本文由 Intel 委託,泛科學企劃執行。
在當今快節奏的數位時代,對於處理器性能的需求已經不再僅僅停留在日常應用上。從遊戲到學術,從設計到內容創作,各行各業都需要更快速、更高效的運算能力,而人工智慧(AI)的蓬勃發展更是推動了這一需求的急劇增長。在這樣的背景下,Intel 推出了一款極具潛力的處理器—— Intel® Core™ Ultra,該處理器不僅滿足了對於高性能的追求,更為使用者提供了運行 AI 模型的全新體驗。
先進製程:效能飛躍提升
現在的晶片已不是單純的 CPU 或是 GPU,而是混合在一起。為了延續摩爾定律,也就是讓相同面積的晶片每過 18 個月,效能就提升一倍的目標,整個半導體產業正朝兩個不同方向努力。
其中之一是追求更先進的技術,發展出更小奈米的製程節點,做出體積更小的電晶體。常見的方法包含:引進極紫外光 ( EUV ) 曝光機,來刻出更小的電晶體。又或是從材料結構下手,發展不同構造的電晶體,例如鰭式場效電晶體 ( FinFET )、環繞式閘極 ( GAAFET ) 電晶體及互補式場效電晶體 ( CFET ),讓電晶體可以更小、更快。這種持續挑戰物理極限的方式稱為深度摩爾定律——More Moore。
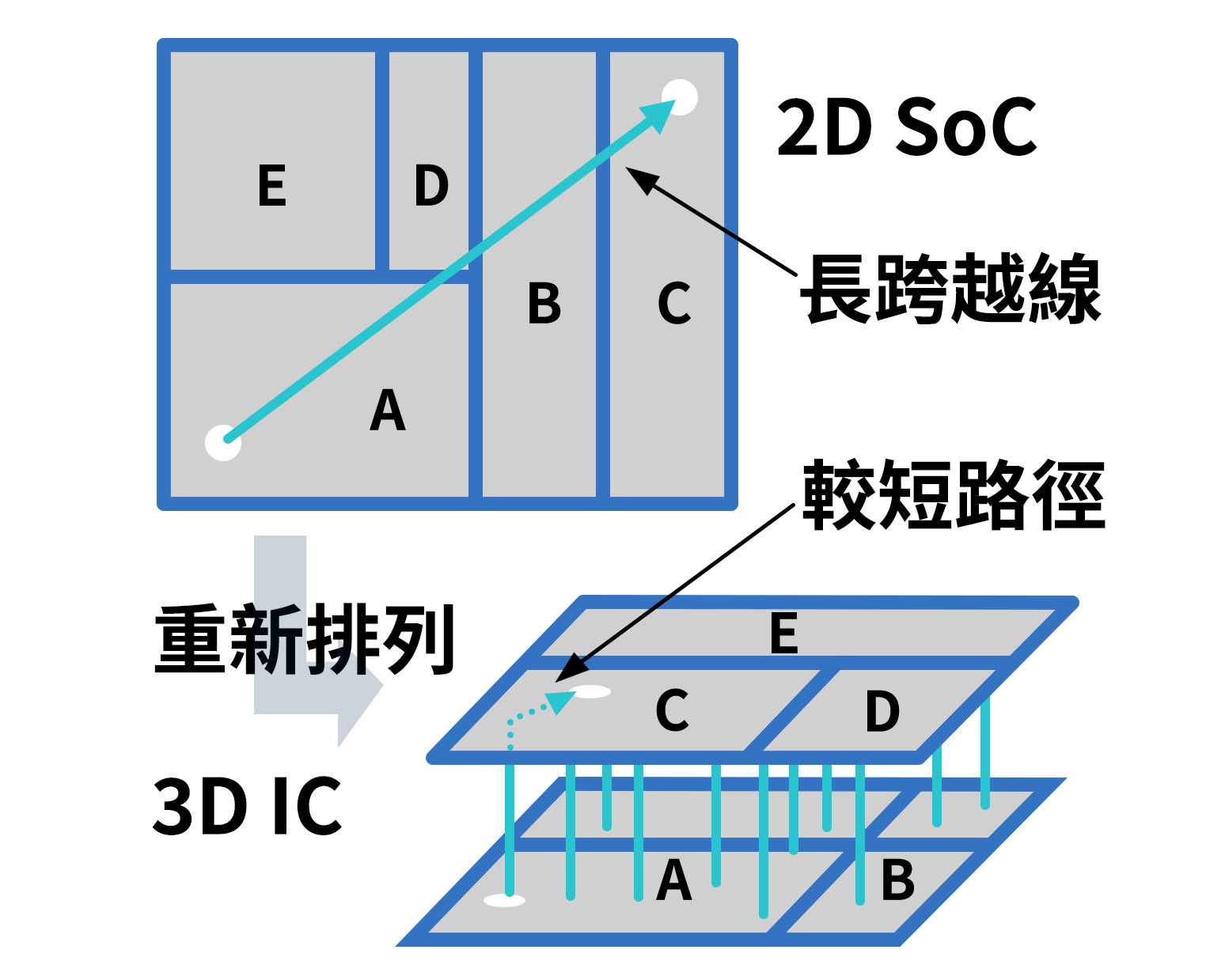
另一種則是將含有數億個電晶體的密集晶片重新排列。就像人口密集的都會區都逐漸轉向「垂直城市」的發展模式。對晶片來說,雖然每個電晶體的大小還是一樣大,但是重新排列以後,不僅單位面積上可以堆疊更多的半導體電路,還能縮短這些區塊間資訊傳遞的時間,提升晶片的效能。這種透過晶片設計提高效能的方法,則稱為超越摩爾定律——More than Moore。
而 Intel® Core™ Ultra 處理器便是具備兩者優點的結晶。
Tile 架構:釋放多核心潛能
在超越摩爾定律方面,Intel® Core™ Ultra 處理器以其獨特的 Tile 架構而聞名,將 CPU、GPU、以及 AI 加速器(NPU)等不同單元分開,使得這些單元可以根據需求靈活啟用、停用,從而提高了能源效率。這一設計使得處理器可以更好地應對多任務處理,從日常應用到專業任務,都能夠以更高效的方式運行。
CPU Tile 採用了 Intel 最新的 4 奈米製程和 EUV 曝光技術,將鰭式電晶體 FinFET 中的像是魚鰭般阻擋漏電流的鰭片構造減少至三片,降低延遲與功耗,使效能提升了 20%,讓使用者可以更加流暢地執行各種應用程序,提高工作效率。

Foveros 3D 封裝技術:高效數據傳輸
2017 年,Intel 開發出了新的封裝技術 EMIB 嵌入式多晶片互聯橋,這種封裝技術在各個 Tile 的裸晶之間,搭建了一座「矽橋 ( Silicon Bridge ) 」,達成晶片的橫向連接。

而 Foveros 3D 封裝技術是基於 EMIB 更進一步改良的封裝技術,它能將處理器、記憶體、IO 單元上下堆疊,垂直方向利用導線串聯,橫向則使用 EMIB 連接,提供高頻寬低延遲的數據傳輸。這種創新的封裝技術不僅使得處理器的整體尺寸更小,更提高了散熱效能,使得處理器可以長期高效運行。
運行 AI 模型的專用筆電——MSI Stealth 16 AI Studio
除了傳統的 CPU 和 GPU 之外,Intel® Core™ Ultra 處理器還整合了多種專用單元,專門用於在本機端高效運行 AI 模型。這使得使用者可以在不連接雲端的情況下,依然可以快速準確地運行各種複雜的 AI 算法,保護了數據隱私,同時節省了連接雲端算力的成本。
MSI 最新推出的筆電 Stealth 16 AI Studio ,搭載了最新的 Intel Core™ Ultra 9 處理器,是一款極具魅力的產品。不僅適合遊戲娛樂,其外觀設計結合了落質感外型與卓越效能,使得使用者在使用時能感受到高品質的工藝。鎂鋁合金質感的沉穩機身設計,僅重 1.99kg,厚度僅有 19.95mm,輕薄便攜,適合需要每天通勤的上班族,與在咖啡廳尋找靈感的創作者。
除了外觀設計之外, Stealth 16 AI Studio 也擁有出色的散熱性能。搭載了 Cooler Boost 5 強效散熱技術,能夠有效排除廢熱,保持長時間穩定高效能表現。良好的散熱表現不僅能夠確保處理器的效能得到充分發揮,還能幫助使用者在長時間使用下的保持舒適性和穩定性。
Stealth 16 AI Studio 的 Intel Core™ Ultra 處理器,其性能更是一大亮點。除了傳統的 CPU 和 GPU 之外,Intel Core™ Ultra 處理器還整合了多種專用單元,專門針對在本機端高效運行 AI 模型的需求。內建專為加速AI應用而設計的 NPU,更提供強大的效能表現,有助於提升效率並保持長時間的續航力。讓使用者可以在不連接雲端的情況下,依然可以快速準確地運行各種複雜的 AI 算法,保護了數據隱私,同時也節省了連接雲端算力的成本。
軟體方面,Intel 與眾多軟體開發商合作,針對 Intel 架構做了特別最佳化。與 Adobe 等軟體的合作使得使用者在處理影像、圖像等多媒體內容時,能夠以更高效的方式運行 AI 算法,大幅提高創作效率。獨家微星AI 智慧引擎能針對使用情境並自動調整硬體設定,以實現最佳效能表現。再加上獨家 AI Artist,更進一步提升使用者體驗,直接輕鬆生成豐富圖像,實現了更便捷的內容創作。
此外 Intel 也與眾多軟體開發商合作,針對 Intel 架構做了特別最佳化,讓 Intel® Core™ Ultra處理器將AI加速能力充分發揮。例如,與 Adobe 等軟體使得使用者可以在處理影像、圖像等多媒體內容時,能夠以更高效的方式運行 AI 算法,大幅提高創作效率。為各行專業人士提供了更加多元、便捷的工具,成為工作中的一大助力。