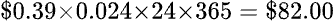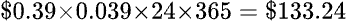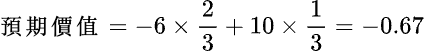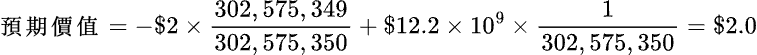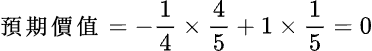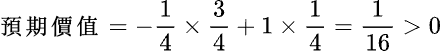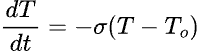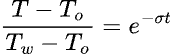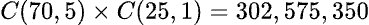隨著科技的快速進步及生活水準的不斷提高,人類在日常生活使用的工具越來越複雜。面對推陳出新,源源不絕的各種新式工具,要如何有效地使用它們呢?看到這麼多的廣告,又要如何判斷它們的真偽呢?
這些應用科學的工具固然帶來許多便利性,但是使用者在不了解背後科學原理的情況下,也可能發生誤解,造成一些錯誤觀念以訛傳訛,反而促成不必要的浪費。本文便是筆者以日常生活中的見聞,來探討生活用品背後的一些物理原理與數學,期望能釐清一些迷思,讓讀者能夠撥雲見日。
電熱水瓶 在「日常生活範式的轉變:從紙筆到 AI 」一文裡,筆者提到了許多改變我們日常生活的現代科技,卻忘了非常重要的網路購物!事實上,除了菜市場外,筆者現在幾乎已不在任何商店買東西了。網路購物有一個很大的優點,那就是很容易比較不同品牌的商品。例如 2020 年筆者決定換個熱水瓶時,在美國最大的網路市場亞馬遜(Amazon)碰到一個問題:一般的熱水瓶(如松下)大約只要美金 100 左右,唯獨像印(Zojirushi)卻有高達美金 200 元以上的熱水瓶;仔細比較一下,唯一的大不同是後者有真空保溫的外層。一向節儉慣的筆者幾經思考後決定購買 4 公升裝的松下。
在透過提高裝貨運送速度、實施更嚴格的賣家驗證流程來應對假冒產品的擔憂後,中國大陸的「全球速賣通」(AliExpress) 似乎已重返美國市場,筆者最近兩、三年也開始敢在其網站購物了。數月前看到它廣告只要美金 150 元的像印真空保溫熱水瓶,一向喜歡佔小便宜的筆者就買了一隻,讓筆者有實際的數據來比較像印的高價是否值得。像印的規格資料謂保持在 90℃ 的平均功率是 24 瓦特;美國聖荷西市的電費是每一度(千瓦小時)0.39 美元,因此每年用在保溫的電費為
松下的規格資料謂保持在 88℃ 的平均功率是 39 瓦特,因此每年用在保溫的電費是
即像印熱水瓶每年可節省約 51 美元的保溫費!值不值得高價買像印熱水瓶那就看讀者準備要用多久了。筆者的松下熱水瓶用了 4 年多,因此後悔當初沒有買比較貴的像印真空保溫熱水瓶了!
一般電熱水瓶均有所謂的「節能定時器功能」:因為晚上睡覺時不用熱水,所以在睡覺前將熱水瓶關掉,可以設定幾小時後,再自動加熱,讓讀者起來時立即有熱水泡茶或沖咖啡。這看起來是很方便,但真的節能嗎?
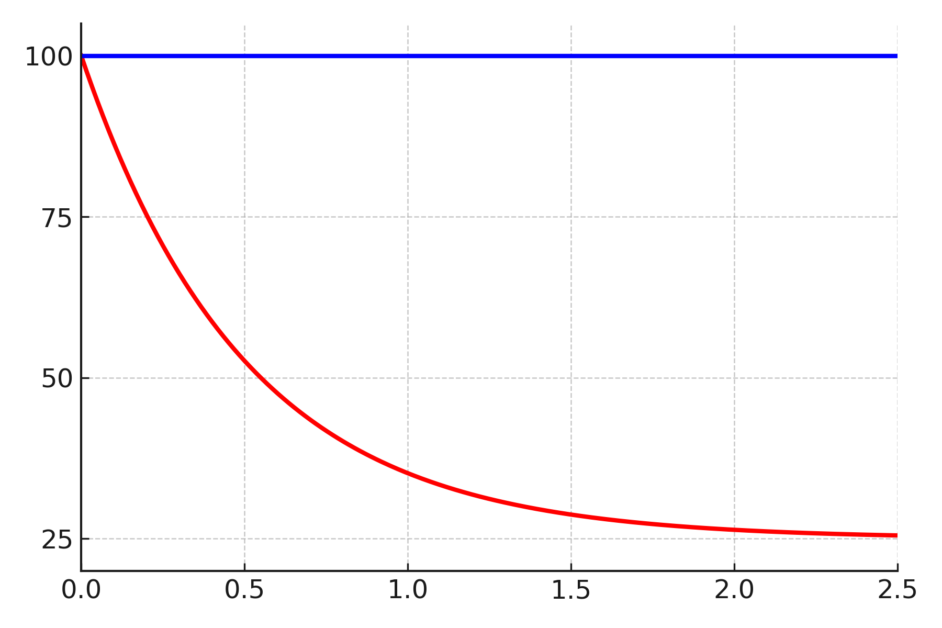
讓我們在這裡來分析一下吧。如果有科學儀器幫忙,分析將是輕而易舉;但事實上即使沒有,我們還是可以做很多有意義之分析的。我們關掉熱水瓶的電後,其溫度將類似圖一的紅線下降(註一),「最後」到達室溫。理論上「最後」應是慢慢逼近,永遠不可能達到室溫的。
圖一: x 軸為特徵時間(相對值),y 軸為溫度。紅線為熱水瓶依據牛頓冷卻定律所畫出的降溫曲線,藍線代表熱水瓶維持保溫狀態。
但在實應上,我們可以說到達 1.5 之 x 座標時已經是室溫。而 1.5 到底是多少小時,則因電熱水瓶的設計及室溫之不同而異。如果設定的節能定時 x ≤ 1.5,那麼熱水瓶所散的熱正好由重新啟動的加熱補上,所以根本沒有節能;如果設定的 x > 1.5,則因熱水瓶在 x ≥ 1.5 後就已經不再散熱了,而沒有關掉的熱水瓶仍必須繼續保溫(圖一藍線),所以關掉熱水瓶是值得的、有節能的效果。
松下熱水瓶只有一個 6 小時的定時,筆者夏天做了一個實驗,發現 7 小時後還是室溫,所以沒用過它的「節能定時器功能」;像印松下熱水瓶在 6-12 小時間有 6 個定時。
便攜式空調 聖荷西夏天很熱的時間不長,因此筆者一直想買容易移動的「便攜式空調」(portable air conditioner),以便炎暑一過就可以收起來。以「portable air conditioner」搜尋亞馬遜網路市場,發現有價格差異很大的兩種空調:一種大約在美金 100 元以下,另一種則大約在 200 元以上。
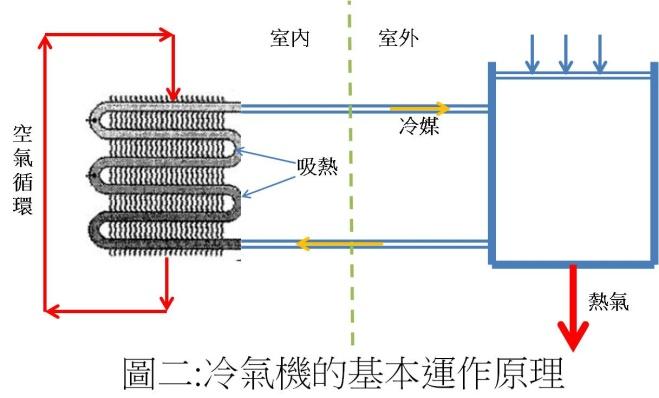
仔細「研究」發現其差異是前者不必要往外面排熱氣,後者必須有管子通到外面以便排掉熱氣。我們知道能量不滅定律,如果用電產生的熱不往外排掉,那熱只能留在房間內,房間只會越來越熱,不可能變冷的!所以這類的「冷氣機」(圖二)只能像電扇一樣,讓你在電扇前面感到涼爽而已!
事實上比電扇好一點的都加了一個水箱,利用蒸發水會吸熱,讓你感到的風比電扇更冷一點,所以價錢比普通電扇高一點。這種電扇在乾燥的地方事實上是一雙箭雕:除了吹冷風外,同時可以增加空氣的濕度;但是在濕度很高的台灣,其結果可能讓人感到更悶、更難受。
為什麼要使用水呢?除了是最常見的物質之外,水俱有許多其它物質所沒有的性質(參見「奇妙的水分子」),例如氣化熱(一克的水蒸發成一克的氣體所需的熱)、比熱(將一克的水提高溫度一度所需的熱)等等均比其它物質高出許多,所以我們馬上將看到水也常來當冷卻劑。
前面所談到之兩種空調在外表上的不同是「往外面排熱氣的管子」,在內部構造上則是「壓縮機的有無」。壓縮機將氣態冷媒擠壓成液態時會產生大量的熱,冷氣機必須透過「熱交換」將它們丟到外面去,這就是為什麼「真正的冷氣機」需要有通到外面的排氣管。被壓縮的冷媒到了壓力較低的地方會立即透過「熱交換」吸熱膨脹成氣態的冷媒。前者「熱交換」的媒體主要是室外的空氣(為了提高效力,大冷氣機會用水),後者則是室內的空氣(見圖二)。
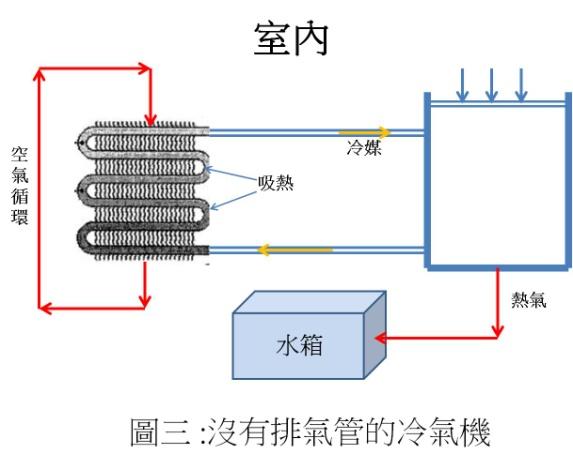
沒有排氣管的冷氣機 所以真正的冷氣機應該要有排氣管,但筆者在網路上逛店時卻發現有壓縮機、但沒有排氣管的冷氣機!例如有一款「HANLIN HS02 移動冷氣 行動空調 」廣告謂:「商業級強勁壓縮機秒速制冷,快速降溫,讓酷暑瞬間消散;……。免排水高溫自蒸發系統,內建水箱設計,開機預設開啟,免排水冷凝水,高溫排風自動霧化」。從產品特色看來,壓縮機所產生的熱量應該是用來蒸發(霧化)「水箱」的水(見圖三)。讓我們在這裡利用能量不滅定律來看看是否可行。
該產品的規格謂其冷氣量為 1400 瓦特,即每秒鐘可以從室內拿掉1400焦耳的能量。前面提到水的汽化熱很高,約為每公克 2260 焦耳;因此該機器每秒鐘能蒸發掉約 0.62 公克(1400/2260)的水。也就是說為了保持室溫不變,一小時必須蒸發掉 2230 公克(2.23 公升)的水。因此除非水箱是 24 公升大,「12 小時預約定時,可設定開關機時間,方便您的生活」是絕對不可能的!還有,這些蒸發的水氣很快就會達到飽和點、結合成液態水,釋放出其剛吸收的汽化熱到室內,不可能降低室內溫度的!在廣告中他們特別介紹了「外出露營帳篷使用方法」,相信那才是該冷氣機可以真正發揮功能的地方;而商品配件中的「排水管」應該是用來「勸」我們在室內使用吧?
所以用蒸發水來冷卻壓縮機似乎是不可行的,但因為水的比熱較空氣高多了,循環「水箱」的水來冷卻壓縮機效益應該比空氣更高(見圖三),可行嗎?
DIKE 多功能移動式瞬涼水冷氣 HLE700WT 就是基於這種想法的一個產品。其廣告謂:創新「無排熱管」冰風機,採用水冷循環及高效壓縮機製冷,出風降溫至 14℃,搭配獨立除溼、送風三合一功能四季都適用!前面涼快,後面涼快,無須排熱風管免窗戶施工。…製冷前需先將水箱加水,維持水循環運作,水箱裝滿 4 公升時可持續製冷 8 到 12小 時,一整天都涼爽。因為水是熱交換媒,因此廣告特別強調「大容量水箱」,讓我們在這裡也利用能量不滅定律來看看是否可行。
廣告中沒有提到冷氣量,讓我們在這裡假設與前面那款冷氣機一樣(1400瓦特)吧,即每秒鐘可以從室內拿掉1400焦耳的能量,或每小時可以拿掉5040千焦耳的能量。前面提到水的比熱很高,將1公克的水提升溫度一度需4.2焦耳;因此4公升(4000克)的水從30°C提升到100°C 水滾前可以拿掉1176千焦耳(4.2 x 4000 x 70)的熱,也就是說僅能夠拿掉冷氣機0.23小時的壓縮熱能(1176/5040)!
彩券 與 選擇題 美國有許多州聯合起來的「百萬大獎」(Mega Millions):玩家可以從兩個獨立的數字池中挑選六個數字——從 1 到 70 中的五個不同數字(白球)和從 1 到 25 中的一個數字(金色百萬富翁球)。學過排列組合的讀者應該可以算出其得獎或然率是 302,575,350 之一(註二)。
美國的人口約為 335 百萬,估計絕對不會有半數以上的人買,所以其設計是每次有人中獎的機會不大,獎金下移累積,因此三不五時會出現一個大獎來製造大新聞。例如有一次大獎是 12.2 億美元,而每張「百萬大獎」券才 2 元;這麼高的「益本比」確實是相當吸引人,因此到處出現大排長龍購買,讀者會加入行列嗎?
數學及經濟學上有一稱為「預期價值」(expected value)——隨機變數可能的值,乘上其機率的總和——來幫助我們決定是否值得投資。例如假設拋硬幣正面的或然率為 2/3,反面的或然率為 1/3 ;如果擲出正面,您輸掉 $6,反面您贏得 $10;您賭嗎?這遊戲的「預期價值」為:
即平均而言,每次玩此遊戲大約會輸掉 $0.67,所以不值得玩。我們就用這個方法來看看是否值得去排長龍買「百萬大獎」吧。因為一定要買才能中獎,所以嚴格說來,在這裡不能用「預期價值」。但因為中獎幾率可以說是零,所以在這裡假設沒必要買,只是去選號碼,沒中獎時才交$2.00:
也就是說即使每次都是大獎,我們每次只要去排隊選號就可以得到$2.00。筆者雖然退休了,沒什麼大事可做,還是不會浪費時間去排隊購買的;當然,如果是因為愛國,那就另當別論了!
但是如果有 $302,575,350 將所有的組合都買下來,那不是一定可以中獎得到 $12.2 億嗎?筆者謹在此建議「泛科學」讀者成立「美國愛國獎券基金會」,募款 $302,575,350 讓我們一起發財吧(註三)!
除了投資及愛國獎券外,「預期價值」在日常生活中事實上還有一個非常有用的地方:那就是決定考試選擇題的策略。早在 1977 年當筆者還不知道什麼是投資時,就已經用常識分析了這個問題:
現行(大學入學分科測驗)倒扣的計算方法(如五選一,答對 1 分,答錯扣 0.25 分),任何只要具備簡單或然率知識的人均能算出:如果考生「完全瞎猜」,則得分數與倒扣分數剛好互相抵消。
上面這種稱為「邁可生倒扣公式」的預期價值是
在這種倒扣方法下,最佳戰略應該如何決定?顯然地,如果在五個答案中,我已經知道一個或一個以上的答案是錯的,那我應該答,因為得分的或然率已高於倒扣分的或然率:
但是如果我很不幸地「完完全全不知」呢?那因為答了也不吃虧,所以也應該答!!!總而言之,不管怎麼樣,每題都應該答!記住,每題都應該答!
「倒扣」的記分方法原有遏止考生投機的用意,可是根據上面的分析,邁可生倒扣公式不僅達不到遏止投機的目的,反而會助長之;所以,如果要避免考生猜題,倒扣比例應該提高。現在讀者應該不難算出:如果倒扣為 0.30 分,那麼邁可生倒扣公式之預期價值便變成 -0.04,就不值得瞎猜了!
結論 像印牌熱水瓶使用真空保溫,散熱率較低,也因之價格較高,但長期使用下來還是值得的。熱水瓶的「節能定時器功能」是否節能得看環境及定時長短。
「真正的冷氣機」一定要具有能「往外面排熱氣的管子」,否則因為能量不滅的關係,所有的熱只能留在室內,或許可以讓站在出風口處的人感到冷風或冷氣,但是絕對不可能使室溫下降的。事實上根本不需要分析,簡單的邏輯告訴我們:不拿熱到外面的任何機器都不可能讓室內冷下來的!筆者最後還是買了一款定價高一點、體積大很多、有管子通往外面、不怎麼方便的「便攜式空調」(註四),其冷氣量高達 4100 瓦特,為「HANLIN HS02 移動冷氣」的3倍!
美國之「百萬大獎」的「益本比」雖然可以上十億,但投資報酬率(預期價值)似乎太低,不值得浪費時間排隊去買的。如果考試選擇題採用的是「邁可生倒扣公式」,那即是完全不知道答案,也應該每題都要回答!
附註
(註一)只要透過基本微積分就可以導出來。熱水瓶的溫度(T)下降速率應該正比於散熱係數(σ)及裡外溫差(T-To ):
式中的 To 為室外溫度,解得
式中的 Tw 為熱水瓶的設定溫度(即 t=0 時的溫度)。
(註二)選一「白球」的方法有 C(70, 5) ,選五「金色百萬富翁球」的方法有 C(25, 1) , 所以選一「白球」及五「金色球」的方法有:
(註三)筆者尚不知如何買下所有的 302,575,350 組合,請讀者提供高見。
(註四)事實上是冷暖兩用機:圖三中的室內、室外互換即成暖氣機。當暖氣機用時,因為要從室外拿熱進來,其效率比一般只在室內用電加熱的「純電熱器」高(2.7:1)。
延伸閱讀
「奇妙的水分子」,科學月刊,1979年1月。
「聯考與選擇題」,科學月刊,1977年8月。
「日常生活中的物理與化學」,科學月刊,2010年12月。
「日常生活範式的轉變:從紙筆到 AI 」,泛科學,2023/03/08。
《我愛科學 》,華騰文化有限公司,2017年12月出版;內含「奇妙的水分子」、「聯考與選擇題」、「日常生活中的物理與化學」。