文/雷雅淇|泛科學主編
當我們能改善傳播資訊的介質,從而去影響內容產生者,科學新聞就不會再是由無聊的新聞稿改寫、劣質的翻譯外電和一抄再抄未經證實的謠言,而會是一道道好吃好玩又有營養的美味佳餚。
從那則未看先分享的科學報導說起
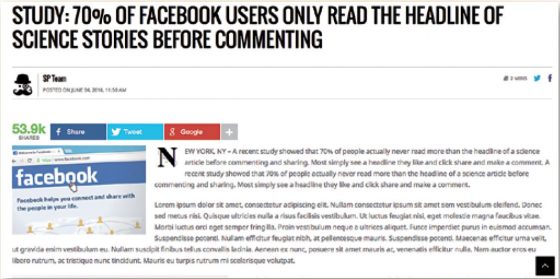
今(2016)年 6 月,The Science Post 刊登了一篇標題為〈研究指出:70% 的 Facebook 用戶在看科學報導時,只看標題就留言評論〉(Study: 70% of Facebook users only read the headline of science stories before commenting)[1],光是標題就已經令內容生產者們難過得心碎,更諷刺的是:這篇文章的內文其實是內容產生器捏造的假內容,而它卻居然有超過五萬次的分享[2][3]。
把鏡頭轉到棚內:《泛科學》在 2015 年的愚人節時,於 Facebook 上分享了一篇玩笑的科學報導〈治痔瘡,請把衛生紙對折兩次!〉[4],本篇文章在當時就有在內文中非常明顯地標註這是愚人節的玩笑;但觀看讀者的反應後卻意外地發現,相信這是真的科學研究的也不在少數。於是,我們之後寫了非常認真地痔瘡文來贖罪[5]。
這兩個有趣的事件,也讓我們一窺一些人們現在對於資訊的處理習慣:容易相信權威、「專家」下的結論,就算是閱讀文章就會看到的明顯錯誤,還是會有人未讀先分享;當然也有一定比例發現真相的讀者,是在拿著這支釣竿釣其他的魚。在 ACM SIGMETRICS 期刊一篇「真」的研究 Social clicks: What and whogets read on Twitter? [6],研究人員統計發現在 Twitter 上有 59% 的連結沒有被點擊就被轉推,也就是說這些人沒有閱讀過內容就把它分享出去了,而且是大部分的資訊都如此。
你可能覺得你是那些會把內容看完真心覺得不錯才真情推薦給親朋好友的閱聽人,但試想我們每天會接觸到多少的資訊?真的有辦法每一則都好好吸收然後處理嗎?這些資訊又是怎樣送到你我的面前?又是誰決定它重不重要?在這看似容易實則更難傳播內容的時代,需要有邏輯、有脈絡的科學新聞,但在這艱困的傳播環境中它可以生存嗎?

臺灣沒有科學新聞嗎?
翻開新聞,會發現在主流媒體當中也不是沒有科學新聞,雖然時不時會有讓人哭笑不得的新聞出現:用溫度計當尺來量雪的高度[7]、臺北高雄只要 15 分鐘的「光速」高鐵[8]、激素鳳梨吃太多人也會性早熟[9]、用睪丸進食的人齒怪魚和謙虛的苔蘚[10]⋯⋯。當我們苦笑過後,更應該要想的是:這樣理應很容易發現基本理論錯誤的科學新聞,怎麼還是經過了層層關卡而出現在你我面前;臺灣科學新聞的產製過程中,是不是遇到了什麼困難?

「科學是一個很長的故事,但新聞在意的卻僅在快門的一瞬間。」[11]
主流媒體面臨巨大的市場壓力,報導科學新聞吃力又不討好;況且,臺灣的記者大多不是理工科背景出身,要自行跨過科學新聞的高門檻談何容易,更別說還要追求效率、時效性和滿足娛樂性[12]。我們常會搖頭嘆息臺灣的科學新聞怎麼總是「謠言、外電、新聞稿」[10];但在設備、資源投入有限,臺灣媒體無法自製科學報導的情況下,轉譯無需額外付費的外電和國外媒體、現成的新聞稿,就變成科學新聞的來源[11];但又因為有科學背景的新聞從業人員較少,報導出來的科學新聞就會有關係錯置、忽略過程、便宜行事⋯⋯等情況發生[11]。
科學新聞產製過程困難的問題,也導致我們的科學新聞很「偏食」;想想你在看新聞的時候最常看到那種主題?馬上浮現在腦中的就是某某研究說吃什麼會導致什麼疾病、那裏有地震和颱風生成、有個很酷很棒的科技產物或許未來上市會改變我們的生活⋯⋯。不論是報紙或是電視,科學新聞有很大的比例都是醫療類型的報導,其次是地球航太和科技工程[13]。然後你也會發現,報導的大多是科學活動中的下游產物,這些內容已經有實際的產品或是對一般人的日常生活有影響力,那些還在實驗室建構中的科學理論的上游理論和中游研發的科學新聞,比例甚少[12]。
沒有資源投入讓優質的科學新聞產製困難,劣質的科學新聞讓閱聽人沒有好的典範可以閱聽和傳播,導致需求不被看見而資源難以投入;我們有可能打破這樣的惡質循環嗎?
讓科學新聞向上循環?請你跟我這樣做

1. 對眼前的資訊充滿質疑,沒有誰是全知全能的專家。
比起過往我們多從報紙、電視或是書本中接受資訊的時代,網路讓我們乍看之下有了更多主動的選擇;但社群平台、搜尋引擎等仍利用演算法決定什麼樣的資訊應該送到我們的面前,而且更不著痕跡,甚或是讓我們被過濾氣泡[13] 包圍而不自覺。我們真的有辦法抬頭挺胸大聲地說:所有資訊都是我們選擇而來,並且知道它的重要性和意義嗎?
而不管是在網路或是新聞中,很多事情我們都習慣信任所謂的「專家」替我們下結論,但這是極其危險的。先不論那些不管什麼事件都會被記者詢問任何意見的「專家」或是「網路觀察家」,在這專業極其細分的時代,沒有人能看得到事件的所有全貌,專家既使學有專精,但面對這個複雜的世界,沒有人能解答所有的問題。所以不要停止對眼前的資訊產生質疑,尤其是當你覺得它似乎有些陷阱,某些內容觸動了你內心的警鈴,或是有個「專家」告訴你他知道所有的事。
2. 奪回自己知的權利,拒絕對資訊做出膝跳反應
如果不能相信專家,又不能親信眼前看到的資訊,那我們該怎麼辦?盡自己的力量,試著層層解剖那些令人質疑的資訊吧!新聞常會把事情講得簡單:有毒的物質就該「零檢出」,致癌物超標就是對人體有害。但科學是複雜的,零檢出取決於你的檢測方法和儀器,致癌物超標也不等同於一定致癌。在面對被簡單處理的資訊時,別急著馬上「認同請分享」的公告周知,先停下來想想看,或是試著找找相關資訊,你會發現它跟你第一次看見時的樣貌有些不一樣。
3. 持續監督、不停傳播,好的壞的都不要只有自己知道
經過質疑、查找的不斷反覆練習,當我們越來越有「判讀力」,越來越不能接受眼前被斷章取義、誇大不實、下錯結論的惡質資訊時,該怎麼辦?不要只是笑完然後慶幸自己沒有上當,持續監督那些散播劣質內容的來源、並不停地將你知道的告訴身旁的人吧!
物質的傳遞需要介質,而謠言能不脛而走通常是盲目擴散居多。當我們能改善傳播資訊的介質,從而去影響內容產生者,科學新聞就不會再是由無聊的新聞稿改寫、劣質的翻譯外電和一抄再抄未經證實的謠言,而會是一道道好吃好玩又有營養的美味佳餚。
參考資料:
- SP Team (2016, April). Study: 70% of FACEBOOK users only read the headline of science stories before commenting. The Science Post.
- 阿咖(2016 年6 月)。你也被這篇文騙到了嗎?「 70% 網友只看標不看內文」。地球圖輯隊。
- Dewey, C (2016, June). 6 in 10 of you will share this link without reading it, a new, depressing study says. Washington Post.
- Mo(2011 年4 月)。治痔瘡,請把廁紙疊兩次!果殼網。
- 蔣維倫(2015 年6 月)。如坐針氈,讓你有「痔」難伸的痔瘡。泛科學。
- Gabielkov, M., Ramachandran, A., Chaintreau,A., & Legout, A. (2016). Social clicks: What and who gets read on Twitter? ACM SIGMETRICS/IFIP Performance2016.
- 糗!記者溫度計錯當尺 網友笑翻(2014年2 月)。自由時報。
- 有美國最新的超級高鐵逼近光速的八卦嗎?(2016 年5 月)。批踢踢實業坊。取自科學新聞解剖室(2015 年4 月)。
- 激素鳳梨吃太多,恐致孩童性早熟?泛科學。
- 顏聖紘(2016 年8 月)。從「用睪丸進食的魚」到「謙虛的苔蘚」, 臺灣媒體缺的不只翻譯人才。鳴人堂。
- 黃俊儒(2014)。別輕易相信!你必須知道的科學偽新聞。臺北市:時報出版。
- 林艾潔、黃靜蓉(2014)。科學新聞之資源基礎觀點分析:以臺灣主流媒體為例。傳播與社會學刊,28 ,23–61。
- 張郁敏(2013)。什麼樣的科學新聞內容會受新聞媒體青睞?報紙與電視科學新聞媒體顯著性之決定因素初探。新聞學研究,117 ,47-88。
- 新媒體世代(2015)。誰該為Facebook的「過濾氣泡」現象負責?泛科學。

本文摘自《科學研習》月刊第 55 卷第 10 期,2016 年 10 月號。