


作者/詹芷瑄

站在漫天飛舞的花絮中,為自己和愛人定格那美麗的瞬間,想必榮登最浪漫寶座第一名。在日本每年 2-5 月的氣象報導,會增加「櫻前線」的特別專欄,告訴國民櫻花初開及滿開的地點,隨著時間從南部慢慢移動到北部,舉國共享這份喜悅。其實在台灣,櫻花原生種也不少,我們是否也能欣賞到這樣的美景呢?櫻花花期大約只有兩個禮拜左右,賞櫻關鍵可要抓住時機。那麼日本如何判斷櫻前線呢?
日本如何判定櫻前線
首先,我們來看日本氣象廳是如何判斷櫻花的開放時間的吧。
日本氣象廳在全國各地設有櫻花標本木,每年定出幾十個櫻花觀測地點。當觀測地點中的標本木有 5~6 朵以上開花數,即達初花日;若開花率達 80% 以上,即達滿開日,大多數遊客會選擇在這個時候賞櫻,因此賞櫻人潮最多。
標本木主要選擇染井吉野櫻(Prunus yedoensis Matsum. cv. Yedoensis)品種,這是江戶彼岸櫻(Cerasus spachiana fo. ascendens)與大島櫻(Cerasus speciosa)的雜交種。江戶彼岸櫻原生地由於年代久遠已不可考,它適合生長的環境偏溫帶,像北海道等地;而大島櫻是日本南部沖繩、奄美的原生種,兩者雜交後的染井吉野櫻,開花時沒有葉子,形態色澤美麗,外觀受大眾喜愛。但染井吉野櫻無法自然繁殖後代,須利用無性繁殖技術加以保留,不過也因為如此而保存了相同的遺傳基因,所以開花特性相同。目前日本地區八成以上是此品種,所稱日本櫻花大抵就是指染井吉野櫻。
依靠同種植株預測櫻花開放時間,相對來說準確度提高不少。但在台灣並沒有大數量的染井吉野櫻,又該怎麼判斷各地的開花時間呢?那就問問櫻花本人吧!
櫻花會算日子! 它會數寒冬過了多長了,暖春來了多久了
櫻花是薔薇科多年生落葉性喬木,在每年夏季的生長期,會在枝條內部開始長芽,並特化成花朵的特殊構造原型。感應到日照時間縮短、黑暗期增長,或者氣溫降低,樹木生長減緩,溫度降到 10℃ 左右時,落葉性喬木就會停止生長。等到冬天真正來臨,感應到更加低溫的環境,為了抵擋寒冷的逆境,就會進入休眠。這裡的休眠是植物主動調控內部生理反應、停止生長狀態及降低體內水分等,在園藝學上稱為內生性休眠(endodormancy)。
形成內生性休眠之後,會開始計算低溫需求(chilling requirement)。也就是指在空氣溫度 0 ℃ — 7 ℃ 的條件下,累積到特定的時間,才可以打破休眠。在還沒累積足夠低溫量之前,即使外在環境達到適合生長的時間或溫度,也無法打破休眠,這是植物為了應付環境變動而演化出來的聰明機制,能感應周圍環境的變化,調整自己的生長狀態。等低溫需求到達一定的累積量,就會轉變成外生性休眠(ecodormancy)了。
外生性休眠是植物的雙重保險,能避免天氣的間歇性變化。比如冬日裡若有一兩天氣溫較高,使還沒進入春天的溫暖期前就開花,徒增承受寒害的風險。於是植物發展出計算生長積熱需求(growing degree hour requirement)的能力,算出進入溫暖的日子有多長,去判斷春天是不是真的到來。每個植物自己有不同的標準,如果累積的積熱量達到標準,植物才會確定春天真的到來了,開始萌芽開花。而低溫需求與生長積熱需求要同時考慮,才能計算出具體的開花時間。
這兩種植物生理現象也能夠用來說明,為什麼有些農民會說今年不夠冷,或是天氣忽冷忽熱,影響植物開花結果的原因了。掌握植物開花機制,專家們就能夠通過氣象資料,預測櫻花開花時間,「櫻前線」由此而來。
要怎麼知道有沒有達到「足夠的低溫量」呢?
截至目前為止,植物學家們仍然還未完全解開休眠機制的謎底,所以無法從樹木生理的角度解釋和預測開花日期。但是在栽培的過程當中,他們慢慢發現一些規律。比如冬天過冷或不冷櫻花都會比較晚開。於是他們嘗試把經驗轉化成可以量化的模型,而去測試櫻花這類落葉性喬木滿足低溫需求的有效溫度範圍,在種植的時候測量和記錄環境溫度變化,就可以判斷植物是不是滿足低溫需求了。

把時數相加就可以知道什麼時候開花的低溫時數模型
最先被廣泛使用的模型是低溫時數模型(Chilling Hours Model),單位稱為「低溫時數」(Chilling Hour, CH),其中低溫指的是 0℃-7.2 ℃ 之間的溫度,而低温時數顧名思義就是把滿足低溫需求的小時數相加,再對照作物的已知參考值,就能判斷它是否解除休眠狀態了,是不是很簡單呢?
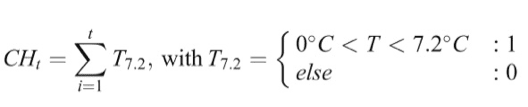
等等,讀到這裡似乎有個小小的矛盾,如果要計算小時數才能知道開花的時間,算完的時候也開花了,那知道了計算模型又有什麼用呢?
其實在管理者實際操作的時候,大多是根據氣象資料歷年的數據,對比今年的氣溫變化狀況,預期最快和最慢開花的時間,推測可能的開花日。而預測開花時間,就可以試著配合季節性活動,例如台大杜鵑花節等其他因素調整花期,也常常用來分散果品的產期,使水果產期延長,分散盛產掉價的風險,若提早上市還能賣到不錯的價錢呢。
這種計算小時數的方法,是大概在 1940 年代提出的第一代模型,後來也慢慢發展出其他的計算方式,像是下面要介紹的猶他模型和動力學模型,是大眾比較能夠接受和應用的模型。

給溫度加權的猶他模型
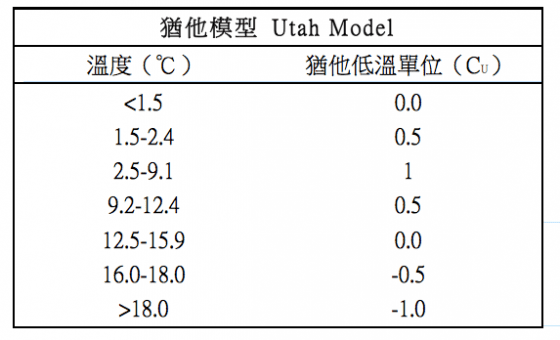
因為大家慢慢覺得低溫時數模型計算出來的開花時間不夠準確,而植物學家進一步發現,太高或者太低的溫度會對植物累積低溫需求產生負面的影響。於是 974c 年由Richardson提出了猶他模型(Utah Chilling Model),單位稱為“猶他低溫單位”(Utah Chilling Unit, CU),將溫度更詳細劃分成不同的區塊,環境的溫度落在不同的區塊內會有不同的數值,有正有負的數值相加,才得出最後的標準參考值。因為簡單方便的關係,這個模型是目前最為廣泛應用的一種。
回歸植物生理之進擊的動力學模型
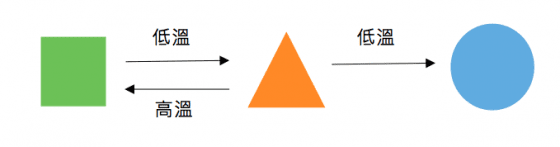
但把上述兩種方法應用到相對較高溫的地區,例如以色列等地的時候,這種利用溫度劃分的模型又變得不適用了。因此為了解決暖冬地區的植物栽培問題, 1987 年植物學家們回到植物生理的角度提出了「兩階段作用」的概念(Two-step Process),假設休眠狀態的完成度與某個「打破休眠因子「的含量呈線性關係,那麼生成這個因子的速度就決定了滿足低溫需求的快慢。
所謂“兩階段作用”,指的就是生成這個因子的過程有兩個步驟。第一階段是一個可逆的反應,通過酵素作用,在低溫條件下生成此因子的前驅物(precursor),而這種前驅物會因為高溫被破壞;第二階段是不可逆的反應,當前驅物累計達到一定量會形成穩定的“打破休眠因子”,這時候才算開始累積低溫需求。
由此看來大多時候植物其實是處在緩衝期內來回擺動,藉此發展出最新的動力學模型(Dynamic Model),單位是「低溫片段」(Chilling Portion, CP)。這個模型是藉由不間斷的偵測和計算,利用溫度的變動判斷是否滿足低溫需求,來達到最貼近植物生長狀態的模擬效果。以下是動態模型略微複雜的計算公式,其中slp, tetmlt, a0, a1, e0, e1為常數。

而根據Elike和Patrick的統計比較方法,把不同地區的原始數據帶入三種方法中,並將計算結果相除,發現數值差異非常大,表示這三種模型的結果並不成比例,也就是說這些模型的適用範圍不太一樣,那到底要怎麼選擇呢?
統計模型只是個工具喔
低溫需求的模型是來自於管理者的經驗,而且根據不同植物、不同地區需要進一步調整,例如調整猶他模型的溫度界限或者改變動力學模型的常數值等等,沒有一套萬能公式可以從南用到北、從櫻花用到桃花。如何選擇模型要靠自己嘗試,不適用的模型就像是不趁手的工具,這個不行就換一把再試試看囖。
低溫需求滿足後,還有高溫需求呢
高溫需求也就是剛才提到的“生長積熱需求”,它們的計算原理大同小異,只不過溫度範圍換成 4℃~25℃ 。在低溫需求被滿足之後馬上開始計算,當氣溫小於 4℃ 時不予計算;介於 4℃~25℃ 之間時,用實際氣溫減去 4℃ 得到結果;當氣溫大於 25℃ 時,就採用 25℃ 減 4℃ 得到的 21 作為累積值。累加到每種作物的已知經驗值,就可以開花囖。

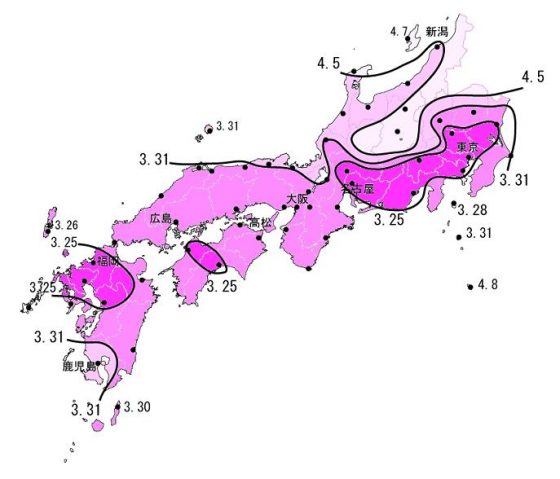
說了這麼多,如果真的很想要和心愛的人來一場浪漫的櫻花之旅的話,除了及時發漏日本櫻前線的氣象報導,或者用上述方法自己推估之外,再提供一個小小資訊給大家參考:根據 2011 年在岡山縣的櫻花物候學研究,日本櫻花的開放順序是先從都市開始,然後是北方內陸最後才是南方近海喔。這是由於當地環境、太陽照射及風速合力影響的結果。
看完這篇對櫻花的開花生理有沒有稍稍理解了呢!最後,祝大家今年能夠賞櫻成功啦!
參考文獻:
- Chandler, W.H. 1942. Deciduous orchards. Lea & Febiger, Philadelphia
- Luedeling, E. and P.H. Brown. 2011. A global analysis of the comparability of winter chill models for fruit and nut trees. Int. J. Biometeorol. 55:411-421.
- Fishman S, Erez A, Couvillon GA (1987a) The temperaturedependence of dormancy breaking in plants – computersimulation of processes studied under controlled temperatures. J. Theor Biol 126(3):309–321
- Fishman S, Erez A, Couvillon GA (1987b) The temperature dependence of dormancy breaking in plants: mathematical analysis of a two-step model involving a cooperative transition. J. Theor Biol 124(4):473–483
- Ohashi Y., Hiroshi K., Yoshinori S., Hiroshi I., Nobuko Y. 2011. The phenology of cherry blossom (Prunus yedoensis “Somei-yoshino”) and the geographic features contributing to its flowering. Int J Biometeorol (2012) 56:903–914
- Cesaraccio, C., D. Spano, R. L. Snyder, and P. Duce. 2004. Chilling and forcing model to predict bud-burst of crop and forest species. Agricultural and Forest Meteo. 126: 1-13.
- 日本氣象廳. 2012. さくらの開花日の変化 – 気象庁.











































