
數十年來,多數心理學家和新興的行為經濟學家在可控制的實驗情境中,不斷研究人類的決策過程。這些研究結果不僅動搖關於人類理性的基本假設,甚至迫使大家用一種截然不同的觀點來思考人類行為。
例如,心理學家已經藉由無數個實驗證明,人的選擇和行為會受到特定字詞、聲音等刺激的「促發」(priming)所影響。受試者若在實驗中念到「老」和「虛弱」等字詞,他們離開實驗室在走廊上行走的速度就會變慢。在酒坊裡,如果店家播放的背景音樂是德國音樂,消費者更有可能購買德國葡萄酒,如果是法國音樂,則會傾向購買法國葡萄酒。受訪者在填寫跟運動飲料有關的調查問卷時,如果是用綠色的筆,則更可能會選擇開特力運動飲料(Gatorade)。購物網站的背景圖案如果是蓬鬆的白雲,網路購物者更有可能選擇昂貴、舒適的沙發,如果背景圖案是錢幣,則購物者傾向買較硬、較便宜的沙發。

我們的反應也可能被無關的數字給影響。有一項實驗,要求參與葡萄酒拍賣會的人在競價之前寫下自己社會保險號碼的末兩位數字。儘管數字基本上是隨機的,且絕對與買家對酒的估價無關,但研究人員發現數字越大,買家就更願意出價。心理學家稱這種現象為「錨定效應」。不論是估計非洲聯盟的會員國數量,或是我們認為合理的小費或捐款金額,都可能受到錨定效應的影響。
事實上,當慈善機構的募款單上附有「建議」捐款金額,或帳單上預先寫出小費的比率,你都該懷疑這是利用錨定效應技巧,因為提出一個較高的金額,其實是在錨定你對「公平」的初步估計。就算你覺得 25% 的小費似乎太高了,所以調降你的估計值,但最後給出去的小費或許還是高於沒有被暗示時的金額。
改變情境呈現的方式也可能強烈影響個人偏好。比方說,在同一個賭局,如果強調輸錢的可能性,就會讓人傾向規避風險,但如果強調贏錢的可能性,則會造成相反的結果。更讓人困惑的是,加入第三種選項,竟然可以逆轉一個人對先前兩種選項的偏好。
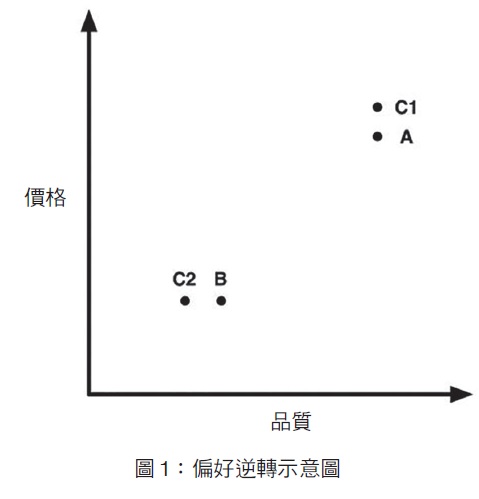
舉例來說,A 是一款品質好、價錢昂貴的相機,B 是品質較差,但較便宜的相機。光這樣看可能很難比較與選擇。但假設如下圖所示,加入第三個選項 C1,雖然品質差不多,但顯然比 A 貴。這時要選擇 A 或是 C1 就變得很明確了。三者中選擇 A 的占大多數,這似乎非常合理。但假設加入的第三個選項是價錢跟 B 差不多,但品質較差的 C2,那大家又會如何選擇?這種情況當然會選擇 B。換句話說,即使選項 A 和 B 都沒有改變,只要加入一個不同的選項,就能夠有效逆轉對 A 和 B 的偏好。更奇怪的是,決策者永遠都不會選擇引起偏好逆轉的第三個選項。
心理學家藉由研究這一系列非理性的行為發現,提取或回憶不同類型訊息時,其難易度通常會影響人類的決策與判斷。以搭飛機為例,與其他任何致命因素相比,人們通常會高估死於恐怖攻擊的可能性。因為人們對恐怖攻擊的印象非常鮮明,即便它發生的機率明顯低於任何其他事故。
還有一個矛盾的情況,當人們被要求回憶自己果斷行動的經驗時,通常會認為自己沒那麼果斷。並不是因為這個問題和他們對自己的看法有衝突,而是因為回想的時候很費力。相較於真實情形,人們也傾向於認為自己現在的行為、信念都跟過去差不多。
此外,在閱讀一份手寫聲明稿時,如果字體容易閱讀,或者之前曾經看過,那這份聲明就會更容易被取信。就算人們上次看這份聲明時,已經明確知道那是假的,結果依然如此。

最後,人們消化新訊息的方式,往往會增強他們既有的想法。某種程度上,這是因為我們偏愛注意「更能證實自己既有信念」的訊息,並忽略不符合自己信念的訊息。
另一方面,我們對於那些不符合自己信念的訊息,也傾向加以質疑或嚴格檢查。這兩種密切相關的傾向,分別稱作「確認偏誤」(confirmation bias)和「動機性推論」(motivated reasoning),會嚴重阻礙我們解決爭端的能力。從家事上的小分歧,到北愛爾蘭或以巴衝突都深受其害。在這些爭端當中,各持己見的雙方看待的明明是同一套「事實」,但對實情的印象卻完全不同。
即便是在科學領域,確認偏誤與動機性推論也時常扮演有害的角色。基本上,科學家應該遵循基於證據的真相,即使該證據與自己既有的信念或理論相抵觸,但是更多時候,科學家反而質疑證據。
結果正如量子力學創始者馬克斯.普朗克(Max Planck)的至理名言:「一個新的科學真理之所以能勝出,不是因為它說服了反對者,讓那些人接受——而是因為反對者死光了。」

——本文摘自《超越直覺》,2024 年 01 月,一起來出版,未經同意請勿轉載。




































