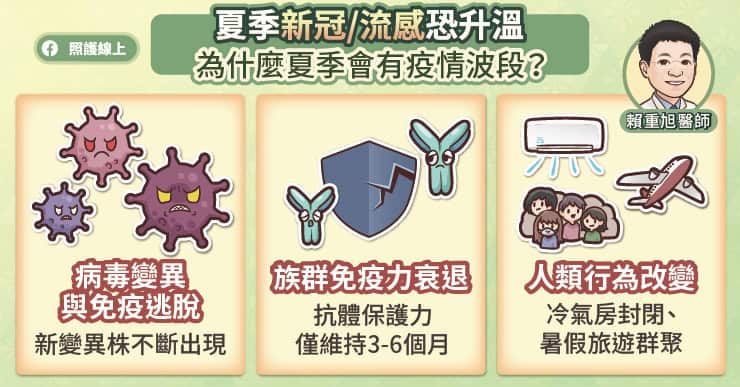
事後回顧,仍然未知起源的 COVID-19(武漢肺炎、新冠肺炎)應該是在 2019 年某個時候適應人類宿主,獲得人傳人的能力;2020 年 1 月在武漢傳開以後出國深造,2 月時在歐洲衍生出傳播力增強的 D614G 品系。
而一年後的 2021 年初,似乎又有傳染力更強的新型號病毒,在英國、南非、巴西三個地方獨立興起。[1, 2, 3]
傳染力更強的病毒,在英國誕生,愈演愈烈
三處值得注意的新款病毒中,英國款首先被觀察到,有大量新聞報導,至今知名度最高。它有多個名號,常稱作 B.1.1.7(也叫 VUI 202012/01)。之所以受到注意,是由於它的突變特別多。4, 5
導致武漢肺炎的病原體——SARS二世冠狀病毒(SARS-CoV-2),過去一年觀察下來,平均一個月大約累積 2 個突變;但是和近親相比,英國誕生的新品系卻配備高達 17 處突變,8 個位於 S 蛋白質(spike protein)上頭,另外也喪失 ORF8 基因,ORF1ab 基因上還有 3 個胺基酸缺失。
英國在 2020 年 9 月 20 日首度發現 B.1.1.7 以後,它的存在感持續上升。這款新病毒的性質仍需研究,不過初步幾點間接證據,支持它的傳染力確實有所提升。
- 第一,感染者人數短期內迅速增加,占總感染比例也明顯上升。[6, 7]
- 第二,感染者再傳染給下一位的比例,新型號病毒為 15%,其餘品系是 10%。
- 第三,新型號病毒的感染者,上呼吸道的病毒量比較高(由 Ct 值判斷)。[8]
- 第四,傳播到丹麥、美國以後,存在感增加的幅度和英國類似。[9]
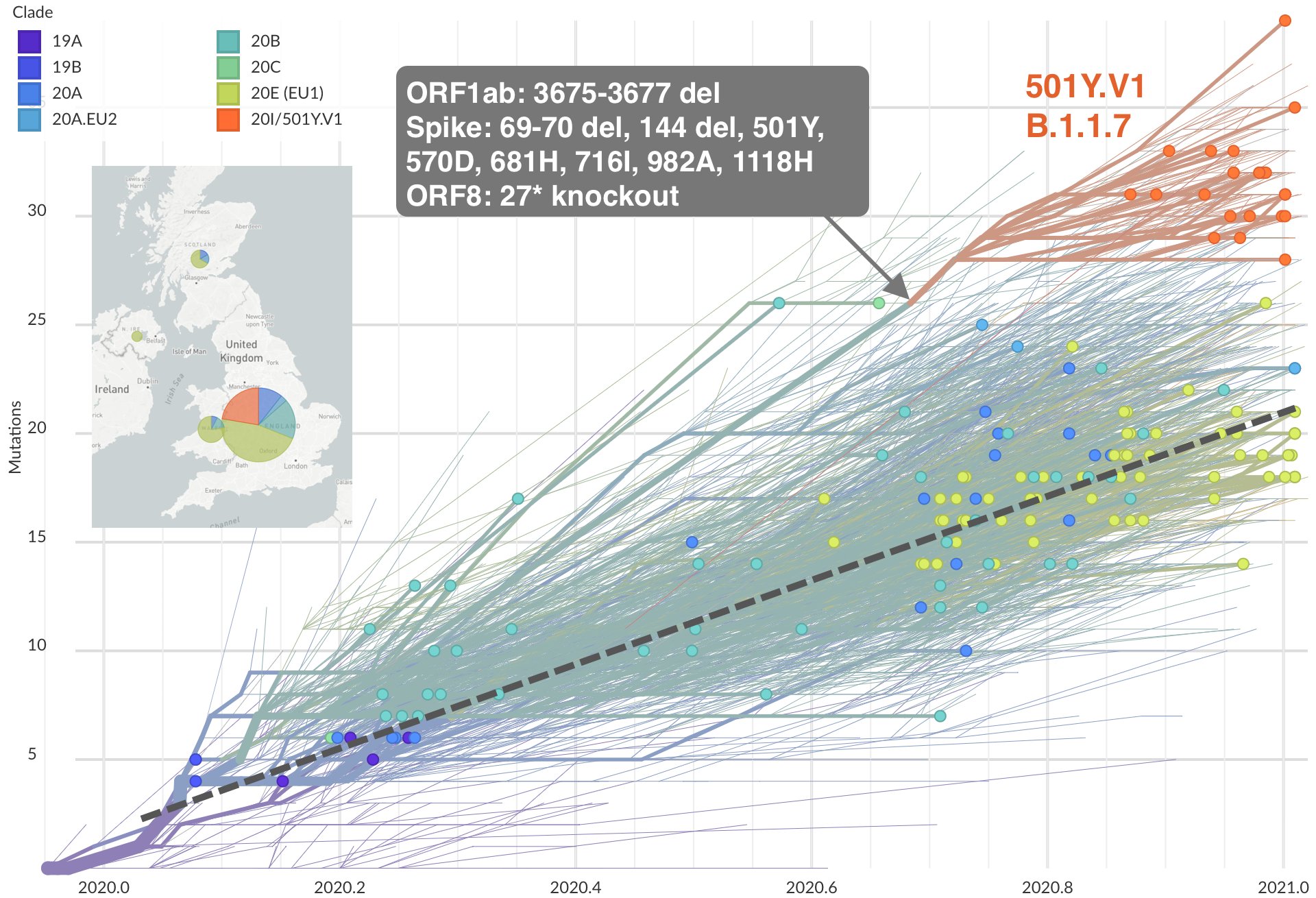
所幸英國的新型號病毒,在傳染力增加之外,殺傷力暫時沒見到改變。
去年初誕生,S蛋白質上的 D614G 突變,令傳染力上升,但是沒有提升殺傷力。D614G 成為隨後疫情的主要基礎,如今 B.1.1.7 等型號皆由此而來。看來突變強化傳染力的同時,殺傷力似乎更傾向維持現狀。
有專家憂心,新型號病毒的傳染力上升,是否對未成年人影響更大,讓小孩容易更得疫?這方面仍在調查,初步看來,不同年齡的增加幅度沒有明顯差異,暫時不用緊張。[10]
- 延伸閱讀:學校似乎不易成為武漢肺炎的溫床
南非、巴西,也和英國一樣
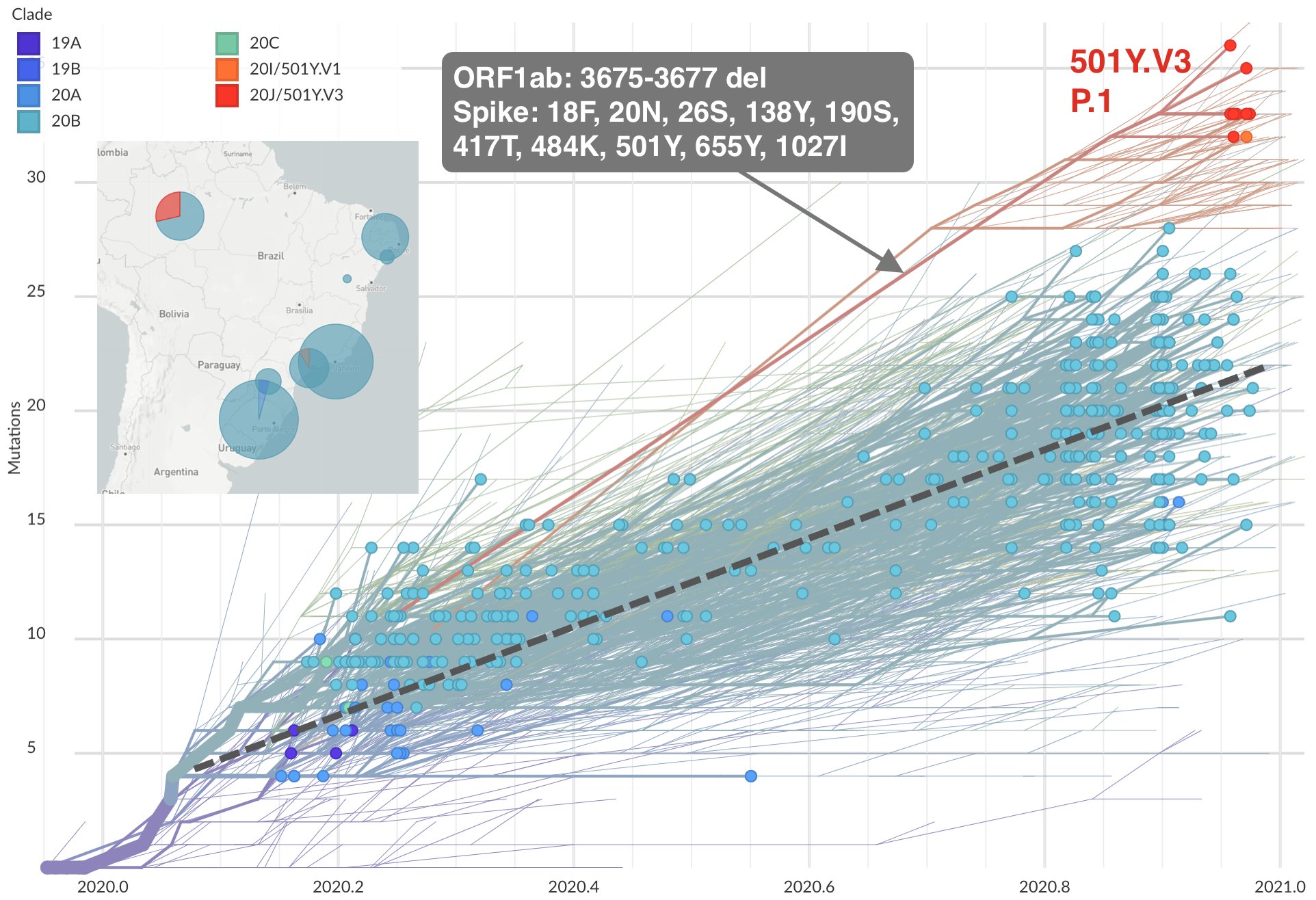
英國之外,南非、巴西也陸續出現特徵類似的新款病毒,在三地的存在感皆明顯上升。由演化關係看來,三地的新品系是獨立誕生,它們和英國的 B.1.1.7 一樣配備許多新突變,而且多數位於基因組上類似的位置。例如三者的 S 蛋白質上,都有 E484K、N501Y 兩個突變。
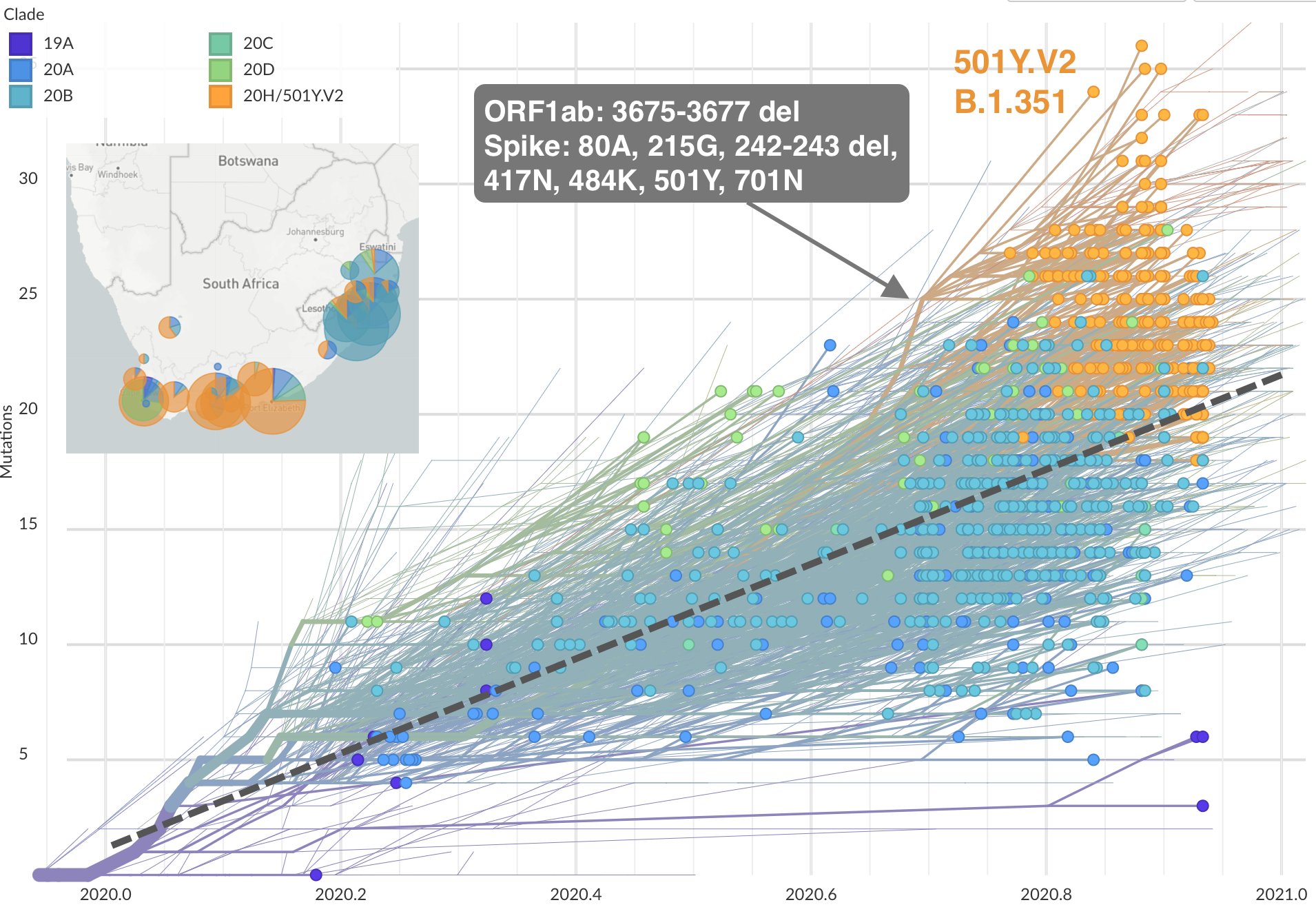
南非誕生的新品系名喚 B.1.351(也叫 501Y.V2),S蛋白質上有 7 個突變,ORF1ab 也有 3 個胺基酸缺失。[11]
巴西的新品系名喚 P.1(衍生自 B.1.1.28),在亞馬遜地區,疫情可謂全世界最嚴重的城市瑪瑙斯蔓延;它的 S蛋白質上有 10 個突變,ORF1ab 還有 3 個胺基酸缺失。[12]
值得重視的問題是,眾多突變是否會影響疫苗作用?初步看來某些突變,或許會減弱抗體的效果,不過在現實世界中未必會造成明顯的影響。要掌握狀況,仍需更全面的研究。[13]
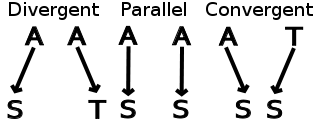
三處獨立發展的病毒,各自出現類似的遺傳變異,而且似乎在傳播上都有優勢,看來不是巧合。情況或許是「趨同演化(convergent evolution)」,也就是不同遺傳支系的病毒,面臨類似環境時,產生不同突變,卻有類似效果。
不過這邊看來,不同支系間至少部分突變是一樣的。若是如此,定義上應該是「平行演化(parallel evolution)」,亦即不同遺傳支系的病毒,在一樣的遺傳背景下各自突變,卻產生相同的新變異,又在環境中產生類似的效果。
話說回來,演化的詳細過程不容易釐清,知道概念比較重要。不要太計較的話,以趨同演化描述,不能說有錯。
強化病毒來自倒楣的「總加速師」?
突變數目和同類相比特別多的新品系們,是怎麼形成的?這種事的真相大概永遠都無法得知。有些專家猜測,是在免疫力衰弱的慢性病患體內醞釀出來的。[14]
有些罹患嚴重慢性病的患者,免疫力虛弱,體內妖魔鬼怪橫行,各方入侵者競爭激烈,也與免疫系統衝突不斷。SARS 二世冠狀病毒入侵這樣的宿主以後,將面臨很大的壓力;由於刺激多,病毒複製時犯錯,也就是發生突變的機率會增加。
倘若能從如此險惡的環境生存下來,就有機會發展成某方面更強大的新型病毒,這是個「總加速師」的概念。配備許多新突變的病毒離開總加速師,再感染普通人之後,如果能彰顯傳染力的優勢,將更容易傳播,在同類中脫穎而出。
上述推測缺乏明確的證據,不過頗有道理,不管你信不信,反正我先信了。然而,為什麼類似的突變組合包,會在英國、南非、巴西出現,而不是其他地方呢?是其他地方尚未出現,或是有別的原因?

規模愈大,適者脫穎而出的機率愈高
想像一下,一支比較強的球隊,若要展現出符合水準的優秀戰績,和弱隊的比賽場次,是少或多場更有可能?答案是場次多。因為場次愈少,愈容易受到運氣影響;隨著場次增加,運氣的相對影響力下降,更有機會反映出應得的戰績。
病毒的傳染也是如此。感染的人數和比賽場次一樣,感染規模愈小,運氣的影響愈大,傳播能力比較強的病毒,未必能發揮優勢,可能受到運氣不好拖累。假如感染的規模變大,天擇更容易發揮作用,讓佔有優勢的品系增加存在感。
英國、南非、巴西三地的共同點是,疫情幾個月來都非常嚴重,感染人數非常非常多。此一狀況下,除了更容易讓久病的總加速師感染外,如果有傳染力相對優勢的品系出現,比起疫情規模小的地方,脫穎而出的機率將會更高。
三地都觀察到類似結果,表示這套變異組合在當今世道下,很可能確實有傳播優勢。其他地方沒有見到,也許是還在等待倒楣的總加速師,尚未演化出來;或是曾經出現過,但是運氣不好已經消失,沒有廣傳到被發現的規模。
最後還是要提醒讀者們,疫情快速發展之下,能確定的事不多,推論成分很大。
總之,這場瘟疫似乎正在進入下一階段:總加速師的時代。如今智人開始大量使用疫苗對抗,世界各地卻也面臨傳染力更強的對手興起。這場戰爭仍然十分激烈。
延伸閱讀
- 族群大、傳播強、致死少、很難好,讓武漢肺炎威脅超越流感
- 在世界各地都取得優勢,不只是運氣好?——冠狀病毒的D614G突變(上)
- 結構強化的病毒,傳染力更強——冠狀病毒的D614G突變(下)
- 新加坡和台灣都見識過,WARS殺傷力減弱的∆382突變?
- 傳染像流感,殺傷似SARS:肆虐上下呼吸道的冠狀病毒
- COVID-19篩檢:陽性、陰性,還有CT值高低
- 感染的人多了,自然就會有群體免疫嗎?
- 比維京人更古老的北歐天花,也許不如後來致命?傳染病的演化史
- 三地的狡兔如何各自在與病毒的戰爭中活下來?抵抗力的平行演化
- 從海洋移民到淡水的魚類,製造DHA的基因多更多!
參考資料
- Trevor Bedford 推特,2020 年 12 月 30 日
- Trevor Bedford 推特,2021 年 1 月 15 日
- New coronavirus variants could cause more reinfections, require updated vaccines
- UK reports new variant, termed VUI 202012/01(VUI 202012/01 就是 B.1.1.7)
- Preliminary genomic characterisation of an emergent SARS-CoV-2 lineage in the UK defined by a novel set of spike mutations
- Estimated transmissibility and severity of novel SARS-CoV-2 Variant of Concern 202012/01 in England
- Transmission of SARS-CoV-2 Lineage B.1.1.7 in England: Insights from linking epidemiological and genetic data
- S-variant SARS-CoV-2 is associated with significantly higher viral loads in samples tested by ThermoFisher TaqPath RT-QPCR
- Trevor Bedford 推特,2021 年 1 月 19 日
- What new COVID variants mean for schools is not yet clear
- Emergence and rapid spread of a new severe acute respiratory syndrome-related coronavirus 2 (SARS-CoV-2) lineage with multiple spike mutations in South Africa
- Genomic characterisation of an emergent SARS-CoV-2 lineage in Manaus: preliminary findings
- Fast-spreading COVID variant can elude immune responses
- U.K. variant puts spotlight on immunocompromised patients’ role in the COVID-19 pandemic
本文亦刊載於作者部落格《盲眼的尼安德塔石匠》暨其 facebook 同名專頁