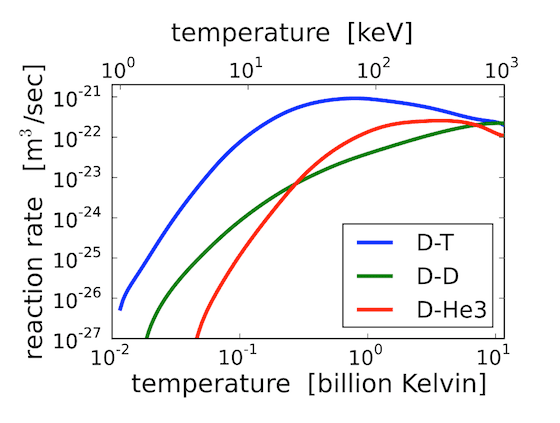
credit: CC by Dstrozzi@wiki , 加熱電漿的主要目的是增加反應速率,目前在TOKAMAK中採用 D 與 T 為燃料,而非氫的主要原因是氫在自然狀態下,核與核碰撞後發生核融合反應的機率為微乎其微。相較於現今任何一種發電方式,核融合一單位燃料產出的電量是非常可觀的,但是D 在地球上的存量也是有限的。若不改善能源的需求,也許某天人類得上太空去採礦 。
References
D. R. Williams. Sun fact sheet. NASA., 2013.
E. Bohm-Vitense and E. Bohm-Vitense. Introduction to Stellar Astrophysics:. Introduction to Stellar Astrophysics. Cambridge University Press,1989.
Kenro Miyamoto. Fundamentals of Plasma Physics and Controlled Fusion. NIFS PROC: Kakuyugo-Kagaku-Kenkyusho. National Institute for Fusion Science, 2011.
J. Wesson. Tokamaks. International Series of Monographs on Physics. Oxford, 2011
近年來因為人工智慧、大數據、區塊鏈等應用科技快速發展,以及 Google 等科技公司大舉來到臺灣進駐並招聘大量軟體工程師,臺灣頂大的資工科系成為超熱門志願。不過大家對資工系的印象就是要學寫程式,也就是俗稱的 coding,但 coding 在解決什麼問題?今天我們訪問了臺大資工系的陳縕儂副教授,從老師的專業「自然語言處理」(Natural Language Processing,縮寫 NLP)做切入,來帶大家了解資工系究竟在解決什麼問題。
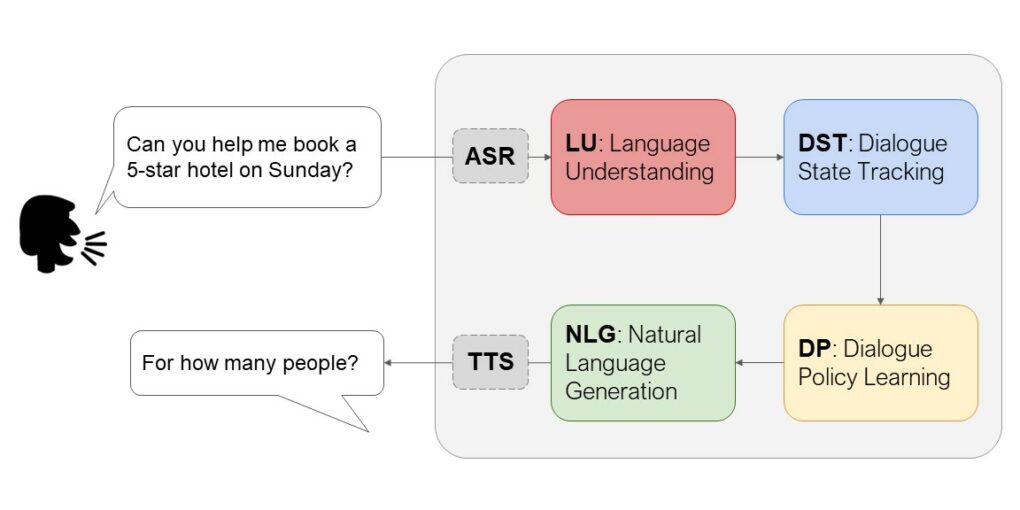
大家可以想像一下,今天要跟一個 AI 互動,通常是透過語音或者文字來下達指令,接著 AI 就會協助我們完成特定的任務,並解決特定的問題。
在這個過程中,有四個主要的環節必須克服,分別是語音辨識 (Automatic Speech Recognition; ASR)、語意理解 (Natural Language Understanding; NLU)、對話決策 (Dialogue Management)、以及語言生成 (Natural Language Generation; NLG),說的白話一點,就是接收你講的話、翻譯成 AI 能理解的指令、要如何處理指令,以及怎麼把回應翻譯成人類能聽懂的聲音或文字。
在這四個環節裡都有相當複雜的問題需要去解決,譬如語音辨識,在技術上通常是將語音訊號直接轉換成文字,讓 AI 去理解,但在將音訊輸入的過程中,就必須要排除掉我們口語中會用的「嗯」、「啊」、「喔」等贅字或不自然的停頓,又或者是新創的流行語、方言、口音……等等的問題必須先解決,才能讓 AI 真的能聽懂人類的自然語言。
在「語意理解」上,要讓 AI 去分析語言或文字的脈絡、理解關鍵字,再找出對應的資料(搜尋資料庫);而「對話決策」更是困難,前面理解了人類的語言或文字表意後,AI 應該要如何回應?可能使用者給的資訊不完整,AI 要追問使用者以釐清問題?又或者在語意理解上有聽不懂的字,得要再次詢問並確認?
-----廣告,請繼續往下閱讀-----
這還只是 AI 面對人類自然語言時,其中幾個回應的選項,真實的對話情境可能更加複雜,而且整個對話過程只要有一個環節正確度不夠高,那 AI 後續也很難準確的回應,只要有一步錯了,就會對後續對話體驗造成負面影響。
不過好消息是,現在的深度學習技術已經相當成熟,只要餵資料給電腦時,告訴他怎麼樣是對、怎麼樣是錯,基本上電腦都可以不斷修正(餵的資料也要夠多),再加上現行語言代表模型的優化,智慧 AI 在特定領域的應用上都有蠻不錯的成果。
AI 處理語音指令的過程。圖/陳縕儂提供
Jarvis 仍遙遠,AI 的新突破是精準翻譯
聊到這幾年 AI 的重要突破,老師提到三年前 Google 所開發的語言代表模型 BERT(Bidirectional Encoder Representations from Transformers),當時 BERT 一出現市面上所有自然語言處理的模型都改採用了它的運作邏輯。相較於過去的語言模型,通常都是餵指定任務的文字來訓練電腦,BERT 是在給電腦任務前,先餵它吃很多的文章或書,接著再提供任務給它。
而 BERT 的技術確實也得到相當好的成效,所以擊敗了當時許多正在開發的語言模型,成為了當前語言模型的基礎。有趣的是,BERT 的前身是一個名為 ELMo(Embeddings from Language Models,與芝麻街角色名字相同)的語言模型,所以 BERT 的開發者們就用芝麻街的角色,來為他們開發出來的語言模型命名。
雖然說 NLP 領域在商業與學術上都有相當大的發展空間,但陳老師認為,目前要達到人的「common sense(常識)」對 AI 來說還是非常困難,舉例來說,今天我們跟智慧助理說我今天要跟某某人吃晚餐,這個時候如果是人類的助理,我們可能會聯想到「吃什麼」、「要不要聯絡某某人」、「交通方式是?」……等等與飯局相關的問題,但 AI 目前並沒有辦法執行這麼複雜的互動,還得必須跟 AI 說「幫我訂位」、「幫我叫車」,仍在一個指令一個動作的狀態,這種 AI「common sense」的建立,可說是目前非常有挑戰性的項目。
身為 AI 的設計者,陳縕儂老師認為 AI 會成為輔助人類的一部分,雖然說現階段許多人對於 AI 可以執行我們的工作感到彆扭,但實際上 AI 正在減輕我們的工作量,舉例來說,像是目前醫院已經有在使用協助診斷的 AI,但這樣的 AI 並不會取代醫生的工作,因為 AI 只是提供醫生診斷的相關依據,實務上對於病患的判斷最終還是得由醫生來做。
雖然 AI 已在產業中被廣泛利用,但基本上仍以「人機協作」為大宗,雖然能取代部分人力,但像是創造類型的工作 AI 就幾乎無法獨自完成。至於大家想像中,AI 恐對人類造成威脅的情節,基本上不會發生,因為 AI 是不會憑空出現意識的,AI 威脅人類的可能,比較會是人類不當利用造成的風險,所以在未來 AI 的開發上,基本上會往輔助人類的方向去做應用。