上一篇關於TNR與捕捉移除效果比較的文章,我們看到了在沒有棄養的前提下,要想降低整體流浪動物數量,捕捉移除的效果比TNR的效果好。
但你一定也發現了,那一篇研究中假設流浪動物可以無限制的繁殖,沒有食物或空間不足的問題,沒有動物太多生育率下降的問題,什麼都沒有。
再加上研究中又沒有包括棄養因子,而且還把整個族群都設定為雌性,而且還只能選擇TNR或捕捉移除其中一個管理手段不能夠雙管齊下,怎麼想都很不實際。
『果然是不問世事閉門造車的象牙塔研究!』你可能會這麼嗤之以鼻。
說得好。
那我們就來看看2009年的這一篇族群動態模擬的研究吧。
因為這一個研究真的有點硬,所以我把結論先公佈在這裡:
結論就是,即使是一個五百多隻流浪動物的族群,在不做任何處理,也沒有任何移入個體的狀況下,25年後動物數量當然就差不多逼近最大承載量(七百多隻)。
而如果有做捕捉移除或TNR或雙管齊下,假設做到了75%的強度並且每年持續,那麼25年後的動物數量會降到350隻左右。
但是,一旦有移入個體的存在,就算一樣對整個族群做到75%的處理強度,25年後的動物數量也幾乎不會下降,甚至還會上升,就跟沒處理的結果幾乎一樣,可以說處理所花的時間金錢和心力都丟到水裡去了。
所以,要想做些什麼讓現有的流浪動物數量下降,第一要務就是「不要讓外來個體移入」,否則的話再大的處理強度都只是原地踏步而已。而台灣既然是個島嶼,那麼對整個台灣的流浪動物族群來說,外來的移入個體就是「棄養」的個體啊。不杜絕棄養,做什麼都只是白費力氣永遠看不到效果啊!!
好了,結論就是這樣。如果你想知道這個結論怎麼來,你可以繼續看下去。

這篇2009年的研究就跟2004年那一篇一樣,也是用了數學模型來模擬一個流浪動物族群在不同的捕捉移除、TNR、以及兩者雙管齊下的強度之下族群的增長率。
既然是個比較新的研究,當然在模型上面有長足的進步。2009年的這一篇採用的數據當然更為細膩精確,而且現實生活中該有的因子大概都考慮進去了。
他們的流浪動物模型是這樣的:
- 所採用的數據來自德州Caldwell這個小鎮的流浪貓族群調查。根據密度跟小鎮面積來計算,流浪動物的初始數量為520隻(而已!!)。
- 流浪動物族群中雄雌各半,生下來的幼體也是雌雄各半。
- 雄性
不會生小孩生育率當然是0。雌性的生育率則是由小鎮上完全野化的流浪貓(每年生1次,一次有1.75隻幼仔可以活到12週大)和半野化的流浪貓(每年生1.6次,一次生2.75隻幼仔可以活到12週大)平均而得,因此雌性生育率為每年生出3.075隻可以活到12週大的幼體。 - 雄性的年死亡率為43%,雌性的年死亡率則是12%。假定結紮與未結紮的個體死亡率相同。
- 經過一番我看不太懂的計算定出這個小鎮的最大承載量為724隻,並且假定它不會改變。並且因為密度依賴因子的存在,當流浪動物數量漸漸接近最大承載量的時候,生育率就會漸漸下降,當流浪動物數量等於最大承載量的時候生育率就降為0,大家都生不出來。
- 這個族群並不封閉,因此會有外來的移入個體。移入的個體假定都是成熟未結紮個體,雄雌各半。而每個時間點上能夠移入的最大數量,就等於最大承載量跟當下的流浪動物數量之間的差距(也就是說滿了就滿了外來動物沒有硬塞進來這回事)。
- 模型中假定雄性與雌性一樣好抓,因此兩個性別的流浪動物個體被抓去做TNR或移除的機率是一樣的。

有了這些基本參數之後,模型就根據第一年的動物數量(520隻),開始一年一年的運算每一年的「結紮雄性+未結紮雄性+結紮雌性+未結紮雌性」的總數,也就是流浪動物的整體數量。計算公式很複雜,但我們只要知道不同性別的結紮個體數量和非結紮個體數量是分開計算而得,而且公式裡有包含新生幼體、新移入個體、自然死亡個體、捕捉移除或TNR的個體就可以了。
模型裡設定了捕捉移除和TNR單獨使用、以及混合使用的四種不同強度(0%、25%、50%、75%)。強度為0%的時候就是完全不管不處理;強度為25%的時候就是每年固定處理當下的25%未處理動物;50%和75%也是以此類推。模型中另外設定了一個TNR跟捕捉移除各半,將所有個體通通處理的100%強度。總之,這樣下來總共有十一種不同強度和組合的處理狀況。
| 組合 |
捕捉移除率 |
捕捉結紮回置率 |
| 1 | 0% | 0% |
| 2 | 25% | 0% |
| 3 | 0% | 25% |
| 4 | 12.5% | 12.5% |
| 5 | 50% | 0% |
| 6 | 0% | 50% |
| 7 | 25% | 25% |
| 8 | 75% | 0% |
| 9 | 0% | 75% |
| 10 | 37.5% | 37.5% |
| 11 | 50% | 50% |
然後,別忘了這個模型有模擬外來移入個體的情況。模型會在最高移入率為0%、25%、50%(註)的情況下,把這十一種狀況都跑個二十五回,計算25年後的流浪動物總數以及雌雄個體數量。
(註:這個意思就是說,以第一年為例,520隻的既有個體距離724隻的最大承載量還有200隻的「空位」,而「最高移入率」就是指最多能有多少移入個體去填滿這個比例的空位。以最高移入率為25%來說,移入個體就是不超過200*25%=50隻。若是最高移入率為50%的情況,那第一年會搬進來的移入個體頂多是一百隻。當族群越接近最大承載量的時候,空位當然就越少,所以可以搬進來的外來個體也就很少很少)
模擬出來的結果,真的讓人很不忍卒睹。
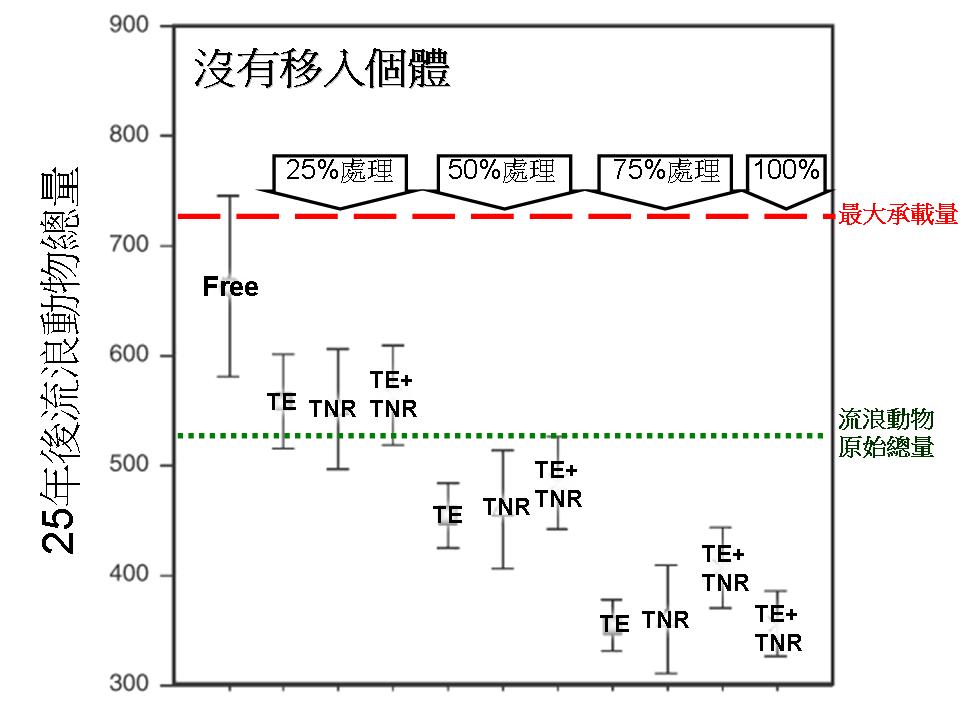
不意外地,在沒有任何移入個體,也不做任何處理的狀況下,25年後的流浪動物數量會逼近最大承載量。
然後,在這個比較接近現實的模擬中,捕捉移除降低流浪動物數量的效果雖然還是比TNR好,但已經不是2004那一篇研究裡那麼壓倒性的勝利。
在這個模擬中,在沒有任何個體移入的狀況下持續做到了75%的處理強度持續25年,流浪動物數量最後是350隻上下,無論是採用捕捉移除或TNR或雙管齊下都一樣。(這是因為模型中採取固定比例的處理,而不是固定數量的處理,因此最後會達到族群動態上的平衡)
這還是沒有移入個體的狀況,一旦有了移入個體,那就更是難看了。
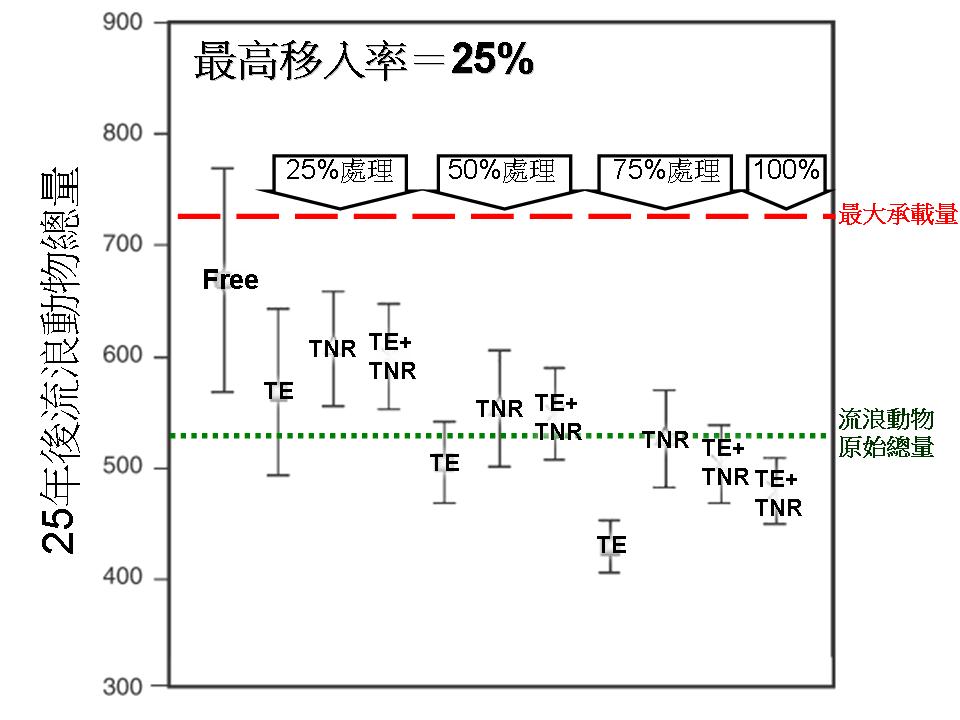
當最高移入率為25%(也就是說第一年大概會有50隻新的流浪動物從外地跑進來,之後每年跑進來的數量都不會高於這個數字)的時候,只有捕捉移除做到75%的強度,才能夠在25年後降低流浪動物數量到400出頭,其他的處理方式和強度則是通通沒有降低數量的效果。
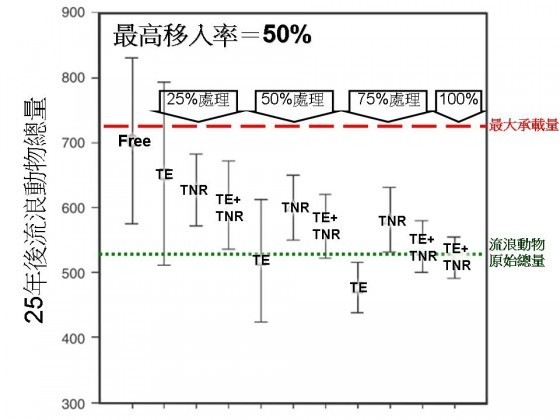
而當最高移入率為50%(也就是說第一年大概會有100隻新的流浪動物從外地跑進來,之後每年跑進來的數量都不會高於這個數字)的時候,即使是75%捕捉移除的強度,也只能讓流浪動物數量在25年後堪堪維持穩定,而其他的處理方式和強度則是通通擋不住流浪動物數量的上升。
所以結論就是:在這個接近現實的模擬中,沒有新的個體移入,無論是TNR或捕捉移除或雙管齊下都得要做到並且維持75%的強度,才能讓流浪動物數量在25年後有相當程度的下降。而一旦有新的個體移入,不用多,在這個500隻的族群當中每年最多不過是五十到一百隻的移入個體,就可以讓所有的處理手段和強度通通無效,只能眼睜睜看著時間精力跟金錢從手上溜走,卻永遠看不到流浪動物數量減少的可能。

看看這個研究,回頭想想台灣的狀況。這個模擬的族群不過才五百出頭隻,族群的最大承載量也不過是七百上下,搞了25年還是這麼不忍卒睹。對比起台灣十多萬隻的流浪動物在街頭,要真的等到流浪動物數量減少實在讓人等到心寒。
而且,不過是一開始族群十分之一的外來個體,就可以幾乎完全摧毀大把時間金錢跟心力投入產生的效果。
所以,要想做些什麼讓現有的流浪動物數量下降,第一要務就是「不要讓外來個體移入』」,否則的話再大的處理強度都只是原地踏步而已。而台灣既然是個島嶼,那麼對整個台灣的流浪動物族群來說,外來的移入個體沒有別的,就是從家裡丟出去的「棄養」個體。
在沒有棄養的狀況下,只要無法從一開始就達到50%以上的處理強度並且維持下去,捕捉移除或TNR也就已經無法減少整體流浪動物數量了。在有棄養的狀況下,想要降低整體流浪動物數量需要的處理強度則更是嚴苛。
我不知道台灣的棄養數量每年有沒有達到總族群量的十分之一,但是很顯然的,棄養會是一切努力成敗的關鍵。不管好棄養,做什麼TNR或是捕捉移除,很可能都只是白費力氣而已。我們不解決棄養這個重要病灶,過去一直都在做捕捉移除顯然白費力氣,但是現在推動TNR入法,期望以全面TNR的方式取代捕捉移除並且解決流浪動物問題,也可能只是另一種白費力氣而已。
如果你還是不相信的話,看看義大利跟夏威夷的告誡吧:「不藉由控制家貓的繁殖以防止棄養,所有的努力不過都是浪費金錢、時間跟精力而已」「降低棄養率顯然是個更能有效控制流浪動物數量的解方」。
要想搞定台灣的流浪動物問題,我看我們還是趕快把力氣花在杜絕棄養上頭吧。