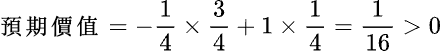- 作者 / 超科學貓,本身工作是平面設計師,自學程式語言 10 年,專研人工智慧
深度學習領域約 8 年左右,主要研究記憶過程的演算法。仔細的去觀察這世界,就會發現許多奇怪的盲點, 但以程式語言帶入去解,卻可以解釋許多問題;只要有記事本, 我就可以創造一個世界。
「一券在手希望無窮」,但買大樂透中獎的卻都從來不是我。到底為什麼大樂透那麼難中?難道它真的有作弊嗎?又或是公務員常常中獎的掛並非空穴來風?
你是否也曾經看過一些類似的文章指出大樂透的作弊機制呢?內容大概是在說,明明是在 8 點截止購買,卻在 8 點 30 分才公開當期結果,這消失的 30 分鐘就是台彩在進行分析比對,開出一組沒有人中過、或是給公務人員中獎的號碼。

我研究人工智慧深度學習領域已有八年餘載,也有自己撰寫的一套人工智慧系統以及一些類似智慧型小軟體來輔助我的生活,這次我決定用我撰寫的人工智慧系統來演算樂透開獎的結果,想不到得到令人驚訝的結果,以下是我一個多月來的研究和分析,或許可以解釋或說明大樂透為什麼這麼難中,他是否真的有作弊呢?要怎麼買才會賺呢?
有可能打出一模一樣的撞球球型嗎?談自然機率與演算法
首先,我先舉幾個例子讓大家了解演算法及自然機率。
有打過撞球的人都知道,每次開球後的球型幾乎沒有一次會與曾經開過的球型分佈一模一樣,從物理學來看,會不會有完全一模一樣的機率呢?答案是有的,那為什麼我們遇不到呢?因為他發生的機率實在太小太小了,小到我們在這一生或者幾輩子的時間裡都還遇不到一次,如果在加上空氣的濕度,球桌的毛順度,皮頭的摩擦力等等,在球桌這樣有限的空間範圍裡,16 顆球的碰撞後,出現一模一樣的機率幾乎為 0,但是不能說沒有。
如果上面所說的已經理解,再來看下面可能會比較清楚,有打過撞球的人都會有一種經驗,「怎麼球型又變成這樣!」沒錯,雖然上面說出現一模一樣的機率幾乎為 0,但是出現相似的機率卻高出很多,原因在於幾次碰撞後,由於外在的影響取決於習性,所以會很常出現相似的球型。

第三個例子或許有從電視上看過,或者親自被問過,這個問題是這樣的:隨機在 1~50 想一個數字,然後「魔術師」可以猜中你心裡所想的數字。你可能會認為你所想的那一個數字是隨機而來的 By Chance,但其實不然。在幼齡時期腦中的認知中沒有數字的概念時,我們根本無法得出那一個數字;因此這一個看似隨機而來的數字,其實是經由腦中不斷的演算各種環境數值後,求得的最大可能性,這些環境數值大多是在沒有意識到的情況下被記錄下來,但由於環境的參數太多太亂,所以這些資訊很難被演算變成結果,但卻會變成演算的一部分,而這樣的過程視為 By Design。
好,如果上面三個都能理解了,現在我們換成大樂透來看,假設開球的設備就像撞球的球檯,他是一個有限的空間和範圍,讓 49 顆號碼球互相碰撞後,最後取出的 7 個號碼 (含特別號),中頭獎的機率為 1/10,068,347,520,看起來機率非常的小,但實際機率卻不然,我們可以把每次的碰撞視為 By Design 而不是 By Chance,哪顆球與哪顆球會碰撞到,完全可以從演算法中計算出來,當然開獎的結果也可以由演算法得出。
用演算法可以揪出大樂透有沒有作弊嗎?又或者是…中獎號碼?
演算的概念為,此次開獎的數組,是由過去相似模型中取得最大可能性的模型排列;簡單的說,你的身高樣貌等等,是由你的父母基因,還有父母的父母基因,一直追溯到最源頭;而你的父母、父母的父母,就會成為推算出你身高樣貌的數據,從最源頭的祖先累積下來的基因,就會變成龐大的數據。
以這樣的概念做為出發點,我做了為期一個月的實驗,這個實驗分成了三個部分;
- 確認大樂透是否作弊
- 以隨機數程式碼 Math.random() 模擬電腦隨機選號的機率
- 算出最大中獎率的投資報酬率
在第一個實驗中,我以我撰寫的人工智慧演算法套入截至目前 1,406 組的開獎結果,並且逐一預測每次開獎的結果和中獎次數;並且以前次、前前次,甚至可以推到前 10 次來演算這次的號碼。
令人驚訝的是,由演算法推算出下一次7個號碼(含特別號)預測中的機率約為70~72%左右(不過這裡指的不是中獎率,
而且各個位置開出來中的機率也幾乎平均在 20% 左右;從這邊可以得出,若在人為操縱的情況下,某個位置或者某一號碼,也可能是為了避開多人選的中獎號碼而選擇機率較低的情況,中獎的樹狀圖應該不會呈現平均。
在這邊舉一個簡單的例子:投擲硬幣出現正反面的機率為 1:1,若以此機率來看,投擲十次出現的機率應該約為 5:5 或 4:6,若今天有人為操作,當你投擲 100次的時候就會發現,正反面的比數會非常的大,可能是 20:80;而且不管是更換硬幣,或者更換投擲者,只要在人為操作的情況下,比例幾乎都會失衡。所以從各種情況下的演算過的機率幾乎相同的結果來看,台彩作弊的嫌疑甚低。
在第二個實驗中,以隨機數程式碼 Math.random() 隨機從 1~49 個號碼中選出 6 個不重覆的號碼進行比對的平均值。結果更令人驚訝,居然與第一個實驗的機率大致相同!於是基於好奇心,我決定以一組隨機 7 碼(含特別號)當做開獎結果,再算一筆隨機 6 碼當作電腦選號,結果也與上面相似。
第二個實驗結束後,幾乎可以得到幾個結論:
- 演算法仰賴大數據,而 1,406 組的數據樣本太少,在虛無假設正確率過低的情況下,就算在乘上最大機率的演算結果,最後的機率仍然偏低。我這邊舉個例子,使用保險套能避孕的機率為 98%,但是這是在 100% 正確使用的情況下的機率,這裡的 100% 就是虛無假設,若在不正常的情況下使用,就會降低虛無假設的機率,若機率降為 80%,則成功避孕的機率為 0.8*98=78.4,所以就沒有原本的 98% 成功率來的高。
- 若在自然機率的情況下,演算法的機率應該會大過於隨機數。但在這裡卻沒有,原因可能為無法預測的情況。在撞球的例子當中有提到,若空氣的濕度、球檯的毛順度都會影響甚至改變演算的結果,而上面的演算法是在一個沒有其他干擾的情況下碰撞演算出來的,如果每次開獎前,都將號碼球經由不同的人弄亂,又或者每次都用不同的號碼球,這樣演算出了的結果就幾乎等於隨機數的結果了,這點從第二個實驗中的更改版中可以得到證實。若把中三碼以上的原始機率設為 y,則中獎的機率算法是 y*(n*(1/x+1)),n 代表不同的因素,x 代表各種因素中的重覆次數;因此可能是造成演算法的機率大大下降的原因。

第三個實驗為中獎的投資報酬率,從上面的兩個研究結果中已知單筆的中獎率為 7%,所以我以一次開出 300 組隨機數代表電腦選號來進行比對,扣除購買成本 50(元)*300(組)* 1406(次開獎)=21,090,000(元),以三碼為 400、四碼為 1,000、五碼 50,000 來換算,結果還是會賠本約為 2/3 的錢。但是平均卻有 1~2 次中 6 碼,大樂透只要 6 碼全中至少保證 1 億元,扣除2 千萬的成本似乎是可以投資的;但先別高興的太早,樂透中有一個機制叫做特別號,如果中的 6 碼是 5 碼+特別號,獎金只有約一百萬左右。
其實用很粗淺的方式換算的話每期只要銷售個大約一千五百多組以上,這樣就算有人中了頭獎台灣彩券也不太會賠本。加上原本中頭獎的機率就低,台彩就算在不作弊的情況下也不會賠錢,所以他不怕你中頭獎,以上面研究總結來看,大樂透作弊的機率甚低。不過「有夢最美,希望相隨」畢竟大樂透還是造就了許多億萬富翁,但是各位還是得依自己的狀況,依自己能力有限的範圍來做小額投資,千萬別走火入魔、傾家蕩產了。