


- 文 / Brian
不只是學術研究,我們常常會用「統計數據」來作為觀察世界的佐證,但我們在看待數據時要非常小心,因為詮釋方式的不同,其「統計學」所呈現出來的結果,有時候反而可以誤導別人。不信?就讓我們用一些例子,來看看「數據統計」有時不是我們想的那樣。
是數據真的很美,還是只是過擬合?
我們先介紹一個常犯的錯誤:過擬合(overfitting,或稱過適、過度擬合)。過擬合指的是在統計學中調適一個統計模型時,使用過多參數。具體來說,擬合就是把平面上一系列的點,用一條光滑的曲線連接起來。因為這條曲線有無數種可能,從而有各種擬合方法。所以其實你只要有心,任何數據都可以擬合成任何函數。
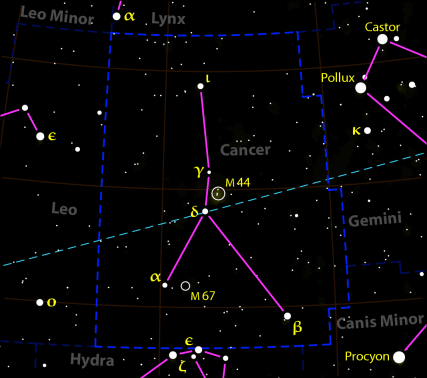
夜空中的星座就是一個很好的例子,明明只看到幾個點,但非要將其擬合成某種動物,看巨蟹座的樣子更像一支叉子或彈弓吧,怎麼會看成螃蟹呢?
再來如果數據量足夠多,你幾乎可以在任何事情間發現相關性,甚至可以說:告訴我你想要什麼結論,都可以給擬合出來。統計學中有個名詞叫做偽相關,指在兩個沒有因果關係的事件,可能基於其他未見的潛在變數,顯示出統計學上的相關,讓人很容易猜想「兩個事件有所聯繫」,然而這種聯繫並不能通過更加精細的檢驗。
相關不等於因果!
舉個例子:當冰淇淋銷量最高的時候,也是海邊的溺水事故發生得最多的時候。
我們可以很容易的理解為因為天氣熱,所以很多人去海邊玩,人潮多自然溺水事故也會多, 冰淇淋銷量增加也是由於天氣熱導致的,並非是「因為」冰淇淋賣得好,「所以」導致溺水事故增加。

兩組數據的變化成正相關不一定代表它們有因果聯繫,x、y 成正相關還可能是因為它們都隨 z 成正比,而 x 和 y 彼此之間是沒有因果關係的。所以在看統計數據時要非常小心,諸如基因改造食品、手機輻射、微波加熱是否會有致癌風險等等,就必須特別注意:這些推論究竟有沒有因果關係,還只是以統計學來包裝的偽相關呢?
諾貝爾獎與巧克力之間的距離?
曾有人在無意間把本國的巧克力消費量和本國諾獎得主佔總人口數的比例進行對比後意外地發現這兩者竟然呈正相關,也就是說越愛吃巧克力的國家諾獎的比例也越高,特別是瑞士人超愛吃巧克力也拿了超多諾獎。
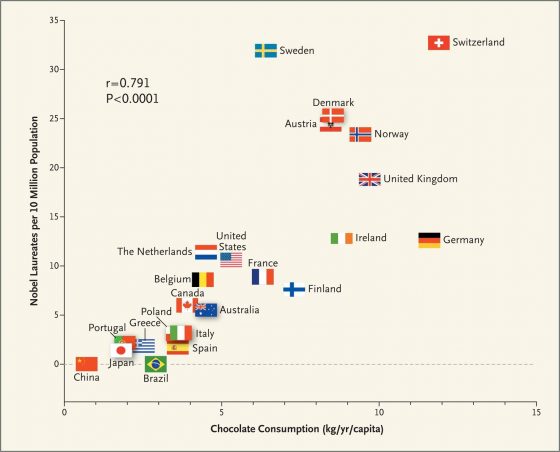
當然我們可以很簡單的理解,由於巧克力消費量與國家的富裕程度相關,而高品質的科研也與國家的富裕程度相關。因此巧克力會與諾獎得主比例相關,但是顯然其中並不存在因果關係。
所以如果你有個命題,而且有數據可以支持此命題,那你要切記,數據和理論吻合的 好並不代表你的推論就是對的,「數據吻合的好」只是充分而非必要條件。諾獎和巧克力就是個很好的例子,有時我們會得到很荒謬的結論。

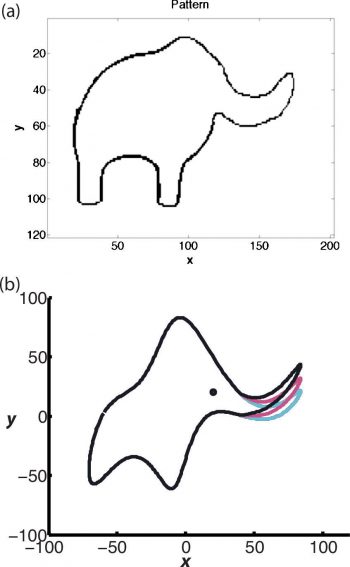
「用四個參數我可以擬合出一頭大象,而用五個參數我可以讓牠的鼻子擺動」
2004 年戴森*在 Nature 雜誌上寫了一篇名為「A meeting with Enrico Fermi」的文章,回憶 1953 年他由理論計算得到了與費米的實驗觀測值十分相符的結果後馬上跑去見費米。當戴森跨進費米的辦公室並遞上自己的計算結果時,費米掃了一眼就把它放下,費米說:「做理論物理學的計算有兩種方式。一種是我喜歡的,就是要對你正在計算的過程擁有一個清晰的物理圖像。另一種是得到精確而且一致的數學形式體系。而這兩者你都不具備。」戴森當時有點驚呆了,但他還是斗膽問費米,為什麼他的理論算不上是一致的數學形式體系。
- 註解:戴森最著名的成就是證明了施溫格和朝永振一郎發展的變分法方法和費曼的路徑積分表述等價,為量子電動力學的建立做出了決定性的貢獻,這三人在1965年獲得諾獎,學界普遍認為戴森值得拿諾獎,不過戴森還活著,活著就還有希望
費米反問道:「你們在計算過程中引入了多少個任意參數?」戴森回答說四個。於是費米便說:「我記得我的朋友馮·諾依曼曾經說過,用四個參數我可以擬合出一頭大象,而用五個參數我可以讓它的鼻子擺動。」戴森承認,與費米的這次會面是他人生的一個重大轉捩點,50 年後回頭再看,費米是極富遠見的,當年戴森所看好的理論則走到了盡頭。
儘管費米本人沒有活到夸克模型問世的那一天,但是他出眾的物理直覺告訴他,戴森等人所採用的含有四個參數的理論一定是錯誤的。費米的一席話及時阻止了戴森和他的團隊走入一個死胡同,從而使他們的興趣轉向更有意義的科學問題。這篇文章還有一個副標題「 How one intuitive physicist rescued a team from fruitless research(一位富有直覺的物理學家如何從死胡同中拯救了一支團隊)」。
只要「仔細」處理數據就可以讓暗物質消失或出現
暗物質的組成成分和其是否存在一直都是物理學界的大問題,去年三月時耶魯大學的 Dokkum 教授宣稱他們發現了一個缺乏暗物質的星系,但這文章一發布就接連跑出一堆文章攻擊他們數據分析太粗糙。因為當在追蹤這麼小的樣品時,速度的不確定度和真正測量的彌散速度是在同一個數量級,所以最終結果就對所使用的技術和處理不確定度的方式極為敏感。

也有人表明說會得到星系缺乏暗物質的結果是因為這些質量估計的不確定度被大大低估了。而且如果把 Dokkum 處理數據的方式套用在一個我們已經充分研究的星系上,會得出這樣的結論:它具有「過大的」暗物質暈,或者它缺少暗物質。你想要得到怎樣的結論取決於你怎麼估計質量,所以才會說只要「仔細」處理數據就可以讓暗物質消失或出現。而且如下圖所示,他們就是直接忽略了一組數據,無視藍圈的那些數據不做擬合。

還有人跑出來狠狠批評 Nature 就喜歡收吸人眼球的文章,而非最符合科學方法的文章。甚至開玩笑說如果同一組數據,用兩種不同的分析數據方式,得到兩個結論,一個是此星系含有暗物質、另一個是此星系缺乏暗物質,那缺乏暗物質的文章更有可能被登出來,因為這能製造大新聞。
對統計學的批評古已有之,已經有不少統計學家指出 p-值使用中存在大量的缺陷,甚至開始轉而質疑用統計學方法計量科學發現。美國國家統計協會(ASA)作爲統計學標準的倡導者給出了一個使用 p-值的參考性聲明。他們認為:「這是科學中最骯臟的秘密:使用統計假設檢驗的「科學方法」建立在一個脆弱的基礎之上。」「假設檢驗中用到的統計方法比臉書隱私條款的缺陷還多。」
科學權威的數據造假
除了統計學本身的問題外,更過分的是還有些科學家會進行數據造假來得到他們想要的結論,歷史上曾有不少知名科學家也做過數據造假的事,以下舉幾個例子:
1919年愛丁頓在西非普林西比島觀測日全食,觀察到引力透鏡現象並以此證實廣義相對論,但後世的科學史家們對於愛丁頓的數據感到懷疑,認為他們肯定做了一些操作來篩選數據。 還有密立根做了著名的油滴實驗測量來測量單一電子的電荷,也因而獲得1923年的諾貝爾物理學獎,但後來被踢爆他從 140 次觀測中只採集那些對他有利的漂亮資料,而不利的資料則一概刪去,最後只發表 58 次觀測結果。
道爾頓被認為是歷史上第一個從實驗上證實了化學反應中各個物質總是按照一定的比例進行反應的。這實際上成為物質是由原子或分子組成的間接的證據,在物理、化學乃至整個科學發展史中都具有十分重要的地位。也許有些令人啼笑皆非的是,道爾頓的發現實際上具有某種虛假的成份。在道爾頓的年代,進行化學實驗的儀器與設備還十分簡陋。到了二十世紀,有很多對於科學史有興趣的科學家嘗試著按照道爾頓當年的記載,運用當時的儀器來重複道爾頓的實驗。這些科學家的結論是:以道爾頓當時的條件,他決不可能做出如此精確的實驗。因此他們認為,幾乎可以肯定的是,當時道爾頓實際上「人為地」改造了實驗資料來為他的結論辯護,儘管他的結論仍然是具有劃時代意義的。
2018年十月時哈佛醫學院的知名心臟專家Anversa被爆出其所著的31篇論文皆涉及實驗數據造假,而校方經決議後撤回他所有論文,但心肌幹細胞造假這事件也反映了一個問題,實驗科學的數據如果審稿人不親自重複一遍可能也很難發現有造假,而我們通常也會傾向於相信權威。
我們在日常生活中常常會遇到很多「統計數據」,許多人更是開口閉口地提到「大數據」。甚至有人認為信數據者得永生,這些數據主義的人們覺得宇宙是由資料流所組成的,任何現象或實體的價值就在於對資料處理的貢獻。而在本文中給大家介紹了一些不合適的統計學方法和忘記因果關係所導致的謬誤,最後還指出權威學者也有造假的可能,我們不該迷信權威,期許大家在大數據時代都能不被統計學給誤導!
參考資料:
- Franz H. Messerli. Chocolate Consumption, Cognitive Function, and Nobel Laureates.
- Jürgen Mayer. Drawing an elephant with four complex parameters.
- Freeman Dyson. A meeting with Enrico Fermi.
- Pieter van Dokkum. A galaxy lacking dark matter.
- Nicolas F. Martin. Current velocity data on dwarf galaxy NGC1052-DF2 do not constrain it to lack dark matter.
- Chervin F. P. Laporte. Reconciling mass-estimates of ultra-diffuse galaxies.
- Riccardo Scarpa. Reply to the claim by van Dokkum et al. for a galaxy not containing dark matter.
- Ronald L. Wasserstein. The ASA Statement on p-Values: Context, Process, and Purpose.





































#/media/File:Cancer_constellation_map_black.png){kind=link}