-200x200.jpg)

人類必恭必敬稱家貓為「主子」,並自貶為「奴才」。陛下身體微恙,一團絨毛癱軟,表情內斂,叫貓奴如何揣測上意?懷疑牠受苦,便心急如焚。幾乎上演《還珠格格》裡,人家紫薇說沒事,爾康卻捨不得的虐心互動。貓咪說不定覺得:「……有這麼多人關心我,我已經不痛了……」人類仍在一邊:「可是,我好痛!」[1]

在治療人類時,醫護人員會用視覺類比量表(Visual Analogue Scale)、臉譜疼痛量表(Wong-Baker faces pain scale)或 FLACC 量表[註] 等工具,來評估患者疼痛的狀況。前二者靠病人自我評估,以數字或表情,象徵由舒適無恙,漸進到痛徹心扉的程度差異。 FLACC 則是醫護觀察嬰幼兒或無法言語溝通者,就其身體不適產生的行為變化來計分。[2] 儘管每個人敏感的程度不同,至少單一病患前後的得分,能相互對照出疼痛是否得到緩解,或者更加惡化。因此,這些量表均可視為有效測量疼痛的方法。
問題是有口難言,又行徑鬼祟的貓咪怎麼辦?人貓猜心的瓊瑤戲碼,自古不斷重演,沒完沒了。
直到有天,獸醫們看不下去了…
貓咪苦臉量表
2017 年的時候,加拿大蒙特婁大學 Paulo Steagall 副教授以及他的團隊,招募了一票被送急診的病貓。在得到飼主同意後,他們比較疼痛的病貓、服用止痛藥的病貓,還有健康貓咪的表情舉止,研發出「貓咪苦臉量表」(Feline Grimace Scale),並將結果發表於 2019 年的《科學報告》(Scientific Reports)。[3, 4] 其中列出幾個徵兆,可依級別給分,就此將貓咪的疼痛量化:
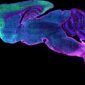
耳朵姿態(ear position):貓耳的尖角向外分開,並略為朝後旋轉。[3, 5]
圖/參考資料 5
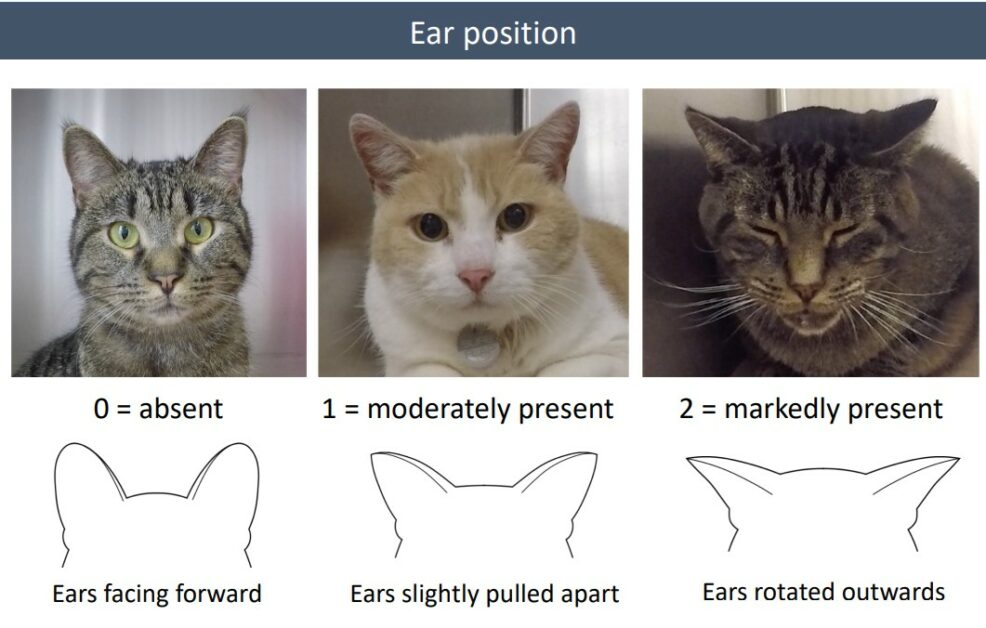
瞇眼程度(orbital tightening):上下眼瞼之間的空隙,小於眼睛的寬度,或是完全緊閉。[3, 5]
圖/參考資料 5
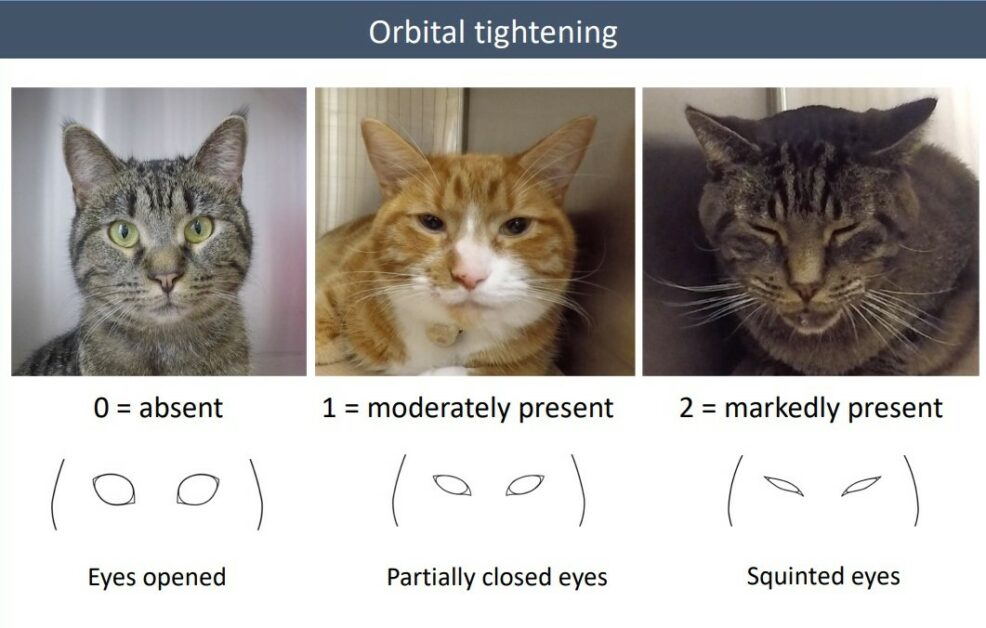
口鼻緊繃(muzzle tension):口鼻(即臺語所謂「喙管」的部位)由圓轉扁,而呈橢圓形。[3, 5]
圖/參考資料 5
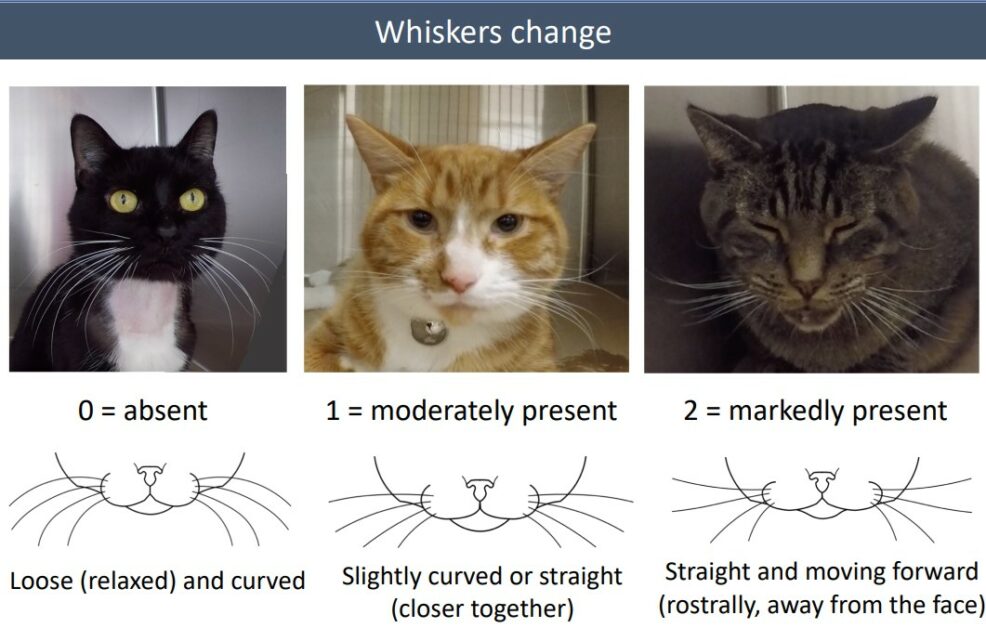
觸鬚變化(whiskers change):觸鬚從平常放鬆的圓弧,撐直且稍微向前。[3, 5]
圖/參考資料 5

頭部位置(head position):原本處於全身最高處的貓頭,降至低於肩膀,並往下垂。[3, 5]
圖/參考資料 5
貓臉疼痛辨識技術
目前受惠於物種專屬苦臉量表的,除了貓,還有鼠、兔、馬、羊、豬和貂等動物。受過訓練的獸醫,能精準判讀牠們的表情,用這些工具,來評估牠們的疼痛指數。隨著科技的進步,到了 2022 年《科學報告》期刊再次關懷貓咪的痛楚時,另一群科學家拿出「貓臉辨識技術」,試圖取代專業的肉眼觀察。[6]
圖/Serhan YH, HAKAN Ç, and RİFAT E. (2016) ’A comprehensive comparison of features and embedding methods for face recognition.’ Turkish Journal of Electrical Engineering and Computer Sciences, 24, 1, 24.
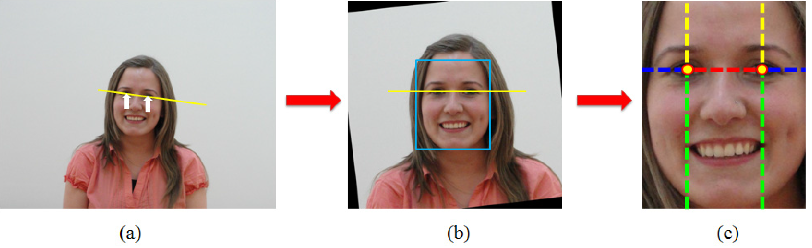
臉部校正

臉部校正是建立辨識系統的要務。先調整貓臉的特徵(landmarks,即照片上標有號碼的黑點),讓它們在空間中對齊,減少幾何上的變異,方便接下來的步驟進行。原則上,校正後的貓臉必須:[6]
- 在畫面正中央;
- 旋轉直到雙眼的連線呈水平;
- 尺寸都約略相同。
圖/參考資料 6 ,figure 1
模型1:特徵基準(landmark-based)

在找到貓臉的特徵後,依據「貓咪苦臉量表」的觀察部位,將貓臉特徵(黑點)分為:左眼、右眼、額頭與耳朵,以及口鼻和觸鬚,四個區塊向量。然後,多加一些貓鼻子的照片,進行「資料擴增」(data augmentation),[6] 彌補原始資料的不足,以強化機器學習。[7] 不過,團隊事後發現,這次的資料擴增,成效不彰。[6]
圖/參考資料 6 ,figure 3
處理這些照片的計算模型,是一種叫做「多層感知器」(Multi-Layer Perceptron)的人工神經網路(artificial neural network)。[6] 就像人的神經系統,有好多神經元相互連結,將輸入的資料從上一層送到下一層,經過多層運算後再輸出。[8, 9]
模型2:深度學習(deep learning)
研究團隊把大量沒有標註特徵的貓照,在校正角度和尺寸後,餵給 ResNet50 。[6] 這是一種有五十層的深度學習模型,早已預先訓練好怎麼逐層辨識貓咪的輪廓、曲線及其它識別特徵。[10] 套用該模型的同時,還要進行實驗需要的特定調整,例如:加上「痛」與「不痛」的分類標籤。[6]
貓的痛,AI 有多懂?
上述兩個模型的實測,在判讀貓咪是否疼痛時,都有超過 72% 的準確率,算是相當不錯的成果。不過,在完全替代人工判讀之前,可能還要擴建訓練辨識系統的資料庫。因為當初請來的照片模特兒,是 29 隻準備接受卵巢子宮切除術的短毛母貓,年紀約幾個月到一歲多。拿牠們術前、術後,以及使用止痛劑前後的照片來訓練 AI ,雖然是個不錯的點子,但無法代表多元的貓咪社群。[6] 將來的實驗,若能涵蓋其他性別、年齡和品種,相信貓咪們會覺得更加窩心。
備註
FLACC 量表: FLACC 是臉(face)、腿(legs)、活動(activity)、哭(cry)與 安撫(consolability)的縮寫。每個項目依觀察到的狀態,給 0 到 2 分,總分最高 10 分。[2]
參考資料
- 瓊瑤經典台詞》小時候看超感動,長大看卻啼笑皆非的 7 大經典場景(風傳媒,2020)
- Pain assessment and measurement (The Royal Children’s Hospital Melbourne, 2019)
- Evangelista MC, Watanabe R, Leung VSY, et al. (2019) ‘Facial expressions of pain in cats: the development and validation of a Feline Grimace Scale’. Scientific Reports, 9, 19128.
- Me-owch — could resting cat face tell us about kitty’s pain? (CBC, 2020)
- Feline Grimace Scale – Practice your pain assessment skills using the FGS! (Université de Montréal, 2019)
- Feighelstein M, Shimshoni I, Finka LR, et al. (2022) ‘Automated recognition of pain in cats’. Scientific Reports, 12: 9575.
- 2021 iThome 鐵人賽-DAY21 資料正規化與資料增強(Data Normalization & Data Augmentation)(IT邦幫忙,2021)
- 2019 iT 邦幫忙鐵人賽-06. 深度學習的架構分析:多層感知器(IT邦幫忙,2019)
- 神經網路(IBM,2020)
- 何謂遷移學習?(NVIDIA,2019)