今 (2019) 年二月,德國海德堡大學附屬婦科醫院發布新聞稿,聲稱教授索恩 (Christoph Sohn) 的研究團隊研發出一項新技術:以「抽血檢查」偵測乳癌細胞。
什麼?!只要抽血就可以知道有沒有得乳癌嗎?
該篇新聞稿內容指出,雖然這項技術不能直接取代乳房 X 光攝影檢查,但可以當作早期檢測,且偽陽率(沒有乳癌卻被判斷成有乳癌的機率)只有乳房 X 光攝影檢查的一半。當時的新聞稿宣稱這項檢測是「乳癌檢測的重大里程碑」,並將在年底投入臨床應用。
奇怪的是,索恩同 (2) 月在德國杜塞道夫的另一場研討會中,說法又大不相同。根據德國線上雜誌 MedWatch 的報導,索恩的演講投影片上顯示該測試的特異度為 45~73%,相當於高達 55% 的偽陽率,幾乎是每兩位女性就有一位會被判斷為乳癌患者。看來這個以抽血看有沒有得乳癌的方法還不是太可靠註1。
哪個環節出了問題?科學公關化妝化過頭
從上述的案例中,我們可以發現,這項「用血液檢測有沒有得乳癌」的檢測方式,明明有高達 55% 的偽陽率,卻在醫院發布的新聞稿中,被說是「乳癌檢測的重大里程碑」,嚴重地誇大了好幾個層級。但究竟為什麼新聞稿跟原始研究可以差這麼多呢?
這攸關於「公關」的角色。
在科學研究組織中的公關單位,必須擔負「提升組織名譽」的重擔。現在各大學相互競爭學術排名的情況下,大學公關透過各方管道(包含亮眼的科學研究成果)來「行銷自己」變得十分重要。因此,科研組織中的公關不僅要能夠把高深複雜的科學知識講到民眾可以理解,還要順勢「宣傳自己」一波,幫科學研究成果「化個妝」,替學校爭取好名聲。

然而,科學公關作為「學術界」和「媒體界」的橋樑 (Sumner et al, 2014),時常會遇到裡外不是人的窘境。公關單位一方面必須把科學知識講簡單,一方面又要擔任科研組織的化妝師,行銷自己、提高組織的知名度;因此常常沒辦法站在客觀與批判的角度檢視科學研究成果。容易造成問題的情況是,有時候公關單位會化妝化過頭,過去研究顯示,學術單位公關發布的新聞稿也常有機會成為錯誤的資訊來源本身。
誇大的科學新聞不是記者的錯?公關也可能參一腳
英國卡迪夫大學腦研究成像中心 (Cardiff University Brain Research Imaging Centre) Petroc Sumner 教授的研究團隊發現,與健康科學的新聞中,容易出現三種常見的錯誤:
- 過度延伸的建議(呼籲讀者改變行為)(exaggerated advice)
- 把「相關」描述成「因果關係」(exaggerated causal claims)
- 把「動物」研究成果不當延伸,應用在人類身上 (exaggerated inference to humans from animal research)
然而,研究發現這些在科學新聞中被扭曲、誇大的部分,往往在公關稿就已經出現了。

研究團隊從英國排名前 20 名的大學取得共 462 篇和健康相關的公關稿,再分別往前往後挖看看同一個研究的原始論文和科學新聞。(原始論文是一定有啦,但有些公關稿不一定會成為新聞題材。)
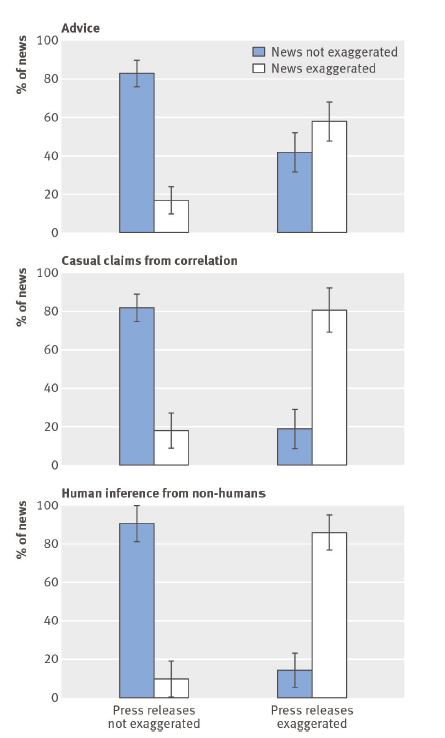
研究團隊比較了原始論文、公關稿和科學新聞三種版本的文章,發現有 40% 的公關稿含有過度延伸的建議;33% 的公關稿含有把「相關」描述成「因果關係」的錯誤;36% 的公關稿含有把「動物」研究成果不當延伸,應用在人類身上的錯誤。
研究更進一步顯示,當公關稿含有這些誇大的錯誤時,分別有 58%、81% 和 86% 的科學新聞會也一樣會延續這三種類型的錯誤。
讀科學新聞要小心,遇到誇張的研究結果要有所警惕
文章看到這裡,或許你會很驚訝:「原來我以前都錯怪記者了,公關稿也可能有過度延伸的問題。」但這項研究結果也不是要你開始改罵公關單位,畢竟公關單位常常有和其他大學競爭的壓力。
但其實民眾如何理解科學新聞的內容,會直接影響到民眾的實際行為。因此,科學新聞怎麼描述健康相關資訊,真的是一件不能馬虎的事情。(就好比看到抽血可以驗乳癌就開心以為不用去照 X 光檢查,或是看到「常咀嚼固態食物可預防失智」就不顧吃什麼健康不健康的嚼嚼就對了……)

不過更聰明的你一定想到了這個解方:當我們看到誇張的科學研究結果,別看到標題就自己腦補胡亂相信,要記得仔細看看內文,有沒有把相關研究講成因果關係,或是把動物研究結果延伸到人類身上(畢竟只有 10% 的非人類研究結果可以成功類推到人類身上)。如此一來,就算遇到了懸疑的科學新聞,你也有可以判斷真偽的能力!
註解
- 儘管索恩在研討會的記者會中遭受質疑,他仍拒絕回答任何與該測驗「偽陽率」相關的問題。五月,海德堡大學附屬婦科醫院認為,索恩必須為他的錯誤言論負責。經過幾個月的調查,大學委員會在上個月底舉行記者會,說明調查結果證實索恩宣稱以抽血檢測乳癌是「嚴重的不當行為」。根據報導,索恩已遭停職(包含教學與研究)3 個月,並即將接受大學的紀律調查。
參考資料
- German university finds ‘severe’ misconduct by researcher who promoted questionable cancer blood test. Science, 2019.10.25
- FORSCHER DES UNIVERSITÄTSKLINIKUMS HEIDELBERG ENTWICKELN ERSTEN MARKTFÄHIGEN BLUTTEST FÜR BRUSTKREBS. Newsroom UKHD, 2019.2.21
- Sumner, P., Vivian-Griffiths, S., Boivin, J., Williams, A., Venetis, C. A., Davies, A., … & Boy, F. (2014). The association between exaggeration in health related science news and academic press releases: retrospective observational study. Bmj, 349, g7015.