

- 文/Ryan Tang
出生香港的80後,在東京大學成為核子物理博士。現在於日本理化學研究所工作。 經常要向親朋好友解釋核子物理不是關於核電廠而煩惱。
y編按:你聽過「動物溝通師」嗎?他們也被稱為「傳心師」,可以透過照片等遠距離的方式跟在地球各處的動物溝通,有些溝通師會解釋其原理與物質不滅、腦電波隔空傳送、甚或是量子力學等等有關。但他們真的能傳心嗎?
香港《有線電視》的節目《新聞刺針》做了一個「動物傳心」的測試,他們用了一隻假的塑膠龜的照片說是記者走失的烏龜「布歐」,並詢問五位溝通師們布歐為何會「離家出走」。溝通師們的答案五花八門,有的說牠是一隻有理想有抱負想去大自然的龜龜,有的說牠一直躲在黑暗和潮濕的地方。
當然知道布歐是塑膠龜之後溝通師們各有不同的反應有的溝通師說他是和其他隻同名的烏龜有連結),先不論有沒有可能利用「量子糾纏」來「傳心」,先讓我們用機率來看這件事情有沒有可能呢?

之前有《新聞刺針》用塑膠龜測試「動物傳心」的真偽,發現 5 位動物溝通師都未能「感知」布歐是隻塑膠烏龜,《新聞刺針》便因此以「動物傳心為假」作結。但動物溝通師仍聲稱這是基於量子力學,由於量子力學是不能作出確定性(deterministic)的預測,只能給出機率;那麼,我猜「溝通師能傳心」也應該是由機率決定吧!
所以 5 次測試都未能給出正確答案就否定動物傳心,以統計的角度好像太武斷。在此不論膠龜有沒有思想,也不探究傳心和量子力學的關係,純粹由統計角度看問題。

箱子裡的球球是什麼顏色?先驗機率與條件機率

假設有一個箱,箱子裏有很多球。抽一次得到了紅球,就可以說箱子裏所有的球都是紅球嗎?顯然是不可以的。再抽五次,得五個紅球,那麼可以說箱子裏全都是紅球嗎?假如箱子有五個紅球跟五個非紅球,也有機會連續抽到五個紅球啊。如果抽了 100 次,每一次都是紅球,感覺紅球應該佔很大比例,也就是說其機率很高。在這些例子中,如何用數學理解這個「直覺」呢?
一般學校教的機率,是假定事件的先驗機率(prior probability),然後去計相關的機率。例如,已知箱子裏有 5 個紅球,5 個綠球,求抽到 2 個紅球跟 3 個綠球的機率。又例如假定雨天的機率是 30%,求未來 3 天會下雨的機率。但現實是先驗機率是很抽象的,所有機率都應該是實驗得來。想知道箱子有什麼球,就要把所有球檢查一次。想知錢幣是否公正,理論上我們要擲無限次,然後看看公和字出現的頻率是否相同,我們才能得出一個近似的先驗機率。
但現實上,我們只能擲的次數是有限的。而如果是說下雨的機率,難道天文台能把明天「重覆」幾次,然後得出先驗的下雨機率嗎?天文台可以模擬明天幾遍,而得出一個模擬機率,但這機率跟真實的「先驗」機率性質還是不同。所以先驗機率其實同假設沒兩樣。
基於先驗機率的不可知,數學家想出機率應該只能跟據手上的資訊來決定。當有新的資料,這個機率就會更新。情況就像,過去下雨的機率是 30%,當今天過去而沒有下雨,那麼明天下雨機率就會下降。 這個不斷更新的機率,比較容易定義,也容易操作,而且反映出觀察者對事件的「信心」。
那麼現在說明如何操作了。假設抽 n 次出 r 個紅球。跟據二項分佈(Binomial distribution),其機率是
P (n, r|x) = C rn xr (1-x)n-r
這裏用了條件機率(conditional probability),意即是如果抽紅球的機率是 x ,那麼抽 n 次出 r 個紅球的機率是這麼多。這個機率也可以想像成似然函數(Likelihood),即是如果抽 n 次出 r 個紅球,那麼「紅球的機率」是 x 的機會是多少。似然函數跟機率的關係是這樣
L (x|n, r) = P (n, r|x)
這時候根據 x 的不同會得出似然函數。下圖畫出一些例子。
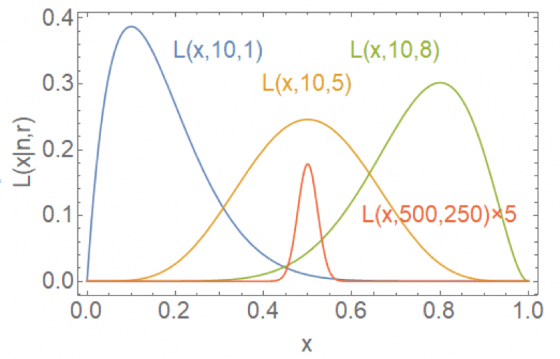
可見如果抽 10 次只有 1 個紅球(藍線),那麼似然函數會隨 x 而有所變化。而最似然函數最大時相應的機率是 0.1 ,即「紅球的機率」最有可能是 0.1。這結果完全是附合傳統的機率理論,抽 10 次只有 1 個紅球,那「紅球的機率」就是 0.1 啊!但是,我們看到藍線在 0.1 附近是有個寛度,而這寛度代表不確定性。如果抽 10 次有 5 個紅球(橙線),紅球的機率最有可能就是 0.5。 當抽 500 次有 250 次紅球(紅線),紅球的機率最可能也是 0.5。但是分布變窄了,也就是說 0.5 的「誤差」會隨著抽越多次而變得越小!
要注意,似然函數是觀察者因資訊而得出。似然函數最大值時相應的機率,跟先驗機率(或真正的機率)還可能有差別。例如就算真正的機率為 0.2,抽 10 次只有 1 個紅球的機率為 27 %,也是相當有可能的。所以在上圖中藍線在 x=0.2 那裏還有一定機率。但基於實驗結果最有可能的機率是 0.1。
5位動物溝通師都「槓龜」以後,動物溝通仍然不是夢?
好。那麼 5 位動物溝通師都沒有正確。那麼傳心最有可能的機率是 0;但不能因為這樣而完全否定傳心的可能。看看下圖當 n =5,r = 0 的情況。
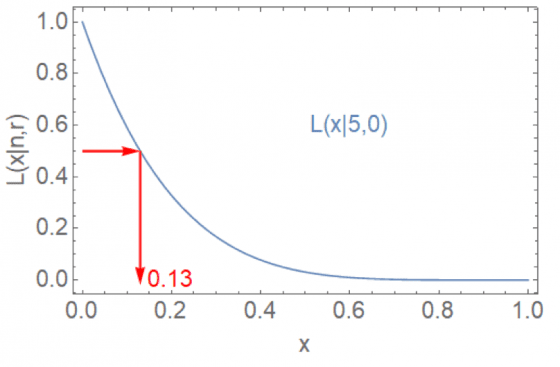
會發現在 x 不等於 0 的情況下其實還是有不少機率的:例如在x 等於 0.2,還有大約 30% 的機率,即「傳心有可能是20%的機率」還有0.3。
利用似然函數,我們不但得出跟一般機率理論一樣的結果(5次失敗,成功率是零),更可以得出誤差(雖成功率是零,但還有是13%誤差)。而誤差是多少,







































