- 文/林立芸
科普社群泛科學以科普文章起家,並在 2015 年推出系列動畫,以生動而簡單的畫面帶大家窺探背後的科學知識。這次,2016 泛・知識節便邀請到泛科學的動畫團隊,分享動畫製作過程。
本場講座以「Mouse 編和他的愉快小夥伴」為主題,主編雷雅淇一開始先問大家有沒有看過泛科學動畫、或是有從事動畫相關工作的夥伴,現場有不少人舉手。
雷雅淇介紹,泛科學的動畫系列以「科學大爆炸」為名,不同主題的動畫會在社群上接觸到不同的受眾,例如《咖啡迷思與提神攻略》動畫便有美容 SPA 粉絲專頁分享。目前,泛科動畫團隊已經製作將近 40 支動畫,榮登目前最多人次觀看的是《小強!你怎麼了小強》系列影片,加上臉書分享總共有 500 多萬次觀看。

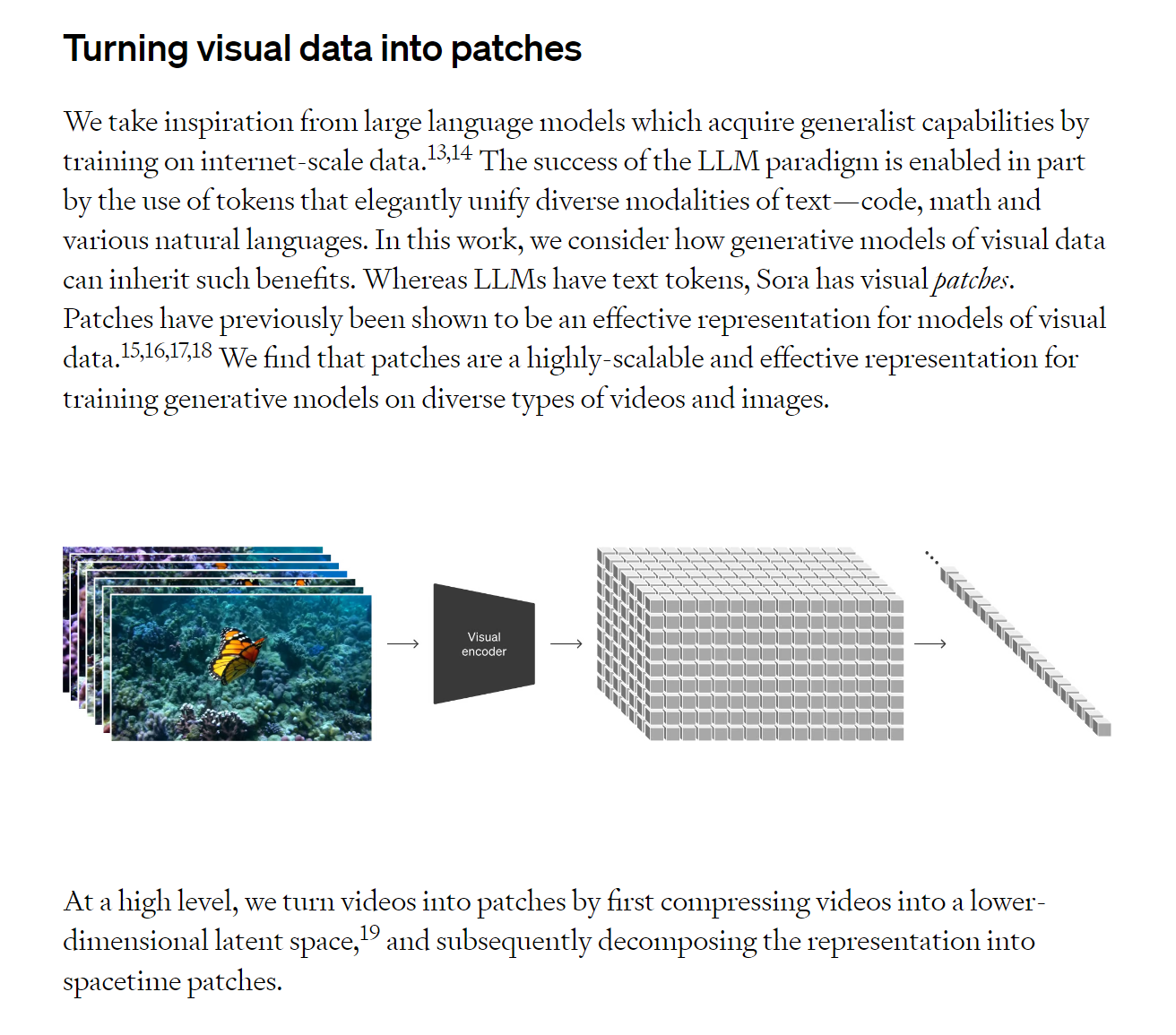
從零到一:泛科動畫製作大解析
接著,雷雅淇舉《 夏日大作戰:防蚊攻略 & 迷思 》動畫為例,說明泛科動畫團隊製作「從無到有」製作動畫的流程。
「每隻動畫大約需要 6 週的時間製作,包括從腳本發想、分鏡繪製、動畫繪製、動畫製作、後製音效到音效合成,音效較專業的部分還需另外和外部團隊合作。而多數人大多會問,為什麼要選定這個主題?」
她說,主題的發想可分類為:時事(聖誕節)、生活科學(負離子吹風機)、冷科學(相對論)、編輯私心熱愛領域(青蛙)或宅科學(搞笑諾貝爾獎)、甚至是聚焦台灣土地(土壤液化)等等,通常從這些大方向開始,再經由編輯們開會討論限縮題目,最後擬定出具體製作主題。
以《夏日大作戰:防蚊攻略&迷思 》為例,當時為 5 月,原本想聚焦 2016 里約奧運帶來的茲卡病毒議題,加上剛好台灣開始關心南部的登革熱疫情,因此想做些結合時事又兼具生活教育的內容,最後發想出《夏日大作戰:防蚊攻略&迷思 》題目。「泛科學背後有上百位專業的作者擔任顧問群,寫好腳本後,我們也會找具備該領域的專業顧問審查。」
自創角色:Mouse 編
動畫繪製者 ─ 林梳雲負責的是整部動畫的視覺呈現,包含場景、物件、角色設計。「動畫繪製是繪製、也是設計,可以說是在顧及自身作畫的質與量。必須正確掌握分鏡的內容,才能在忠實描繪畫風的同時,也使整部作品從單純的意念,轉化為展現給他人看的畫面。」
她也提到設計 Mouse 編的趣事,「主角 Mouse 編,其實代表著『白老鼠』默默為科學界貢獻,這些實驗室小白鼠是奠定科學家很多理論和來源的重要功臣。我們的角色也不適合畫人類,因為人會與現實生活中的人有所對應。」

動畫師的浪漫:動態的準確與細緻
動畫師 Tino 說:「能在泛科團隊中做原創動畫,是很幸福的一件事情。台灣的動畫師常因為商業需求或各種考量,無法隨心所欲做自己想做的事情;迎合時事做的內容也會有時間限制。泛科學的知識內容不會因時間改變,而且對社會有意義價值存在。」
他認為,動畫師最重要的技能可以歸納成一個重點:將平面的動畫繪製圖,轉化成連續動作,因此,動畫師需要拿捏動態的準確性與細緻性。
Tino 說自己曾為了畫出穿高跟鞋的動態感,在辦公室穿高跟鞋模擬;在畫《新世紀福音戰士》的角色使徒時,也不斷在辦公室模擬丟標槍,嘗試呈現動作的準確性。
「雖然,一般人並不會看見這些細節,大家通常關心動畫好不好看,喜不喜歡;但是將觀眾喜歡的、投射的做出來,便是動畫師的價值所在。」
浪漫後的現實:做動畫的美麗與艱辛
當然,身為科普社群,泛科動畫最常遇到的問題還是資料的正確性。三人笑說,泛科學動畫總能引出該領域中的民間高手,在臉書留言串討論「這個結論正確嗎?」、「數字正確嗎?」而對團隊來說,引起正反兩方的討論是常見的,或者換個角度想:影片下方長長的留言串,對團隊來說正是最大的動力來源之一。
聊到之後想嘗試的泛科動畫主題,生物、太空、經濟、地科、料理、心理…「只能說有太多想做,永遠沒辦法做到滿足啊。」主編雷雅淇說。