


台灣這幾天比較冷,但暖冬仍然是全球暖化過程中一個明顯的趨勢。一般以為全球暖化始於 19 世紀末葉先進國家積極工業化的時候,但世界各地工業化的進程不同,暖化的趨勢也會有所差異。當工業化在全球範圍內日益普及,各地暖化趨勢便益見明顯,但還要等到 20 世紀下半葉這趨勢才明顯到引起各國的注意。

在美國,一直要到 1988 年氣候變化才正式成為官方關切的議題。這一年的 6 月 23 日,NASA 太空研究所(GISS)主任 James E. Hansen 在參議院能源及自然資源委員會作證指出:「全球暖化的程度已經顯著到讓我們確信溫室效應與暖化趨勢具有因果關係。依我的意見,我們已經偵測出了溫室效應,而且這效應正在影響我們的氣候。」
以筆者居住的德州奧斯汀市而言,氣溫紀錄始於 19 世紀末期。我用統計學「改變點」(change point)的方法分析每年最高溫及最低溫的時間序列,檢測出年低溫最顯著的改變點在 Hansen 作證之後 3 年的 1991 年,而年高溫的改變點還要更後,在 1998 年。這與筆者個人體驗大致相符。
台北氣溫變化趨勢的改變點
「改變點」的檢測是時間序列分析的統計方法,它用來判定時間序列的資料產生過程是否有不連續點的存在。它在 1930 年代就曾被產業界用來監控產品的製造過程,其後經過數學家的深入研究,在近 20 年來蓬勃發展,廣泛被應用於環保、疫情、醫療、軍事、反恐等各領域。筆者個人就曾用類似的研究方法發現美國歷史上,選民的投票行為在二十世紀 20-30 年代之間曾經發生過質性的變化。去年五月,頂級學術期刊 Science 也有研究論文檢測新冠肺炎在德國傳播趨勢的改變點,肯定了政府干預措施的有效性。CBS 電視影集「數字」(Numb3rs)甚至有一集演出「夢幻棒球」玩家用改變點方法檢測大聯盟球員使用禁藥提高打擊率的故事。
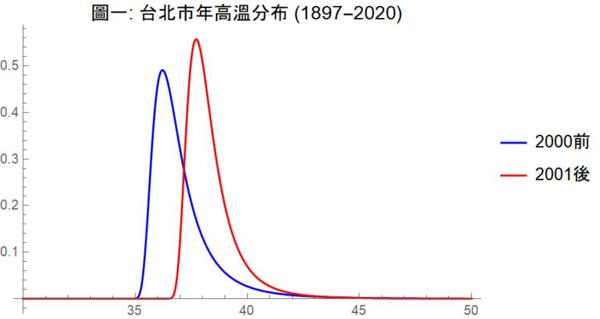
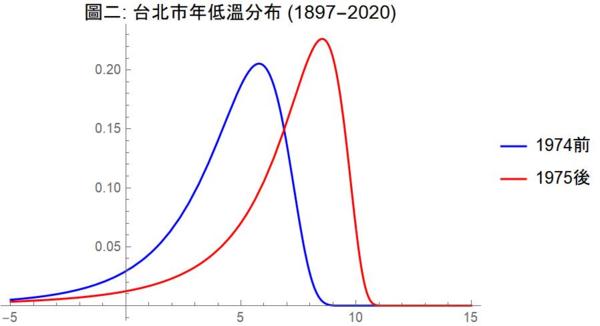
台灣的氣溫紀錄也始於 19 世紀末。根據 Jasmine Kuo 提供的台北市年低溫歷史資料,台北市每年最低溫的改變點在 1975 年,而年高溫的改變點則要到 2001 年。台北市年低溫的改變比奧斯汀要早,這也許跟地形、地理位置、人口、以及工業化程度有關。
理論上,年高溫及年低溫都不是常態分布,而是呈現所謂極端值分布(extreme value distribution)。圖一及圖二以上述改變點為斷點,分別估計年高溫及年低溫在各自改變點前、後的極端值分布。這兩張圖讓我們清楚看出改變點前後的明顯差異:改變點之後,年高溫及年低溫的分布均明顯往高溫方向移動。年高溫在 2001 之後的平均值增加了攝氏 1.44 度,而年低溫在 1975 之後的平均值則更誇張地增加了將近兩倍的 2.81 度!
時間序列資料產生過程的變化除了可以用改變點的統計方法來檢測斷點以外,也可以用 「紀錄」(record)發生的機率理論來分析異常現象。事實上,事件發生頻率的改變也是改變點研究的數學方法之一。本文以下即以紀錄理論進一步探討台北市年低溫在 1975 年之後新紀錄節節升高的現象。
破紀錄次數的機率分布,説明台北市年低溫變遷出現異常
台北市 1897-2020 年低溫時間序列顯示,1897 年台北市的最低溫是攝氏 5 度。以此為資料中的第一個紀錄,124 年來,有 9 個新的紀錄出現,分別是:1899(7.2度),1905(7.6度),1909(8.1度),1912(8.2度),1976(8.5度),1983(9.3度),1988(10度),2017(10.4度),2019(11.6度)。見圖三時間序列中的黑點。
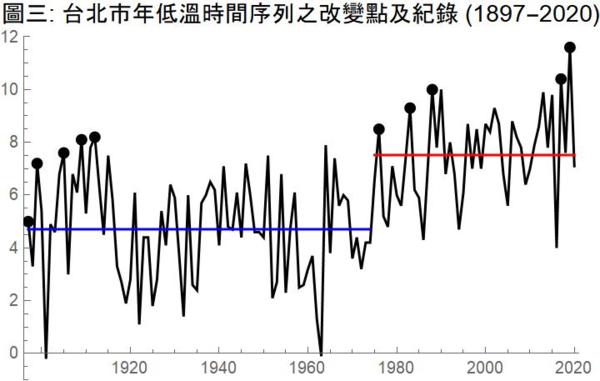
124 年間有 10 個紀錄是正常現象嗎?這個問題,可以用機率理論做精確的回答。
機率理論對「記錄」的研究有很完整的系統。其數學繁複,但相當有趣,有興趣的讀者可以找相關書籍來看,例如 Jiri Andel(2001)的 Mathematics of Chance。
這個理論從一個前提出發:觀察序列中的資料是遵循相同機率分布而且相互獨立(iid,編按:Independently and identically distributed)的隨機變數。在這個假設之下,我們可以導出在 n 個資料點中有 r 個紀錄(包括第一個資料點)的機率分布。這個前提可以說是「正常」狀況的「虛無假設」:它代表觀察序列中資料的產生過程完全相同,沒有任何異常現象或動態趨勢。如果我們的經驗資料與這個假設之下的機率分布不相諧,根據傳統次數主義(frequentist)統計推論的方法,我們可以在一定的統計水平之下拒絕虛無假設而判定異常現象的存在。
以台北市年低溫的歷史資料來說,我們可以算出在 n = 124 個觀察值的序列資料中出現 r (r = 1,2,3,…,124)個紀錄的機率分布,然後從這分布算出 r 大於或等於 10 的右尾機率。如果這個機率小於相約成俗的顯著水平 0.05,我們判定歷史資料與虛無假設不相諧,從而排除台北市年低溫變遷沒有異常現象的前提。依照傳統統計推論,我們可以做出台北市年低溫變遷有異常現象的結論。
以 Rn 代表在 iid 假設之下,n = 124 個序列資料中有 r 個紀錄的隨機變數,圖四便是 Rn = r 的機率分布。從這個機率分布我們可以算得 Rn 的期望值是 E ( Rn ) = 5.40,變異量是 Var ( Rn ) = 3.76,也很容易直接算得右尾機率 P (Rn ≥ 10) = 0.025。因為這個機率小於 0.05,單尾檢定讓我們得到台北市年低溫屢破歷史上限紀錄是異常現象的結論。(如果一定要用雙尾檢定,這個結論就有點勉強。)
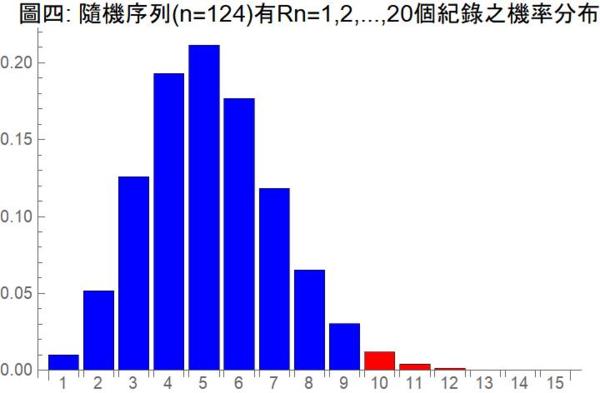
Rn 的機率分布並不容易算,有一個遞歸公式,當 n 較大時,需要很大的計算能量或很久的時間才算得出。要迅速算出,必須用到所謂「第一類史特靈數」(Stirling Numbers of the First Kind)。如果你的軟體沒有這個函數,可以利用這兩個很漂亮的公式來算 Rn 的期望值和變異量:
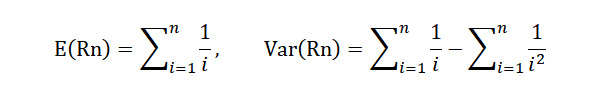
利用這兩個公式也可算出當 n = 124 時,E ( Rn ) = 5.40,Var ( Rn ) = 3.76。如果我們假設 Rn 的分布是常態分佈,則可以輕易算出以以期望值為中心的 95% 信心區間為(1.49,8.88)。因為經驗值 10 個紀錄在信心區間之外,這個分析也支持台北市年低溫變化異常的結論。不過因為 Rn 的分布並非常態,這個分析並不精確。
新紀錄等待時間的機率急遽下降
應用紀錄之機率理來分析台北市氣溫變化也可以看出 1975 年前後是一個轉捩點。
在 1897 年之後的 9 個新紀錄當中,出現在 1975 年之後短短 45 年之間的就有 5個,平均每 9 年就有一個新紀錄。而在 1976 年前的 80 年中,則平均要將近 16 年才有新的紀錄。事實上,1912 年的紀錄保持了 64 年才被打破。
也許你會說 1897-1912,在短短 16 年之間不是就有 4 個新紀錄嗎?然而新紀錄的頻率在紀錄開始之時本來就會比較頻繁,日久後要破紀錄會越來越難。紀錄的機率理論可以算在一定時間之內舊紀錄會被打破的機率,其公式如下:
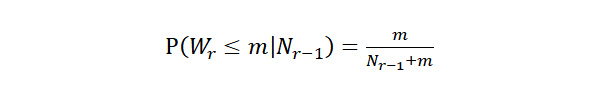
這公式所求的是在第 r – 1 個紀錄發生之後,下一個紀錄的等待時間小於或等於 m 之機率。表一之第六行顯示:從第一個紀錄發生在 1897 年開始,第二個紀錄等待了兩年就發生了,按照上式,第二個紀錄在 2 年之內發生的機率為 0.67。第二個紀錄發生在 1899 年之後,第三個紀錄等待了 6 年發生,而其在 6 年之內發生的機率也是 0.67。第三個紀錄發生在 1905 年之後,第四個紀錄要等待 13 年才發生,而其在 13 年之內發生的機率是 0.31。依此類推。這些機率都不小,雖然紀錄頻頻被打破,並不令人意外。尤其是第五個紀錄發生在 1912 年之後,第六個紀錄要等 64 年才在 1976 年發生,因為等了夠久了,其在這一段期間發生的機率是很高的(0.80)。
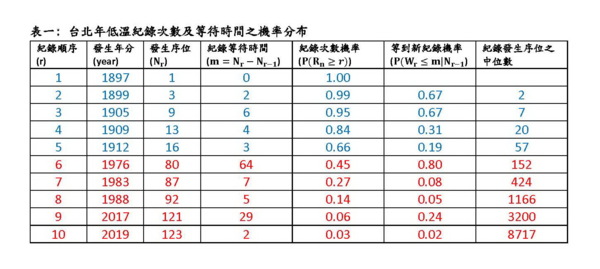
但從 1976 年以後,這個等到下一個紀錄的機率就急遽下降了。第七個紀錄在 7 年內發生,其機率是 0.08;第八個紀錄在 5 年內發生,其機率是 0.08;第九個紀錄等了 29 年,其機率稍大,但它發生之後,第十個紀錄只等了 2 年就發生,其機率小於 0.03。這樣的小機率事件發生了,如果還說氣候沒有異常,在統計學理上是無法接受的。如果我們換一個角度來看,把 1976 年當作氣候質變之後的第一個紀錄,則其後發生在 1983、1988、2017 的新紀錄其等待時間的機率(0.88,0.38,0.69)都不小,不算奇怪。只有 2019 的紀錄還在 0.05 的水平之內,不過這也可以說氣候變化越來越厲害了。
從新紀錄的等待時間來探討氣候變遷還可以看看新紀錄發生的平均時間。不過很奇妙的是:機率理論告訴我們,新紀錄雖然一定會發生(發生的機率為 1),其發生時間的期望值或理論平均數卻是無窮大,即使第二個紀錄也是一樣。以第二個紀錄為例,其發生時間為 2,3,4,…,t,…年的機率分別為 1/2,1/6,1/12,… 1 / t ( t – 1 ),…,所以期望值為 1 + 1/2 + 1/3 + … + 1 / ( t – 1 ) + …。這是有名的無窮和諧數列,它不是收斂數列,其和無窮大。其它的紀錄也是一樣。
不過我們雖然不能算發生時間的期望值,卻能算中位數,也就是發生機率最接近 1/2 的時間點。表一的第七行列出各紀錄發生時間的中位點。我們可以看到,一直到 1976 年的第六個紀錄為止,中位時間點都還算合理。此後,第七個紀錄的中位發生點要在 1897 年算起的第 424 年,第七個紀錄在第 1166 年,第九個紀錄在第 3200 年,第十個紀錄在第 8717 年。這些紀錄的中位發生時間在這麼久遠之後,如果說沒有氣候變化,誰能相信?
附帶一提,1897 – 2020 之間台北市年低溫往下探的紀錄,包括 1897 年的第一個紀錄,124 年之間只有三個:1897(5度),1898(3.3度),1902(-0.2度)。從 1902 年以來,118 年之中,-0.2 度的紀錄沒有被突破!(不過 P ( Rn ≤3 ) = 0.162 並不足以作為氣溫變化異常的統計證據。)
- 本文亦同步刊載於林澤民的部落格,原文標題為〈用「改變點」及「紀錄」探討台北暖冬的異常現象〉
參考資料
- 齊斯.德福林(Keith Devlin)、蓋瑞.洛頓(Gary Lorden)著,蘇俊鴻、蘇惠玉等譯。2016。〈改變點偵測:災難即將發生的證據何時開始浮現?〉,《案發現場:FBI警探和數學家的天作之合》(The Numbers behind Numb3rs: Solving Crime with Mathematics)第四章。八旗文化。
- Jiri Andel, 2001. “Records.” Chapter 4 of Mathematics of Chance. Wiley.
- 盧孟明、卓盈旻等著。2012。〈台灣氣候變化:1911-2009年資料分析〉。中央氣象局。



































