植物身上的脂質增加會讓它變胖嗎?不會!反而會促進開花?——專訪中研院植微所前研究員中村友輝
本文轉載自中央研究院「研之有物」,為「中研院廣告」
採訪撰文|歐宇甜
責任編輯|簡克志
美術設計|蔡宛潔
植物脂是什麼?它會怎麼影響植物?
如果提到植物脂質,一般人可能會想到果實或種子裡儲存的油脂,可以加工成大豆油、花生油、芝麻油等油品。不過,近年有越來越多證據顯示,脂質還會影響植物的生長和發育,例如開花的機制。中央研究院「研之有物」專訪過去院內唯一一位由發育生物學觀點研究植物脂質的學者,他是植物暨微生物學研究所的前研究員中村友輝,我們邀請他分享植物脂質研究與他的研究歷程。
中研院植微所的前研究員中村友輝。圖/研之有物
過去科學家對植物的脂質研究主要分兩個,一個是研究植物經光合作用轉化的脂質,這是植物可以拿來利用的養分;另一個是研究種子裡的脂質,例如透過品種改良或基因改造,提高種子的產油效率。中村友輝的團隊研究微觀的機制,他們探討脂質如何與其他訊號傳遞因子作用,協調植物的生長發育過程。
中村友輝是中研院植微所的前研究員,他深耕脂質研究已有 21 年,在中研院時期(2011~2022),他一手建立起脂質研究團隊,該團隊的重大研究成果之一就是:發現植物脂質跟調控開花有因果關係 。
中村友輝團隊發現植物脂質跟調控開花有因果關係,圖中植物為阿拉伯芥。圖/研之有物
要找出因果關係並不容易,研究團隊從植物脂質出發,先瞭解植物體內各種不同的脂質,再進一步探索脂質在植物體內如何製造與代謝。製造過程中,不同的酵素與步驟都會影響脂質的含量與結構,甚至同一種脂質,也都可能產生不同結構。
在瞭解脂質如何製造與代謝之後,接下來就是深入脂質的實際功能。「脂質如何影響植物?」要回答這個問題,必須人為控制脂質的代謝,確認變因。
中村友輝團隊開發出「代謝切換系統」,這套系統可以短暫改變脂質的代謝速率或途徑,讓研究人員改變特定位置的脂質含量和種類,觀察不同脂質對植物的影響。
從人體機制找到調控植物開花的秘密
一般開花植物會根據季節變化、日照長短決定開花時機,而科學家發現植物裡有一種 FT 蛋白質(Flowering Locus T),能誘導植物開花,是一種開花素(Florigen)。
長日照植物在足夠的日照長度下,葉子裡的 FT 基因轉錄會活化並合成 FT 蛋白質,再運輸到頂芽,使葉芽轉變成花芽並開花,不過許多調控機制方面的細節仍然是謎。
中村友輝團隊發現,植物裡有一種磷脂質(磷脂醯膽鹼,Phosphatidylcholine,簡稱 PC),會隨日照變化改變,並與開花素產生交互作用、促進開花。脂質角色的加入,是當時其他學者尚未關注到的領域。
為什麼團隊會把 FT 蛋白質跟植物脂質連結起來呢?
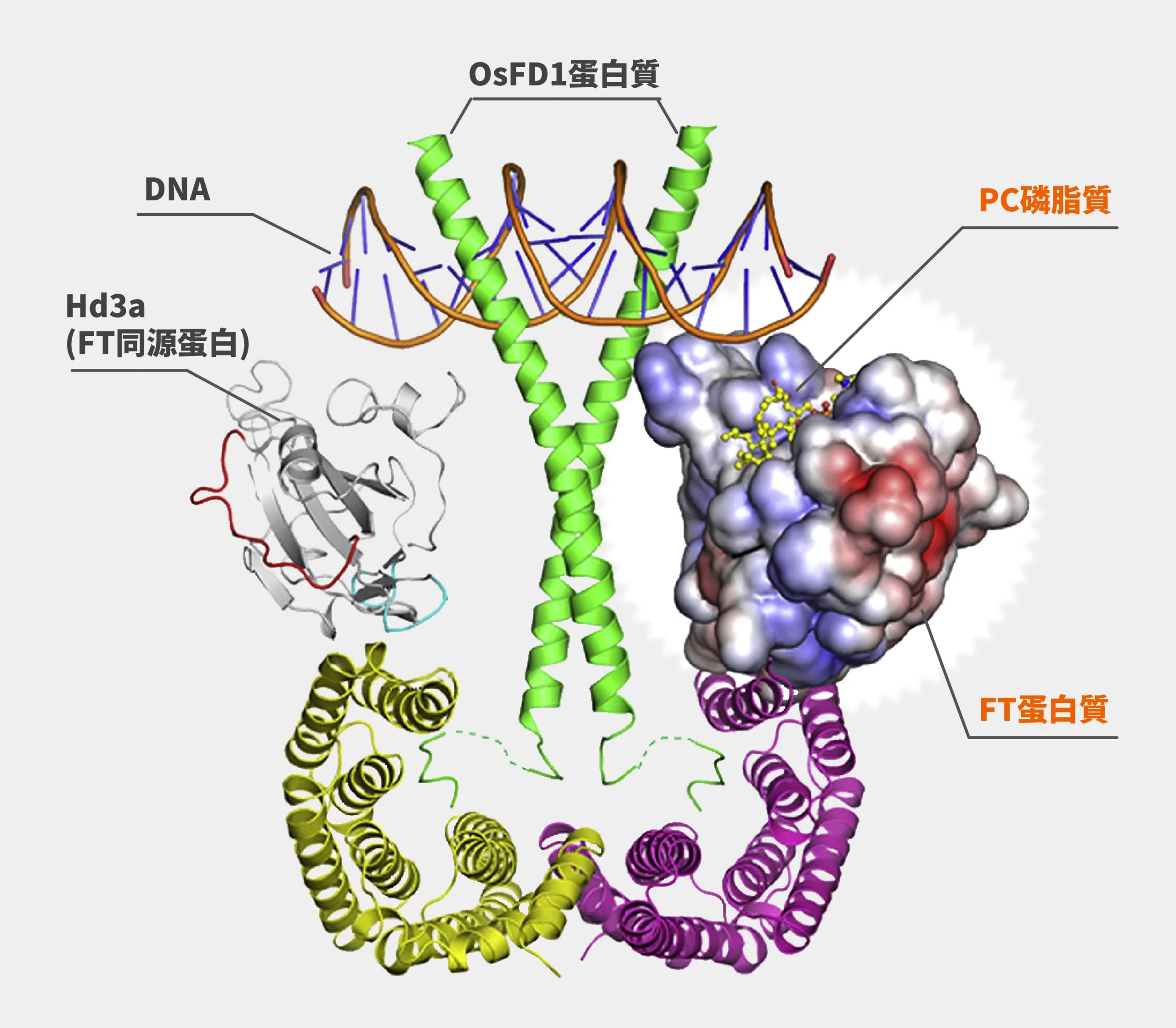
中村友輝表示,「我們注意到植物的 FT 蛋白質 3D 結構,跟人體中與脂質結合的蛋白質很像,這個蛋白質是磷脂醯乙醇胺(Phosphatidylethanolamine-binding protein,簡稱 PEBP 蛋白質)。雖然 FT 位在植物、PEBP 位在人體,但兩者構造相當相似。我們心想,既然人體的 PEBP 蛋白質可以跟磷脂質結合,植物的 FT 蛋白質是不是也能跟 PC 結合呢?PC 會不會跟調控開花有關? 」
脂質真的會影響開花嗎?用代謝切換工程實驗看看!
為了證實這個推測,研究團隊開始進行各種實驗,透過代謝切換工程去調控植物體內的 PC 磷脂質含量,觀察當 PC 變多或變少時,會如何影響 FT 蛋白質的功能,以及開花速度會變快或變慢。
具體應該怎麼做呢?首先要有關鍵酵素「PECT」,只要抑制 PECT 的合成,就會連帶減少 PC 的合成量,進而觀察對 FT 蛋白質的影響。目前是以人工方式製作一段 amiRNA(Artificial microRNA,人工微型核酸),送進植物體內後,它能跟 PECT 的 mRNA 互補並結合,導致 PECT 無法合成。
另一個方法是使用人工合成的啟動子(promoter,簡稱 p),啟動子是一段能讓特定基因進行轉錄的核酸片段。不同啟動子的功能不太一樣,例如啟動子 pFD,只有在頂芽裡才會驅動 FT 蛋白質合成;還有啟動子 pSUC2(Sucrose Transport 2),只在葉子維管束伴細胞(Vascular companion cells)裡才會驅動 FT 蛋白質合成,它專門跟一種藥物結合,實驗時可以透過藥物來控制。
團隊透過上述這些方法來控制 FT 蛋白質只在特定器官產生,再調控 PC 磷脂質含量增加或減少,藉此觀察脂質對開花的影響。
結果發現,如果在頂芽處讓 PC 磷脂質增加的話,的確可以促使開花。
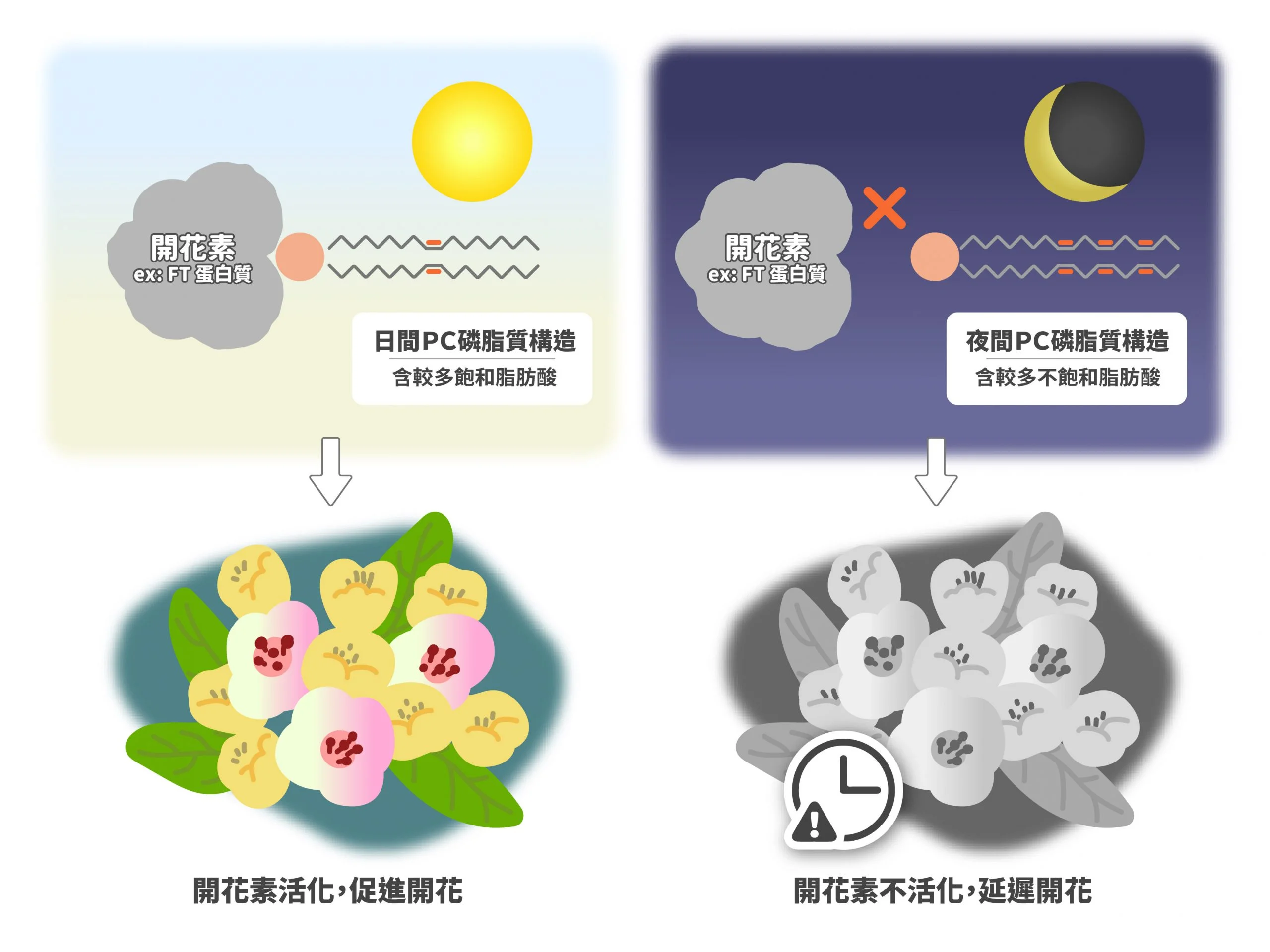
此外,還發現 PC 構造會隨日夜變化,白天時,PC 磷脂質主要是飽和脂肪酸,容易和 FT 蛋白質結合,促進開花;晚上時,PC 磷脂質主要是不飽和脂肪酸,難與 FT 蛋白質結合,不促進開花,開花時間延遲。
在植物的頂芽處,PC 磷脂質含量會影響開花,但是日夜情況不同。圖中的飽和脂肪酸是長碳鏈,不含紅色雙鍵。紅色雙鍵越多,表示不飽和脂肪酸程度越高。圖/研之有物(資料來源/中村友輝)
至於團隊有實際拍到 FT 蛋白質和磷脂質結合的模樣嗎?中村友輝說:「我們目前是用電腦模擬的方式,將 FT 蛋白質和磷脂質兩個分子的 3D 模型放在一起比對、計算,得知兩者最可能的結合方式。之前有嘗試用冷凍式電子顯微鏡(Cryo-electron microscopy)拍攝,但可能是 FT 蛋白質本身太小,沒有成功 ,希望未來有機會。」
這篇論文 於 2014 年刊登於「自然通訊」(Nature Communications)期刊,之後陸續有些科學家也在研究脂質對開花的影響,有的發現在維管束的脂質也會影響 FT 蛋白質傳送,有的發現水稻的開花素運作模式,跟本次實驗所用的模式植物阿拉伯芥類似。
不過,全世界的植物種類非常多,不同植物的生長、開花特性可能不同,像短日照、長日照植物所需日照時間不同,有些植物如曇花是晚上開花,有些植物是先開花才長葉,其他類型的開花機制仍待更多研究來解開。
中村友輝團隊研究磷脂質如何影響植物開花的機制,採用模式生物阿拉伯芥作為研究對象。圖/研之有物
用藻類酵素刺激產油
如果科學家能掌握並任意開關植物的代謝路徑,以後就能隨心所欲讓植物生長或開花並應用在農業上嗎?中村友輝指出,「一旦瞭解代謝途徑,到真的應用層面上,的確不是遙不可及。我們之前有一個研究,就是透過掌握酵母菌的代謝途徑,讓這些小生物生產大量油脂。」
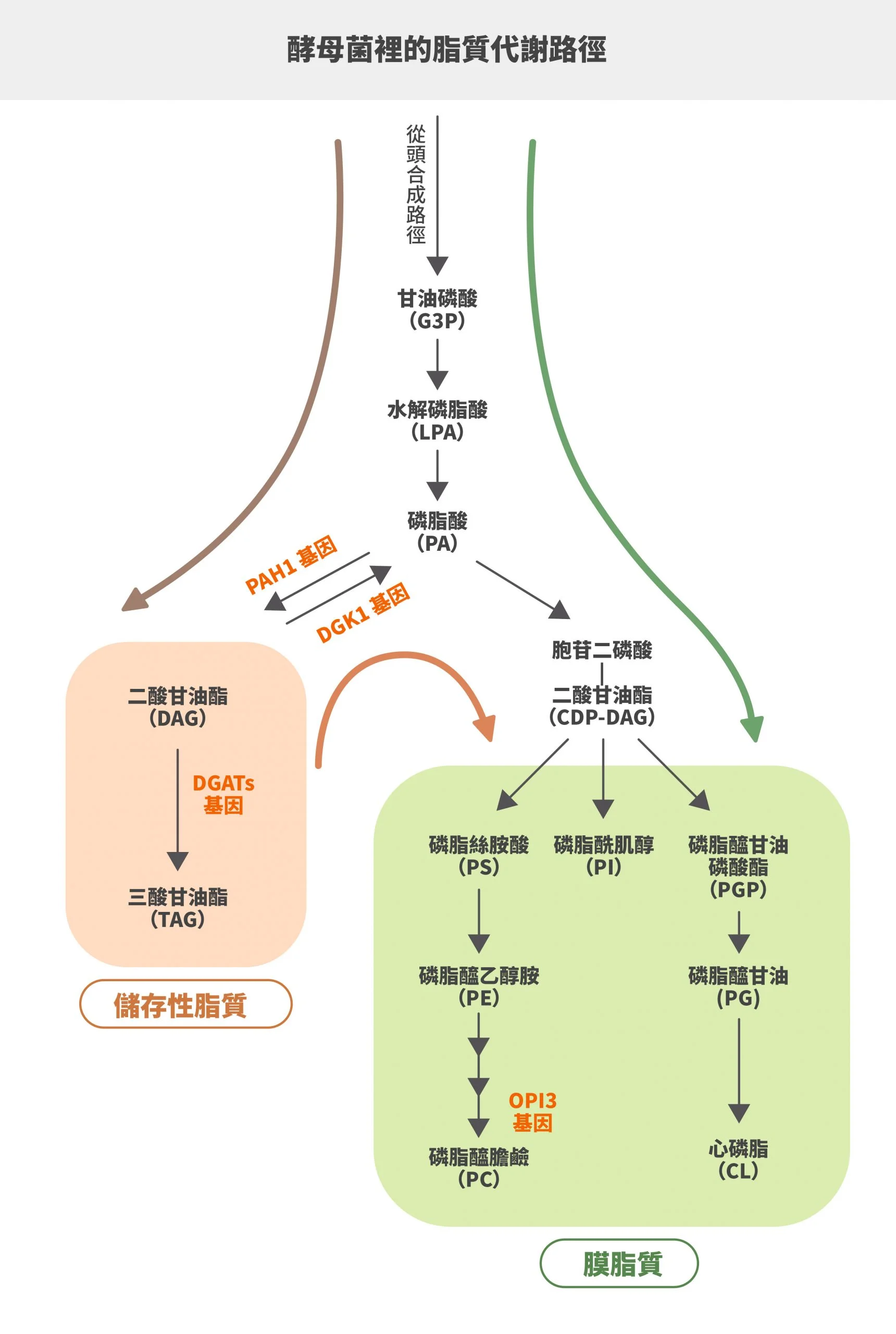
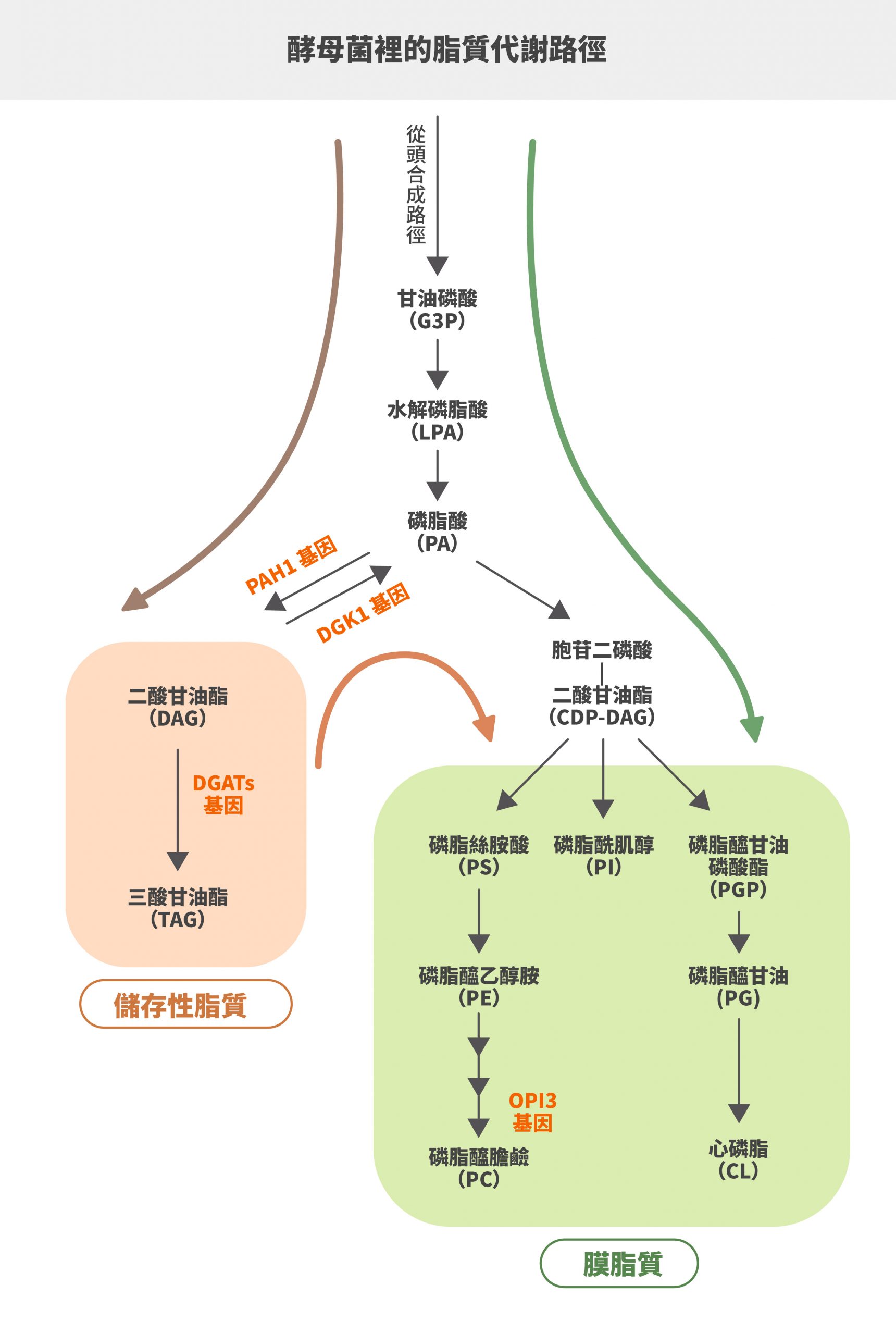
其實,科學家最早在研究代謝工程時就是以藻類、酵母菌和細菌等單細胞生物為主,每個細胞是一個完整生物體,而多細胞生物是一個個體有很多不同功能的細胞,相較之下,單細胞生物的代謝過程比多細胞生物單純許多。科學家研究酵母菌多年,幾乎瞭解脂質代謝路徑、參與調控的酵素,比較容易進行代謝工程。近年因為地球暖化問題,科學家研究如何以生質能源來替代石油,想透過酵母菌大量生產生質柴油,可惜遲遲找不到突破方法。中村友輝的團隊找到一個創新構想:將一種藻類酵素導入酵母菌,能讓產油量大幅增加。「不過,這個酵素被發現是一個意外。」中村友輝笑道。一開始中村友輝團隊是在分析藻類某種關鍵酵素 DGAT ,它是合成、儲存油脂的關鍵酵素,可以催化三酸甘油脂產生,有一群功能類似但構造不同的同分異構物,就像一個酵素家族。團隊將這些酵素的基因一個個抓出來,把它們導入酵母菌,想分析哪個酵素能讓酵母菌產油最多。最後研究團隊發現 DGAT2 能讓酵母菌產油量提升到野生酵母菌的 10 倍!其實,酵母菌裡也有同樣功能的酵素,但代謝效率、產油能力都沒有這個酵素 DGAT2 來得好,沒想到他們將酵母菌原本的酵素拿掉,運用外來的藻類酵素刺激,能讓酵母菌產油量突破以往極限。
酵母菌的脂質代謝路徑,上方路徑形成儲存性脂質(橘色),也就是 TAG(三酸甘油酯);下方路徑形成膜脂質(綠色)。如果要生產生質柴油,必須盡量讓酵母菌往儲存性脂質的路徑走。中村友輝團隊將酵母菌原本的酵素替換成含有 DGATs 基因的藻類酵素,發現產油量大幅增加。圖/研之有物(資料來源/Frontiers in Microbiology
中村友輝說道,「有些做代謝工程的方式是改寫整個代謝路徑,我們只是促進或抑制某個路徑,改動範圍沒有這麼大。這篇論文是少數做到應用層面的研究,但我們只有養少量的酵母菌,真正要做到工業級生產,需要其他專門的人。我們仍是以基礎研究為主,聚焦在發現基礎代謝途徑,找出各種未知代謝途徑或未知代謝物。畢竟要先瞭解基本的,才可能有後續應用。」
原來,植物脂質沒有大家想得那樣簡單,只是當作儲存能量而已,更對植物的生長與發育影響重大。中村友輝希望未來繼續探討這個似乎無窮無盡的植物脂質領域,找出更多嶄新的發現。
除了研究內容之外,喜愛植物和旅遊的科學家中村友輝,當初如何踏上科研之路?為何如此熱愛植物脂質領域?來臺灣工作多年又有什麼觀察與發現呢?
前幾年我去一場會議演講,詹姆斯·華生(James Watson ,DNA 雙股結構發現者)就坐在前面第一排,沒想到我竟然能跟這位崇敬的科學家一起分享自己的實驗,那是個非常值得紀念的日子!
花朵分成不同的器官像花瓣、雄蕊、雌蕊、花柱和花萼等,我驚訝的發現,花裡的脂質不但跟葉子、種子的脂質成分不一樣,而且在花朵的不同器官中,脂質成分竟然也不同。這讓我感到很有趣也很納悶:為什麼會有這麼大的差別?成為我開始深入探討脂質對開花影響的契機。
中研院植微所的前研究員中村友輝與當時的研究團隊合影。圖/研之有物


 不認同植物跟動物一樣有生命的人其實不在少數,但是最近發表在Current Biology上的這篇文章,應該會讓這些人停下來想一想。
不認同植物跟動物一樣有生命的人其實不在少數,但是最近發表在Current Biology上的這篇文章,應該會讓這些人停下來想一想。




































{kind=link}