從號誌開始還路於民:增設行人專用時相真的能保護行人嗎?
「好不容易綠燈了,怎麼又有路人擋在斑馬線上?現在汽機車要停讓行人,不是只會讓路口更塞嗎?」
「怎麼一綠燈,腳才剛踏出去,就差點被撞到,台灣真的是行人地獄啊!」
話說道路設計的最高原則,就跟XX製藥一樣,是先研究不傷身體,再講求效果。包括行人、駕駛者等用路人的安全要確保,再來才是讓所有用路人都能在安全的條件下,快速地到達目的地。
那麼駕駛轉彎時須等候行人的規定,你怎麼看呢?身為行人的我覺得,這只是遲來的行人正義,本該如此啊!以前每次過馬路都要急急忙忙,還擔心被司機怒瞪,感覺真的很差。不過握上方向盤的我卻又覺得,哇靠,現在每次汽車轉彎遇到行人就要停下來,結果根本如入行車地獄,一整排車子在路上塞爆,綠燈都結束了,車子還卡在路中間!
與其讓每個人都陷入行人與駕駛的無間道,也許我們該思考的是最根本的燈號設計問題,調整號誌設置加上增設行人專用時相(Pedestrian Scramble),被認為是擺脫行人地獄惡名的關鍵一招,但這招真的有用嗎?該怎麼用才真的好棒棒呢?
紅綠燈秒數該如何設計?
最近交通改革的呼聲很高,820「還路於民大遊行」也即將登場。台灣交通雖然不會因為一次的遊行,在一夕之間改變,但能讓更多人在乎交通的癥結,願意理性討論,我認為都是很好的發展。
因為多起令人傷心的事故,「道路設計」如今備受重視,然而設計道路不是看心情或靠直覺,不論是車道寬度、人行道寬度或是標線位置,都是集合交通學、數學和心理學分析的綜合結果。其中,紅綠燈的設計相對來說比較簡單,因為那就是解數學題嘛。
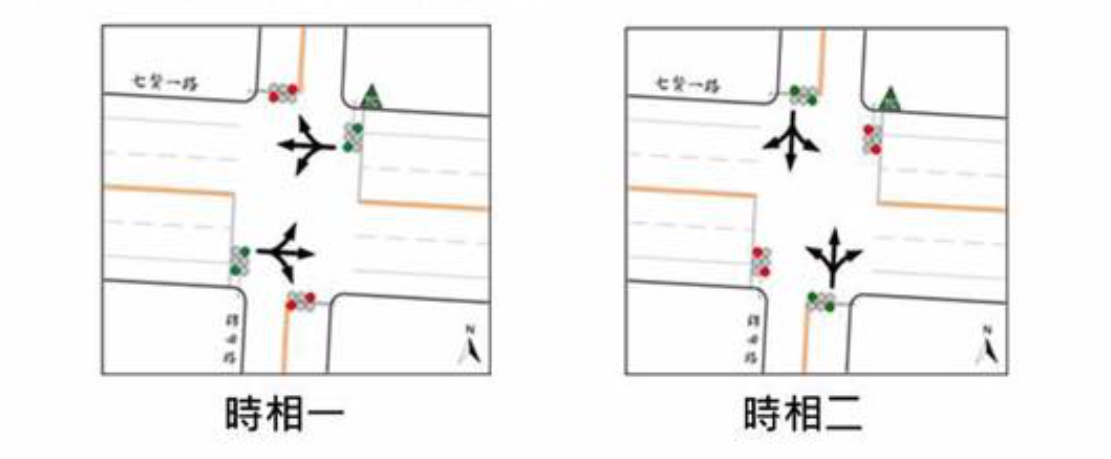
喔?這數學題該怎麼解呢?我們先以最簡單的雙時相號誌來舉例。這裡所謂的時相,就是指號誌的狀態。例如一個最一般的十字路口,會由一個南北向綠燈、東西向紅燈的時相,加東西向綠燈、南北向紅燈的另一個時相,組成雙時相系統。如果又加上禁止直行、僅允許轉彎的情況,那就是又多了一個時相。而由三個以上組成的系統,就是我們常聽到的「多時相交通號誌」。
現在我們眼前有一個雙時相號誌路口,我們的目標,是設計一個在固定時間內,能讓更多車通過,駕駛可以花更少時間抵達目的地的路口。唯一的條件,是它的紅燈與綠燈時間必須一樣長,那麼你會希望紅燈長一點還是短一點呢?蛤,短一點比較好?真的是這樣嗎?
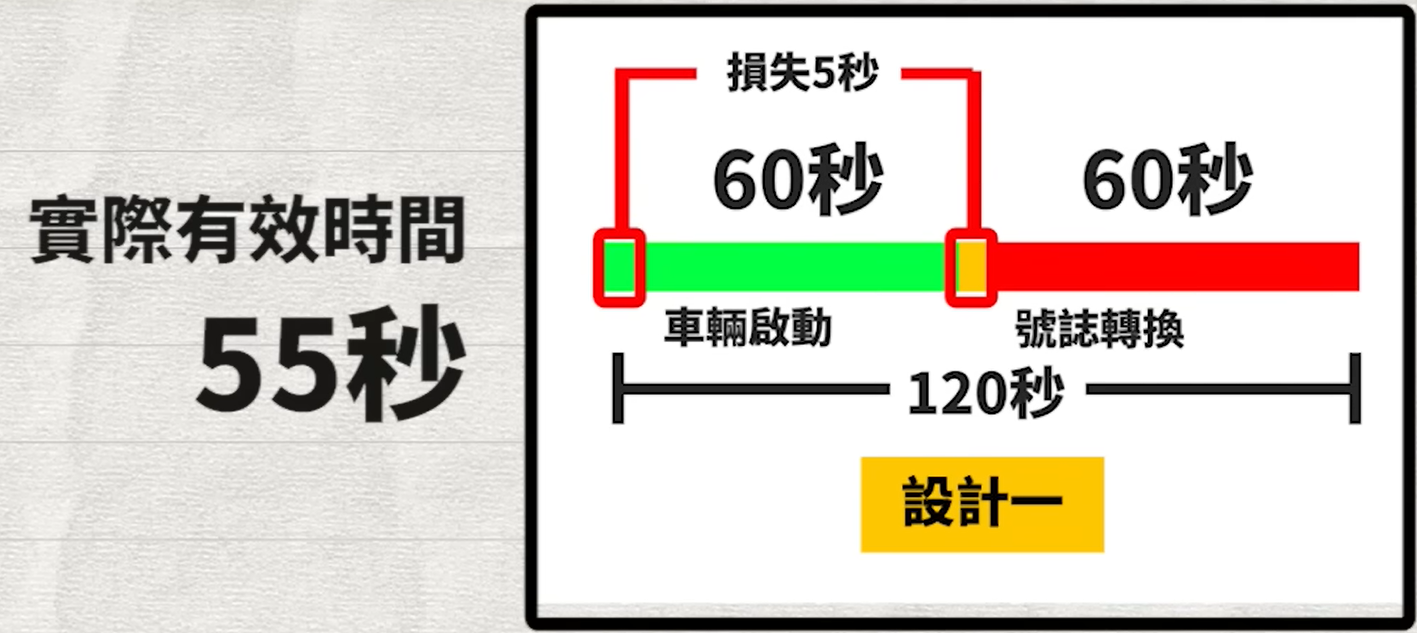
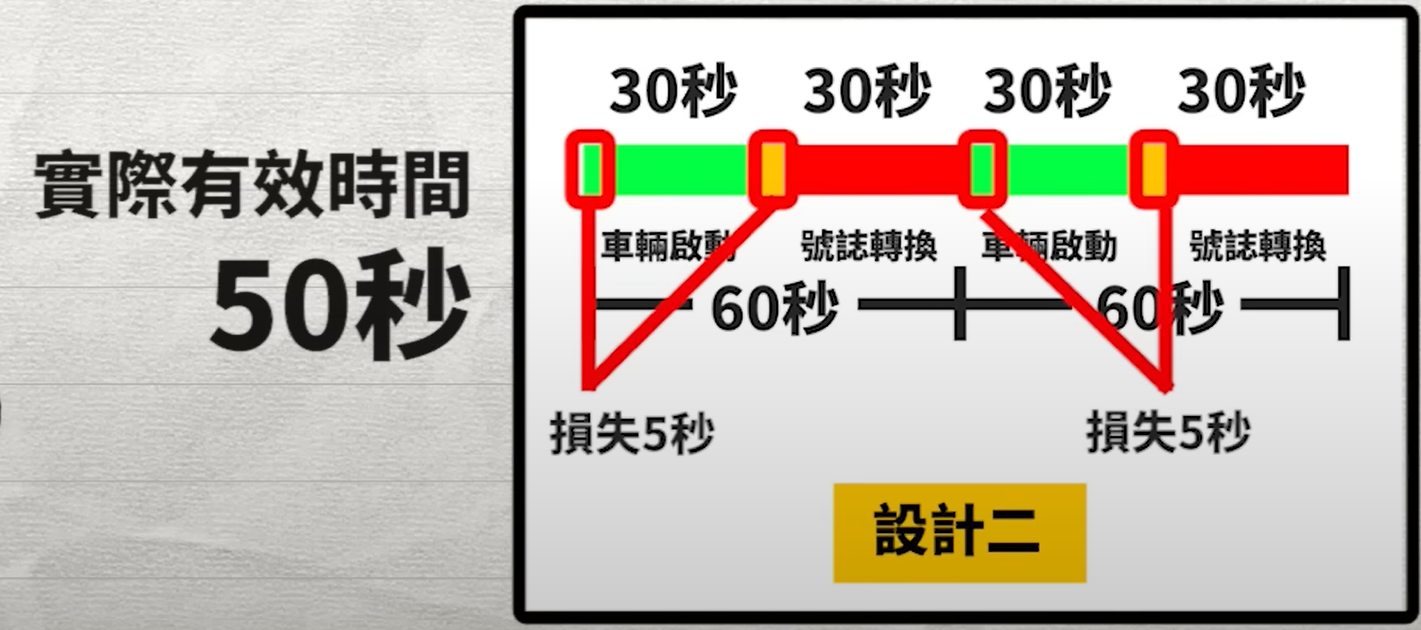
當我們在設計號誌週期 (signal timing) 時,通常會將號誌畫成類似於 PM 常用的甘特圖,更加一目了然。現在我們有第一種設計:紅燈、綠燈各一分鐘,一個號誌週期是兩分鐘。以及第二種設計:紅燈、綠燈各 30 秒,一個週期是一分鐘。實際畫成甘特圖,雖然一次的紅燈等待時間變短了。但長時間來看,你遇到綠燈跟等紅燈的時間,是一樣多的,也就是在相同時間內,前進的距離是一樣的。
當然啦,相信你也看出來了,現實情況不是這樣,就算是藤原豆腐店的送貨員,從零加速到一百,喔不對,一般道路速限是 50 公里。從零加速到 50,也是需要起步時間的,如果遇到紅燈也需要煞車時間。再加上黃燈的轉換時間,這些時間加起來會產生不少的時間損耗。如果遇到一次紅燈,就會損失 5 秒。那麼在週期為兩分鐘的道路上行駛兩分鐘,實際上的有效時間,只有 60-5 秒,也就是 55 秒的時間。在週期為一分鐘的路口呢?雖然行駛兩分鐘的綠燈時間總計也是一分鐘,卻因為會多遇到一次紅綠燈。所以有效時間會損失 2 次 5 秒,也就是有效時間只剩下 50 秒,比週期是兩分鐘的道路還少了五秒。
結論就是,雖然綠燈長一點,紅燈也需要等久一點,但比起不斷地走走停停,能將速度維持在速限的時間更久,就能節省更多時間。
號誌連鎖,幹道更順暢
當然,以上假設是紅燈與綠燈一樣長的情形,大部分的道路規劃都存在幹道、支道的區分。幹道是交通的命脈,也是車流量最大的地方,因此綠燈時間就會設計的比紅燈還要長,在號誌設計上也會有其他的考量。
例如,大家在路上看到一整排綠燈,一路大順暢,心情一定也十分舒暢,這被稱為號誌同步 (Signal Synchronization)。剛才討論的是單一紅綠燈的時間長短,現在我們同時考慮整條路上的紅綠燈,依照經驗也知道,沒有號誌同步的幹道,遇到的紅燈次數自然也會比較多,那麼因為頻繁減速、加速而出現的時間損失又多起來了。
但是,號誌同步真的是最優的作法嗎?其實不見得。當我們將號誌再次畫成圖,把號誌的時間和空間擺在一起,形成時空圖(Time-Space Diagram),並且加入行駛速限的考量。
我們會發現,放入合適的時差,能讓號誌如波浪般傳遞下去,每次你剛好到下一個路口,就會剛好遇到綠燈,達到真正的一路大順暢。這種安排方式被稱為號誌連鎖 (Signal Coordination)。而要讓雙向的道路都能受益於號誌連鎖的好處,就需要透過嚴密的車流量與數學計算。
在這些基礎之上,還需要加入時間、車流、轉彎道等資訊,才能做出最有效的號誌設計,實在不簡單。在這個基礎之上,若要解決行人屢屢遭遇事故的困境,該怎麼設計紅綠燈呢?
行人專用時相是什麼?
前陣子,關於駕駛轉彎時須等候行人的議題又再度浮上水面,有人提出既然每次汽車轉彎遇到行人就要停下來,不如增設「行人專用時相」(Pedestrian Scramble)來解決問題。在這個時相內,只有行人可以移動,反過來說,在汽車移動的時候,行人是不能移動的。
這有什麼好處呢?首先,因為行人穿越馬路時所有汽車都得靜止,因此行人可以穿越對角線,穿越馬路的次數從兩次變為一次。對於駕駛來說也有好處,因為駕駛行駛時已經沒有行人會穿越斑馬線,因此右轉車輛可以不受影響,降低等待時間。而最重要的是,行人移動時沒有任何交通工具正在移動,直接降低了車禍的風險。倫敦交通局在 2010 年的報告中,便說明行人專用時相可以降低 38% 的行人傷亡。
既然這麼立竿見影,那把所有路口都加設「行人專用時相」就解決問題了嗎?其實也不是。增加一個時相,就意味整個週期拉長了。因此不論是行人還是車輛,要等的紅燈時間也會拉長。在少部分城市,就觀察到駕駛更容易因為等得不耐煩而搶跑、闖紅燈,例如加拿大的多倫多,就因此在 2015 年取消了行人專用時相。
一般認為,適合設置行人專用時相的地方,僅在行人人流量高的路口,例如鬧區、車站前、幹道交叉口等等。在行人數量不多的路口,增加時相可能反而會使塞車問題更加嚴重。
還有什麼方法能讓行人更安全的過馬路?
事實上,台灣交通安全協會理事長陳宏益也表示,行人專用時相只是短期應急作法,更好的做法是搭配不同路口採用不同的措施。例如設置「行人早開時相」(Leading Pedestrian Interval),讓行人比車輛早 3~7 秒綠燈,增加行人被駕駛看到的機會、減少人車爭道。
或是呢,設置行人庇護島或將行穿線退縮,除了庇護島能多一分保障外,重要的是行穿線退縮能增加汽車的等候空間,並且因為車輛在轉入時已經轉直,比較不容易因為 A 柱死角而看不見行人。
這樣聽起來,只要根據每個路口車流、人流,調整燈號設計,台灣的「行人地獄」應該有解囉?你覺得呢?有可能改變嗎?
當然有解,那麼多國家都提出了交通零死亡願景,事在人為啊!
教育才是最佳解,從幼兒園開始重新學習行人路權觀念,保守估計下一代……大概就會成功了。
我不入地獄,誰入地獄,這個肉身臭皮囊,還是靠自己長眼顧好吧!
歡迎訂閱 Pansci Youtube 頻道 獲取更多深入淺出的科學知識!