打開搜尋引擎,不知道要輸入什麼用詞才能找到需要的資訊?例如,明明心中的疑問是「今天會下雨嗎?」,但打開Google搜尋,輸入的關鍵字卻是「本日 降雨機率」。
為了要讓搜尋引擎理解問題,大多數的人在使用 Google 搜尋時往往會捨棄口語用詞,改為輸入幾個簡單的關鍵字,久而久之已變成一種慣用的搜尋習慣。好像不那麼做,Google 會看不懂關鍵字,也就無法順利搜尋到需要的資訊。
但看看「Google 助理向美髮沙龍預約剪髮」的實際對話影片,可以發現 Google 其實有能力理解口語對話,還能像人類一樣回覆流利答覆,而這樣的能力也能在 2019 年「BERT 自然語意演算法」推出後,使用 Google 搜尋查找資訊時獲得類似的經驗。
號稱能理解人類語言的 BERT 演算法
BERT 演算法有個繞口又深奧的全名:Bidirectional Encoder Representations from Transformers,翻成中文的字面意思還是很難理解。
但簡單來說,它能幫助電腦更理解人類的語言。若應用在搜尋引擎方面,它能夠仔細辨識搜尋字串的「每個字」,再根據前後字詞的關係(上下文)去讀懂整個搜尋字串要表達的意思,而且與以往只擇一比對前一或後一個字詞不同的是,BERT 演算法是將前、後字詞都納入判斷語意的參考,所以能更精確判斷使用者搜尋該字串的意圖/目的。
BERT 演算法剛推出時,在美國地區、使用英文搜尋時的搜尋結果,約有 10% 受到影響,也就是每 10 個搜尋之中,會有 1 個搜尋結果受到影響,因此被稱為是繼 2015 年、號稱影響 Google 排名第三大因素的 RankBrain 推出後,Google 演算法史上目前最大的變革。除了英文以外,後來也逐漸推及到其他搜尋語言。
BERT 演算法背後的原理
1. 讓電腦聽懂「人話」:自然語言處理
自然語言指的是「人類自然而然說出來的語言」,因為正常狀況下,人類在對話時有上下文可以參考,因此能互相理解彼此的語意(當然偶爾還是可能出現溝通障礙,)。但電腦卻很難理解自然語言。而自然語言處理 Natural Language Processing (NLP),就是用來幫助電腦理解人類自然語言的一種技術。
以中文為例,因為中文句子不像英文句子,會用空格隔開各個單字,很容易因為斷句方式不同,而有不同的語意,因此,中文的自然語言處理至少要做到兩件事,第一件是將句子「斷成詞,以理解個別詞義」、第二件是「分析語意」,包括文法和整個句子的語意解讀。
舉例來說,「他・有・繪畫・的・才能」和「放下・才・能・得到」這兩句話雖然都有「才能」,但兩個句子的斷句方式不同,「才能」在這兩句話的意思也不同。研究人員會將大量的類似句子做出這樣的斷句,讓電腦學習,往後當「才能」這個詞又出現時,電腦也能學會從上下文判斷,並做出適當的斷句。

2. 電腦「自學」的關鍵:詞向量
但詞彙那麼多,要如何讓電腦學習呢?最常見的方式是將詞彙轉換為「詞向量/詞嵌入」(Word Vector/ Word Embedding),簡單來說,就是以一連串數字代表詞彙,讓電腦更能理解詞彙之間的關係。每個詞彙都有一組數字,而這些數字是由比對大量前後文而統計出來的結果,可以用來比較詞彙間的關係遠近。
字義越相關,詞向量的距離越近,例如「蝴蝶」跟「飛」的向量距離比跟「爬」的向量距離還近。而且,隨著資料量越多,統計出來的數字也會隨之調整,詞彙間的關係因此能越來越精確。如此一來,電腦不需要語言學相關知識,也能透過蒐集大量資料和統計來自主學習,並且根據統計數據處理語言。
回到BERT來說,起初,研究人員研發出多個不一樣的語言理解處理模型,每個模型都有特定的功能,專職處理特定類型的語言理解,例如有的負責斷詞、有的負責分析語法、有的負責情感分析。就好像廚房中有各種不同的工具,水果刀用來切水果、開瓶器用來開紅酒,每個器具各司其職;而BERT就像是一把瑞士刀,一把在手就能滿足多種功能需求,BERT能處理大部分的自然語言處理問題,也就不再需要使用多種語言理解處理模型,這也是Google將BERT導入演算法應用的原因之一。
常見的自然語言處理有效運用案例有:客服常使用的聊天機器人、智慧型手機的詞彙建議等,能從幾個關鍵字判斷出完整句子,再從資料庫中找出適合的資料回應。
(補充:若想更深入了解BERT演算法原理,可參考Google官方釋出的Open Source說明。)
BERT 演算法的應用實例
Google 官方表示 BERT 將會擴大應用於多種語言的搜尋結果,但官方目前已釋出的舉例大多仍是以英文為主。
例如:使用者搜尋“2019 brazil traveler to usa need a visa”,是想知道「2019 年巴西旅客去美國旅遊是否需要簽證」,但在 BERT 演算法推出前,Google 忽略了使用者搜尋字串中的介係詞 “to”,因此將搜尋意圖錯誤理解為「美國旅客去巴西旅遊是否需要簽證」,提供的搜尋結果自然就會是針對美國人要去巴西旅遊的情境。
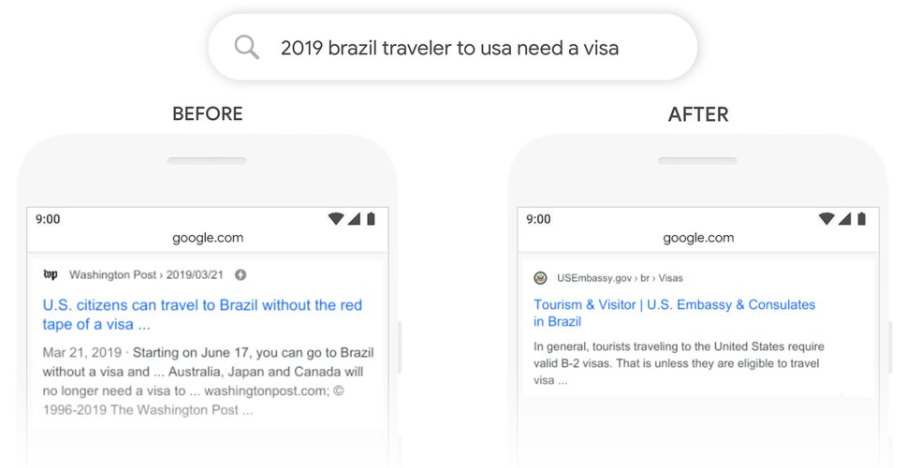
BERT 演算法強調搜尋引擎能辨識搜尋字串的「每個字」,再去理解整個搜尋字串要表達的語意,所以加入介係詞 “to” 去分析以後,就會得到完全不同、更準確的搜尋意圖,提供的搜尋結果自然更能符合使用者的需求。
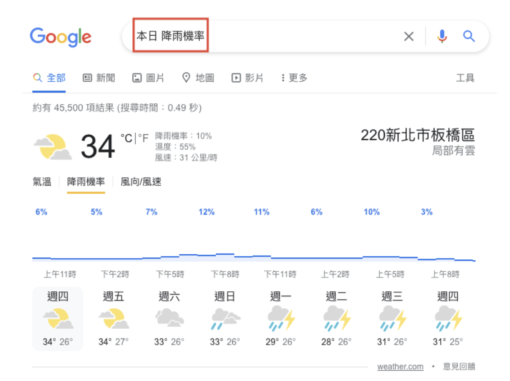
雖然沒有官方資料證實,BERT演算法對於繁體中文搜尋結果有何影響。但實際搜尋幾組繁體中文關鍵字,仍可發現有 BERT 的蹤影。例如搜尋口語化的句子「今天會下雨嗎」,和較為正式的關鍵字用法「本日 降雨機率」,Google 搜尋結果第一個列出的,都是使用者所在位置的降雨機率預報。
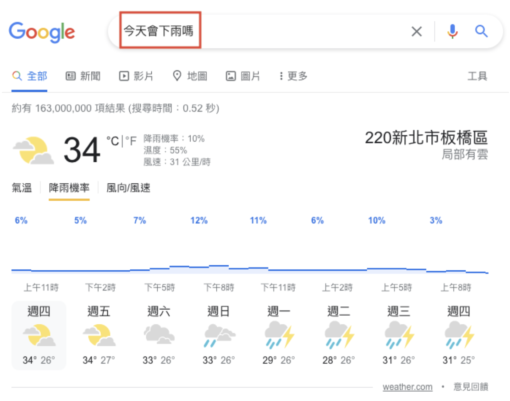
根據上述例子,可以推測出,即使「今天會下雨嗎」是相當口語化的自然語言搜尋用語,但Google仍然能夠理解,使用者輸入「今天會下雨嗎」和「本日 降雨機率」這兩組關鍵字,所要找的資料其實是一樣的。
BERT 演算法也有極限
先不論 BERT 演算法,是否能改善英文以外其他語言的搜尋結果,BERT 演算法本身也有以下一些限制:
1. 不擅長理解否定敘述
語言學家 Allyson Ettinger 在他的研究論文 “What BERT is not” 中提出了幾個要點說明 BERT 的限制,其中特別指出 BERT 很難理解否定詞對於上下文語意的影響。
2. 不擅長理解長篇文件
電腦要理解長篇文件的挑戰性更高,因為大部分長篇文件會再細分為章節、段落、句子,即便是人類在閱讀長篇文件時,可能都需要參考文件架構才能理解整篇文件的內容。因此電腦在理解長篇文件時應該將架構一起納入處理,但理解長篇文件的架構對 BERT 演算法而言並不容易。
總結
Google 官方承認,即便導入了 BERT 來提升自然語言處理的成效,要精準理解自然語言對於電腦而言仍是非常有挑戰性。不過,針對搜尋結果優先列出的「精選摘要」部分,Google 表示目前至少在韓語、印地語和葡萄牙語都已有重大改善。在未來,Google 預計將 BERT 學習英文理解的這套模式套用到更多不同語言上,期待未來所有使用者在執行搜尋時,都能以最輕鬆自然的方式輸入,而不需要刻意思考應該輸入什麼關鍵字,才能被 Google 搜尋引擎所理解。
資料來源
- Google Duplex: AI will call and book your appointments
- FAQ: All about the BERT algorithm in Google search – Search Engine Land
- Open Sourcing BERT – Google AI Blog
- 如何斷開中文峰峰相連的詞彙鎖鍊,讓電腦能讀懂字裡行間的語意? – 泛科學 PanSci
- Understanding searches better than ever before – Google
- What BERT is not – Allyson Ettinger
- Google’s SMITH Algorithm Outperforms BERT – Search Engine Journal






































