


Q: 如果每個人真的只有獨一無二的靈魂伴侶,也就是這茫茫人海中,隨機出現的唯一有緣人,那會怎樣?──班傑明.斯塔芬(Benjamin Staffin)
A: 那會是多麼可怕的惡夢啊!

獨一無二的隨機靈魂伴侶-這個觀念本身就問題多多。正如提姆.明欽(Tim Minchin)在《如果我不曾擁有你》(If I Didn’t Have You)歌裡所寫的:
你的愛是百萬裡挑一;
用任何代價都買不到。
可是其他九十九萬九千九百九十九的愛情,
算起來,其中有些也會一樣的好。
可是,如果我們真的有一個命中注定、隨機分配的完美靈魂伴侶,而且我們跟其他任何人在一起都不會快樂,那怎麼辦?我們找得到彼此嗎?
假設你一出生,你的靈魂伴侶就選定了。你完全不知道那個人是誰,也不知道這個人在哪裡,可是當你們四目交接的那一剎那,馬上就會認出彼此。(老掉牙的浪漫愛情故事都是這麼演的。)
一堆問題馬上跟著來了。首先,你的靈魂伴侶還活著嗎?曾經活著的人有幾千億那麼多,而目前活著的人只有 70 億(也就是說,以人的死活狀況來看,死亡者的比率是 93 %)。如果我們都是隨機配成一對一對的,那我們的靈魂伴侶有 90 %的機率老早就死了。

聽起來怪可怕的!別急別急,還有更糟的:用膝蓋想也知道,我們不能只算那些已逝的人,必須把未來不知凡幾的人也算進去。想想看,如果你的靈魂伴侶是在遙遠的過去,那某人的靈魂伴侶一定也有可能是在遙遠的未來。畢竟,你的靈魂伴侶的靈魂伴侶,情況正是如此。
所以我們不妨假設:你的靈魂伴侶和你生活在同時代。再者,為了避免事情變得太「驚悚」,我們還得假設:你和靈魂伴侶的年齡相差沒幾歲。(這比標準的「年齡差距驚悚公式」〈註 1〉更加嚴格,如果假設一個三十歲的人和另一個四十歲的人可以成為靈魂伴侶,而他們早在十五年前就意外相遇,這樣便違反了驚悚規則。)有了年齡相仿的限制條件,我們大多數人的潛在「適配對象」,大約有 5 億人那麼多。
可是性別和性傾向怎麼辦?文化呢?語言呢 ? 我們可以繼續用人口統計資料,試著進一步縮小問題的範圍,可是這麼一來,我們就會與「隨機靈魂伴侶」的概念漸行漸遠。在我們的假設情境下,你完全不知道你的靈魂伴侶是誰,直到你們互相看對眼為止。每個人只有一個目標:對準自己的靈魂伴侶。
遇見靈魂伴侶的機率極為渺小。每天與我們眼神交會的陌生人,人數可能從近乎 0(離群索居或住在小鎮裡的人)到成千上萬(時代廣場的警察)不等,但我們不妨假設,你目光鎖定的陌生人,每天平均有幾十個。(我很宅,這估計值對我來說絕對是大手筆。)如果其中有 10 %跟你年齡相近,一輩子差不多就有 5 萬人。既然你的潛在靈魂伴侶有 5 億人,這就表示,你這輩子找到真愛的機率只有萬分之一。

隨著「孤老而終」的隱憂愈來愈明顯,社會可能會重新建構,盡量製造更多眼神交流的機會。我們可以安排大規模的輸送帶,讓整排整排的人從彼此的眼前經過……
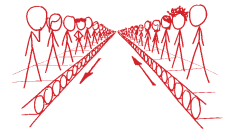
……不過,如果「眼神交會效應」透過網路攝影機也行得通,那倒不如採用改良版的聊天輪盤(ChatRoulette)。

如果每人每天使用這個系統 8 小時,每星期 7 天,而且要花幾秒鐘才能決定某人是不是你的靈魂伴侶,那這個系統在幾十年內,應該可以讓所有人跟自己的靈魂伴侶配對成功。(理論上是這樣啦。我設計了幾個簡單的模式,估算人們要多久才能配對成雙、退出單身一族。如果你想嘗試利用數學來計算某種特殊設定,或許可以先從錯位排列問題著手。)
在現實世界裡,很多人根本找不出時間來談情說愛―幾乎沒有人能投入二十年的時間來做這種事。所以呢,大概只有「富二代」才能閒閒沒事坐在那裡玩「靈魂伴侶輪盤」。不幸的是,對於眾所周知的那 1 %來說,他們的靈魂伴侶多半會出現在另外的 99 %裡頭。如果只有 1 %的「富二代」使用這個系統,此 1 %當中會有 1 %透過這個系統配對成功,因此整體成功機率是萬分之一。
而那 1 %當中其餘的 99 % 〈註 2〉,會想盡辦法讓更多人進來這個系統。他們可能會去贊助慈善計畫,把電腦送到世界上的其他地方―有點像是慈善活動「每童一機」與美國最大約會網站「OKCupid」的混合體。「收銀員」和「時代廣場警察」這類職業會變得非常搶手,因為他們有很多眼神交流的機會。大家會一窩蜂擁向城市及公眾聚集場所去找尋愛情,就像現在這樣。
可是,儘管一堆人在「靈魂伴侶輪盤」上度過幾年光陰,另一堆人努力保住「能與陌生人頻頻眼神交流」的飯碗,剩下的人但求好運上門,卻依然只有極少數的人能夠找到真愛。
既然這麼麻煩,壓力又這麼大,有些人乾脆作假。他們會去參加俱樂部,這樣就能和另一個孤單的人在一起,合演一齣「靈魂伴侶相遇」的假戲。他們會結婚,他們會隱瞞婚姻問題,他們會在朋友及家人面前強顏歡笑。
「隨機靈魂伴侶」的世界,會是個很孤單的世界。但願那不是我們生活在其中的世界。
註解:
- 詳見 xkcd 網站「約會對象」篇。
- 「我們就是那剩餘的 0.99 %!」

本文摘自泛科學 2015 二月選書《如果這樣,會怎樣?》,天下文化出版社出版。








































{kind=link}