號。整個封裝,大致可分為四步驟:切割、黏晶、打線、封膠。
首先,矽晶圓會被磨得更薄,並且切割成小塊,此時的積體電路稱為裸晶(die);接著,將裸晶黏貼於載板(substrate)上,並以焊線連接裸晶及載版的金屬接點,積體電路便可跟外界傳遞或接收訊號了;最後,以環氧樹酯灌模成型,就完成我們熟知的晶片(chip),這個步驟主要在於保護裸晶及焊線,同時隔絕濕氣及幫助散熱。
Chiplet、傳統封裝與先進封裝
隨著晶片不斷追求高效能、低成本,還要滿足不同的需求,甚至希望在一個晶片系統中,同時包含多個不同功能的積體電路。這些積體電路規格、大小都不一樣,甚至可能在不同工廠生產、使用不同製程節點或不同半導體基材製作。例如蘋果的 M2 晶片,就是同時包含 CPU、GPU 和記憶體,另外,我們過去介紹過,google 陣營的 Tensor 晶片,也是在單一晶片系統中塞入了大大小小的晶片。這些在一個晶片系統中含有多個晶片的架構,稱為 Chiplet。
要做出 Chiplet,在傳統的封裝方式中,會將初步封裝過的數個晶片再次進行整合,形成一個功能更完整的模組,稱為系統級封裝 Sip(system in package);另一個方法則是將數個裸晶透過單一載板相互連接完成封裝,這樣的作法叫做系統單晶片system on a chip (SoC),然而以這兩種方式製作需佔用較大的面積,更會因為晶片、裸晶間的金屬連線過長,造成資料傳輸延遲,不能達到高階晶片客戶如輝達、超微、蘋果等公司的需求。
為了解決問題,先進封裝就登場了,三維先進封裝以裸晶堆疊的方式,增加空間利用率並改善資料傳輸瓶頸的問題。與傳統封裝之間傳輸速度的差異,就好比是開車由台北至宜蘭,傳統封裝需行經九彎十八拐的台九線,而先進封裝則截彎取直,打通了連接兩地的雪山隧道,使得資料的來往變得更加便利且迅速。
先進封裝解決了什麼問題?
先進封裝最大的優勢,就是大幅縮短了不同裸晶間的金屬連導線距離,因此傳輸速度大為提升,也減少了傳輸過程中的功率損耗。舉例來說(下圖),傳統的 2D SoC,若是 A 電路要與 C 電路傳輸資料,則必須跨越整個系統的對角線距離;然而使用三維堆疊則能夠將 C 晶片放置於 A 晶片的上方,透過矽穿孔(through silicon via, TSV)技術貫穿減薄後的矽基板,以超高密度的垂直連導線連接兩個電路,兩者的距離從此由天涯變咫尺。
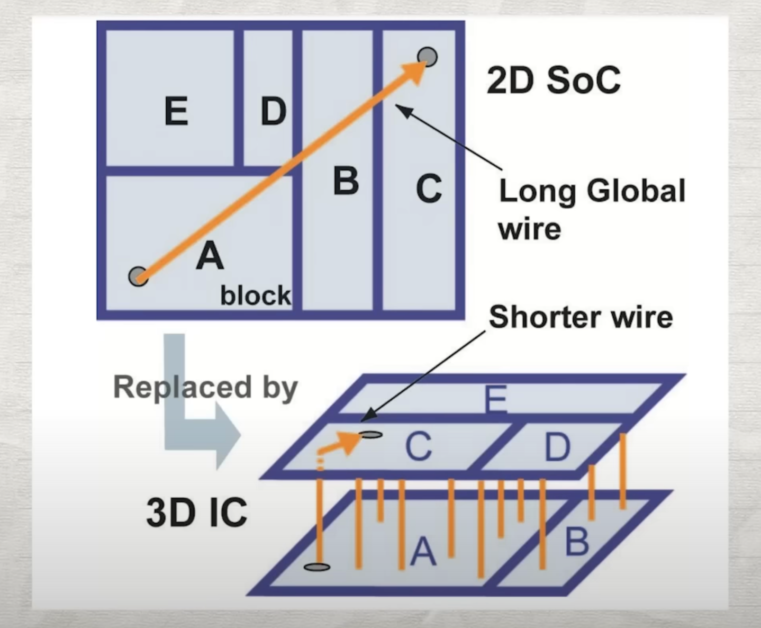
另一方面,三維堆疊也減少了面積的消耗,對於體積的增加則並不明顯,因此我們能夠期待,手機、平板、或是 Vision Pro 等頭顯未來除了功能更多以外,還會變得更加輕巧。
值得一提的是,先進封裝還能夠降低生產成本喔!由於三維堆疊在單位面積上,增加了等效電晶體數量,在晶片設計上可以考慮使用較成熟、成本更低的製程技術節點,並達到與使用單層先進技術節點並駕齊驅的效能。
先進封裝的技術挑戰
雖然,先進封裝提供了許多優勢。但作為新技術,當中依舊有許多仍待克服的問題與挑戰。
首先,先進封裝對於裸晶平整度以及晶片對準的要求很高,若是堆疊時不慎有接點沒有順利連接導通,就會造成良率的損失。再者,積體電路在運算時會產生能量損耗造成溫度升高,先進封裝拉近了裸晶間的距離,熱傳導會交互影響,大家互相取暖,造成散熱更加困難,輕則降低晶片效能,嚴重則能導致產品失效。
散熱問題在先進封裝中,目前還未完全解決,但可以透過熱學模擬、使用高熱導係數材料、或設計導熱結構等方式,做出最佳化的散熱設計。建立良率測試流程也非常重要,試想,如果在堆疊前沒有做好已知合格裸晶測試(known good die testing),因而誤將合格的 A 晶片與失效的 B 晶片接合,那麼不只是做出來的 3D IC 只能拿來當裝飾品,還白白損失了前面製程所花費的人力、物力及金錢!
良率與成本間的權衡,也是須探究的問題,如果想要保證最佳的良率,最好的方式是每道環節都進行測試,然而這麼做的話生產成本以及製造時間也會相應增加,因此要怎麼測試?在什麼時候測試?要做多少測試?就是一門相當深奧的學問了。
歡迎訂閱 Pansci Youtube 頻道 獲取更多深入淺出的科學知識!