本文轉載自宜特 小學堂〈矽光子可靠度驗證該依循哪個規範?當老規範GR-468遇上新科技,系統如何順利Bring-up?〉 ,如果您對半導體產業新知有興趣,歡迎按下右邊的追蹤,就不會錯過宜特科技的最新文章!
矽光子晶片量產元年已在眼前,但業界至今仍缺乏一套專屬標準,最權威的依據是問世逾廿年的經典規範「Telcordia GR-468」。面對日新月異的矽光子與 CPO 技術,這套「老規範」是否還能扛得起驗證重任?
台積電在 2026 年技術論壇中明確指出,隨著製程邁入 2 奈米奈米片(Nanosheet)時代,AI 算力的延續必須仰賴《晶片版三層蛋糕論》 ,涵蓋運算、異質整合與 3D IC,以及最關鍵的「光子(Photonics)」。誠如台積電高層所言:「談到運算能力,電子無可匹敵;但談到訊號傳輸,光子則更勝一籌 。」
未來資料中心的傳輸勢必由電子轉向光學,而台積電的矽光子先進封裝平台 COUPE(緊湊型通用光子引擎,Compact Universal Photonic Engine) 也已搭載到基板上,並宣告今年將進入量產階段。NVIDIA、Intel、Broadcom 等大廠也爭相搶進 CPO(Co-Packaged Optics,共同封裝光學)賽道。
然而,當光電元件從「獨立模組」 轉向「高度整合」 的晶片封裝時,可靠度驗證的複雜度已不可同日而語。
面對工程師最常問的:「那規範在哪裡?」
目前業界針對 CPO 或矽光子產品還沒有單一且完全專屬的標準, 最權威的依據仍是經典的 Telcordia GR-468。但在高度整合的趨勢下,這套傳統驗證邏輯正迎來前所未有的挑戰。
之前我們已從矽光子元件組成與決定效能的關鍵(閱讀更多:「光」革新突破半導體極限 矽光子晶片即將上陣 ),進而分享對應的解決方案(閱讀更多:矽光子開發遇到什麼瓶頸? ),以及如何突破矽光子量產的核心難關(閱讀更多:矽光子CPO量產見曙光!從「漏電」到「漏光」如何迎刃而解? )。
亦針對光子積體電路(PIC)的五大關鍵部件,詳細剖析其常見故障模式(閱讀更多:為什麼 AI 晶片需要「光」?拯救超貴晶片的「矽光子眼科醫生」大解密! )。
一、Telcordia GR-468 究竟是什麼規範?還堪用嗎? 電信級 Telcordia GR-468 是由通訊權威機構 Telcordia Technologies (前身為為美國貝爾通訊研究公司 Bellcore)於 2004 年釋出的核心規範(GR-468-CORE)。儘管它問世已久,但其嚴謹的測試架構,至今仍是全球矽光子元件進入 AI 伺服器供應鏈時,最被系統客戶採用的可靠度驗證依據。
Telcordia GR-468 這項規範的核心價值在於其「跨領域的覆蓋力」 。
(一) 涵蓋完整光電鏈: 包含雷射二極體(Laser Diode,簡稱 LD)、光電二極體(Photodiode,簡稱 PD)、電吸收調變器(Electro-Absorption Modulator,簡稱 EA Modulator)和 LED 等相關光電元件。
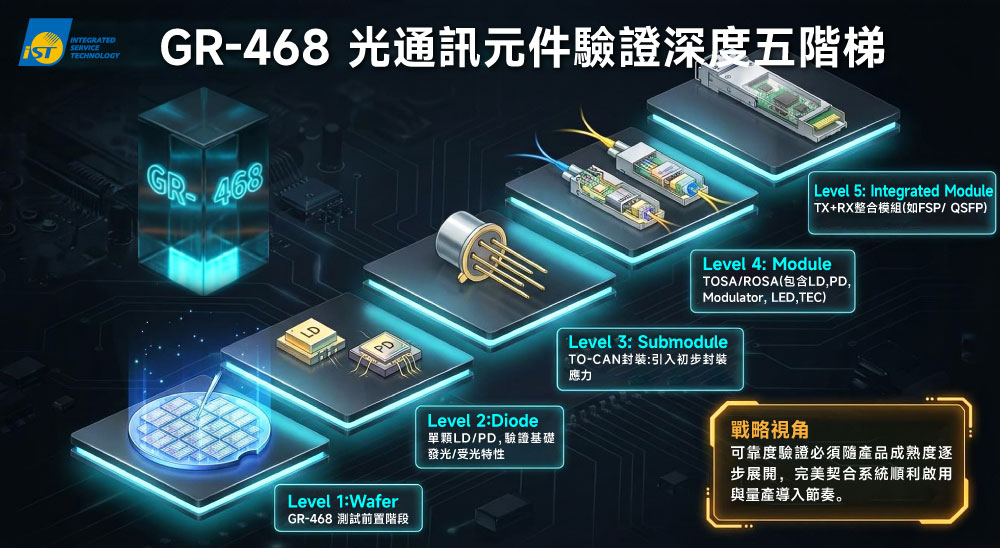
(二) 封裝層級延伸: GR-468 依「組裝完成度」將待測物分為多個封裝層級(Assembly Level),測試對象可從晶圓到單一晶片,延伸至次模組,仍至整顆光模組,從不同層級對應不同測試條件與驗證深度。
GR-468規範示意圖,從晶圓到最終整合模組的完整生命週期,可分為五個驗證階梯。圖/宜特科技AI輔助生成製作。 (三) 環境模擬: GR-468 規範嚴格區分機房溫控環境(Central Office,簡稱 CO)與戶外無空調環境(Uncontrolled Environment,簡稱 UNC),不同環境對應不同溫度範圍與應力條件,讓驗證條件貼近真實系統場景,這正是系統端最在意、也最容易在早期被低估的風險來源。
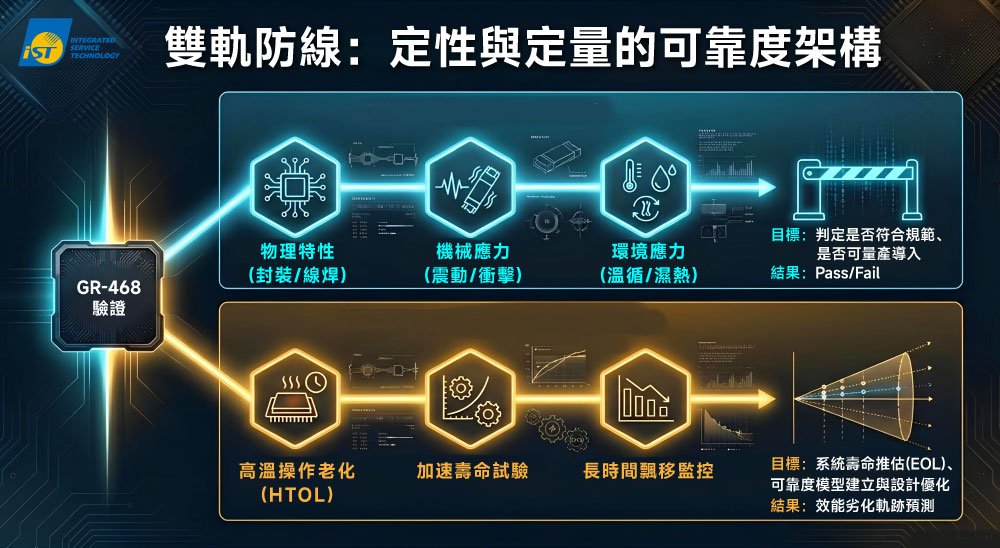
(四) 定性與定量並重: Telcordia GR-468 除了可藉由「定性測試(Qualitative Tests)」判別是否符合規範(Pass 或 Fail)、是否可量產導入,亦可透過「定量測試(Quantitative Tests/ Aging Tests)」進行壽命推估(EOL)、可靠度模型建立與系統設計優化。
GR-468 兼顧定性和定量測試,不只可判別是否可量產導入,亦可推估出系統壽命。圖/宜特科技AI輔助生成製作。 以上這些 Telcordia GR-468 的設計,讓可靠度驗證能隨產品成熟度逐步展開,非常符合矽光子系統 Bring-Up 與量產導入節奏。
二、為什麼矽光子元件跑完規範,系統還是掛了? 看來 GR-468 規範仍然寶刀未老,但為何在實際應用中,許多跑完規範的矽光子系統仍無法順利運作呢?
這是因為在 CPO 架構下,光、電、熱、機械四者間的交互影響極其複雜。傳統「通過/不通過(Pass/Fail)」的判定邏輯,已不足以偵測高度整合後產生的深層失效模式。
以下是矽光子走向系統整合時,最令工程師頭痛的兩大硬傷:
(一) 熱力學矛盾與 ELS(外置光源)的妥協: 負責核心運算的 GPU(圖形處理器)屬於高功耗熱源,運作溫度動輒攀升至 100°C,這與對熱極度敏感、工作溫度需壓制在 70°C 以下的光傳輸元件(雷射光源)產生了嚴重的熱力學矛盾。雷射光源受熱會導致啟動閾值電流指數型增加、波長變長(紅移),並加速元件內部缺陷擴散而縮短壽命。
為了化解這項矛盾,業界傾向 ELS(External Laser Source,外置光源),將雷射光源像電池一樣外掛。但這衍生了以下風險 :
1. 高功率運作的老化(Aging under High Power):
ELS 需供應極高光功率給多個矽光引擎,雷射在極高驅動電流下運作,內部的晶格缺陷會隨時間與高溫擴大,形成「暗線缺陷(Dark Line Defects)」,導致發光效率劇降。
宜特建議可執行HTOL(高溫操作老化測試)。在 85°C 或更高溫下持續通電數千小時,觀察光功率衰退曲線,以推算出產品是否能支撐 10 年以上的系統壽命。
2. 連接介面的脆弱性:
ELS 增加了連接介面,保偏光纖(PM Fiber)的過度凹折,或是接頭沾染微塵、插拔產生機械微裂痕,都會導致插入損耗(IL)升高,成為系統潛在的故障點。
(二) 異質整合的「應力」拉扯(CTE Mismatch,熱膨脹係數失配): 矽光子晶片內含矽、三五族化合物、玻璃光纖與金屬,這些材料受熱後的膨脹程度(CTE)差異極大。例如矽晶片(2.6)與 PCB 板(15)甚至 UV 光學膠(50~100)之間巨大的應力差,在發熱時會產生劇烈拉扯:
1. 次微米級的對位挑戰:
光纖陣列(FA)與矽光晶片耦合時,對位精度要求在次微米級。一旦受熱產生Warpage(翹曲)或應力拉扯,輕則光路偏移,重則導致結構 Delamination(剝離)。
2. 膠材劣化與水氣滲透:
高溫高濕環境會導致固定用的 UV Epoxy(光學膠)發生老化、膨脹或潛變,直接造成訊號損失。
隨著矽光子與 CPO 架構的快速發展,可靠度驗證不該只是為了拿一張合格證書,而是要支撐系統長期的穩定運作。
本文出自 www.istgroup.com







































{kind=link}