過去也有多次政府發錢刺激消費的作法,但他們發的不是錢,而是有使用限制的「消費券」。
既然可以發錢,為什麼之前要發消費券呢?這次又為什麼要發現金?
從經濟學的角度來看,過往的消費券到底是什麼,與這次發現金的使用情境有什麼不一樣?
什麼是消費劵
對消費者來說,消費券就是被限定用途的紙鈔或者是折價券;但從政府的角度,或從經濟學的角度來看,消費券並非這麼簡單。在了解消費券前,要先有兩個概念:「經濟活動循環」及「景氣循環」。
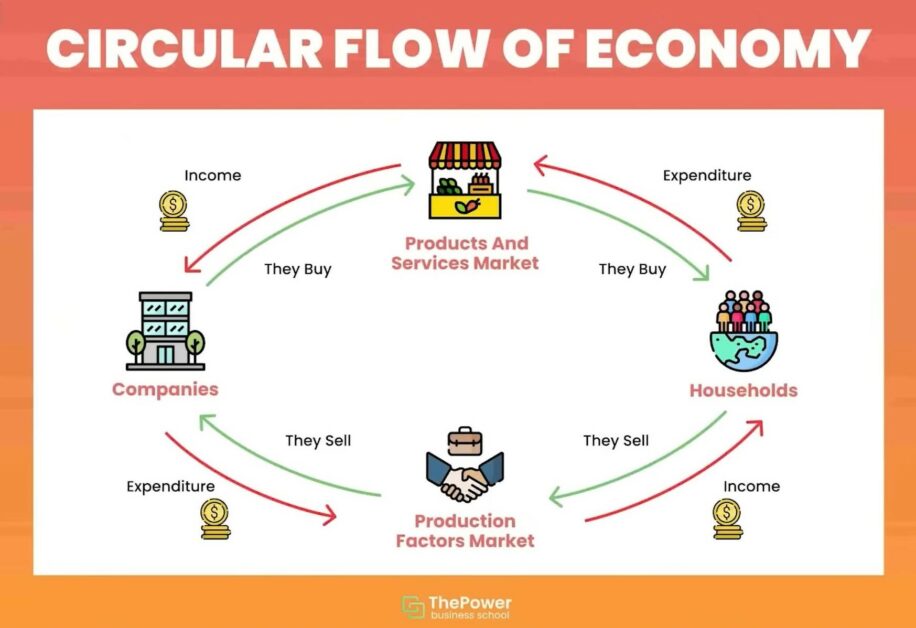
在最簡單的經濟行為流程裡,我們看的是「家計部門」與「廠商」,也就是消費者與生產者之間的互動。「家計部門」需要買各式各樣的產品維持生存或生活品質,「廠商」則提供這些產品,這兩者組成了「產品市場」;「廠商」為生產商品所需的勞動力,就由「家計部門」提供,形成了「勞動市場」或是「生產要素市場」。
將上述概念再加入相反的資金流向,如:購買產品的消費支出、提供勞動力的薪水所得等,就可繪製成「經濟活動循環圖」。
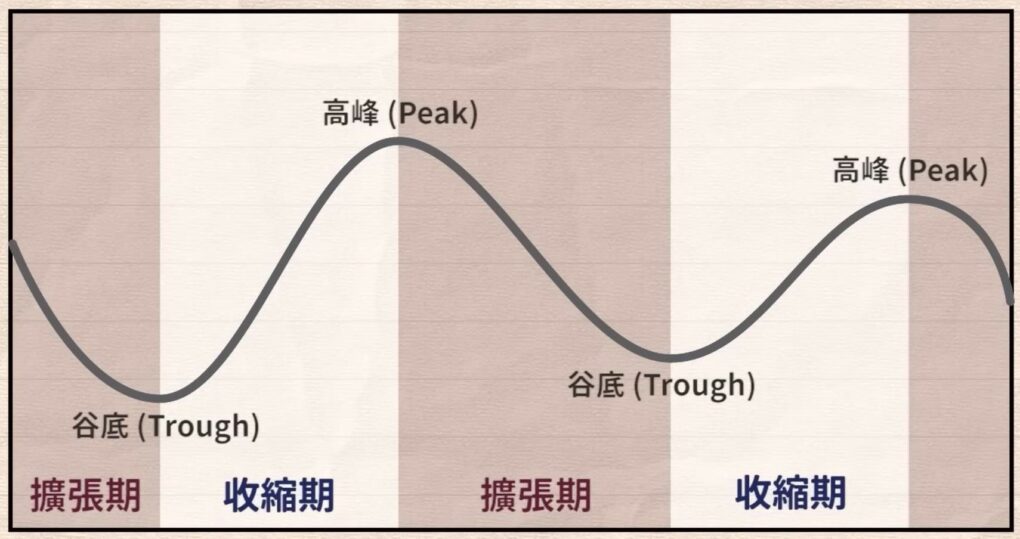
而在一次的「景氣循環」中,會分別經歷擴張期與收縮期;根據國家發展研究院的定義,每個時期所持續時間的至少為 5 個月,走完一次循環則需至少 15 個月。
在擴張期中會先經歷探底復甦,接者是穩定成長,最後來到高峰繁榮期;在這之後就會進入收縮期,開始經濟衰退,直到觸底復甦進入新循環。
舉一個不遠的經濟衰退案例,那就是 2008 年全球金融危機。當時由於美國房地產市場崩潰,房價急劇下跌,許多人失去了房屋資產,造成負債問題;導致消費者信心下降、消費減少,進而使生產減少。此外,由於銀行與金融機構資產負債問題激增,使得貸款停止,造成資金不流動;這麼一來企業也必須減少生產,進而裁員、倒閉,失業率隨之攀升。
有了「經濟活動循環」和「景氣循環」概念,我們可以幫消費券下個定義了:就是透過增加家庭的消費支出,來復甦產品市場;通常在經濟衰退時使用。也就是說,消費券是政府發給我們的消費工具,希望再補點錢把廠商的庫存清光,增加消費來維持市場穩定,避免持續經濟衰退。
發消費券與現金的成效
那麼,直接發錢跟消費券的功能一樣嗎?發現金也會刺激消費,但消費券刺激的力道理論上會再強一些。
由於消費券在設計上會「排除基本必須開支」,這麼一來便會減少用於「消費替代」的機會,像是水電費、勞健保費、或是繳稅跟罰金,而消費券的各種優惠跟加碼活動,都激勵我們花超過原本支出的錢。另外,「限時用完」、「不找零」、「排除儲值跟預付類消費」都是消費券的關鍵設計,目的就是要在短時間內激發經濟流動性。
反過來說,發現金不像消費券,有明確的優惠活動可以刺激我們亂花錢,在沒有使用期限跟排除開支項目的情況下,這些錢還可以自由分配到每個月的日常支出裡;假如沒有多花一些錢,發的現金將不會幫助消費增長。
新冠疫情影響下,美國在 2020 年普發現金:成人發 1200 美元、兒童 500 美元,年底再加碼 600 美元,2021 年又發 1400 美元。根據美國聯準會紐約分行研究,截至 2020 年 6 月底,民眾取得的現金補助中,有 36% 為儲蓄、35% 償還債務,僅 29% 用於消費,民眾甚至表示,在收到 2021 年的補助金後,會花更多錢去還債。
而日本則於 2021 年底,向全民普發 10 萬日圓的特別定額給付金,日本 Money Forward Lab、早稻田大學與澳洲昆士蘭大學的共同研究研究指出,給民眾的給付金中,只有 6% 到 27% 用於消費,其中非日常用品的支出沒有明顯改變。
那消費券的成效呢?根據經濟部對 2020 發放的振興三倍券評估成效,考量印製、宣傳與行政,包含發給我們的 2000 元,總成本為 510.5 億元,以領取率接近 100% 來計算,大約就是 2300 萬人去攤這 510.5 億,政府在每一個人身上花約 2220 元,而每人平均消費了 5785 元;等於政府花 1 元能換來 2.6 元的消費,是有效果的。
不過由於使用情境不同,不好將日美發放的現金與我們的振興券相比較。
日美發放的是「紓困金」,目的是幫助人民度過難關;針對這些「紓困金」得用社會投資報酬率(SROI)來考慮,也就是衡量投入資源,所得到「非財務面」的回饋與報酬,例如社會安全、社會價值等。
搞笑諾貝爾經濟學獎
那這次台灣發現金的目的到底是什麼呢?假設是要振興經濟,應該不是個好方法。若用社會投資報酬率來看,不少人提出更該把要拿來發的 1800 億用於投資科學技術研究、大學經費或減免高等教育學費,而非普發 6000。
讓我們回顧 2022 年搞笑諾貝爾經濟學獎,研究團隊以每隔五年會獲得「政府資金」補助,並在模型裡設計了好幾種情境,除了把經費徹底平均分配的普發式外,還有只補助過去表現好的人的菁英式,一部分重點補助菁英,剩下再普發的折衷式,以及最後一個亂槍打鳥樂透式。每一式再加入補助金額高低變化,總共有 18 種方案。
延伸閱讀:
【2022 年搞笑諾貝爾經濟獎】不想努力的我,把運氣點滿就對了
透過這個人生遊戲模組,若以研究定義的成功率來看,折衷式的其中一種方案讓「高能力族群」的成功率從沒有補助的 32.05% ,一口氣提高到 94.82%,其結果最好,但也是所有方案中最貴的;相較之下,如果採取普發式的其中一種方案,成功率也可以達到 94.40%,政府花費還低了將近一半。
若不只看成功率,而是看政府每花一塊錢能增加多少高能力族群成功率的效率來判斷,竟然還是普發式的方案結果最好,能用最少的花費,就讓成功率提升到 69.48%!表現最差的方案,都是菁英式,其中只把錢給過往表現前 10% 的極端菁英方案,效率只有最佳普發方案的 1/25。
研究者也提到,在真實世界中,折衷式方案一方面人人有獎,一方面也給表現較好的人鼓勵,可能產生激勵效果,讓所有人都更加努力,發揮更大的整體效果。
再回到一開始討論的,現在政府有一筆多出來的錢,而預期目標是讓人民的生活過得更好,這筆錢該直接給民眾,還是執行特定的菁英投資政策呢?若是按照搞諾經濟學獎,就是直接普發!(難道政府裡也有和我們一樣熱愛搞笑諾貝爾獎的好捧油?XD)
然而,不管是從經濟學基本原理、過往發現金跟消費券的效益評估,還是搞笑諾貝爾經濟學獎的人生遊戲模型,其實都無法替普發 6000 還稅於民的政策效果背書,一時半刻也很難看出效益。
說到這裡,6000 元你打算怎麼花呢?
歡迎訂閱 Pansci Youtube 頻道 獲取更多深入淺出的科學知識!