
什麼?不需要拍攝團隊與剪輯師,一句話就可以生成短片?!
OpenAI 近來發布的短影片生成器——Sora,能依據各種「咒語」生成難分真偽的流暢影片。
是什麼技術讓它如此強大?讓我們來一探究竟吧!
你被 Sora 了嗎?這幾天 Sora 佔據了各大版面,大家都在說 OpenAI 放大絕,不止 YouTuber,連好萊塢都要崩潰啊啊啊!
但真有這麼神嗎?我認真看了下 Sora 的官方說明以及參考資料,發現這東西,還真的挺神的!這東西根本不是 AI 取代人或單一產業,而是 AI 變成人,根本是通用型人工智慧 AGI 發展的里程碑啊!
別怕,要讓 Sora 為你所用,就先來搞懂到底是什麼神奇的訓練方法讓 Sora 變得那麼神,這就要從官網說明中唯一的斜體字——diffusion transformer 說起了。
這集我們要來回答三個問題,第一,Sora 跟過去我們產圖的 Midjourney、Dall-E,有什麼不同?第二,Diffusion transformer 是啥?第三,為什麼 Diffusion transformer 可以做出這麼絲滑的動畫?
最後,我想說說我的感想,為什麼我會覺得 Sora 很神,不只是取代坐在我旁邊的剪接師,而是 AI 變人的里程碑。
我們已經很習慣用 Midjourney、Dall-E 這些 Diffusion 模型產圖了,從 logo 到寫真集都能代勞,他的原理我們在泛科學的這裡,有深入的解說,簡單來說就像是逐格放大後,補上圖面細節的過程。不過如果你要讓 Diffusion 產影片,那後果往往是慘不忍睹,就像這個威爾史密斯吃麵的影片,每一格影格的連續性不見得相符,看起來就超級惡趣味。
要影格連續性看來合理……咦?像是 GPT-4 這種 tranformer 模型,不是就很擅長文字接龍,找關聯性嗎?要是讓 transformer 模型來監督 Diffusion 做影片,撒尿蝦加上牛丸,一切不就迎刃而解了嗎?
沒錯,OpenAI 也是這樣想的,因此才把 Sora 模型稱為「Diffusion transformer」,還在網站上用斜體字特別標示起來。

但說是這樣說啦,但 transformer 就只會讀文本,做文字接龍,看不懂影片啊,看不懂是要怎麼給建議?於是,一個能讓 transformer 看懂圖片的方式——patch 就誕生啦!
ChatGPT 理解內容的最小單位是 token,token 類似單詞的文字語意,ChatGPT 用 token 玩文字接龍,產生有連續性且有意義句子和文章。
那 Patch 呢?其實就是圖片版的 token,讓 ChatGPT 可以用圖片玩接龍,玩出有連貫性的圖片。
Sora 官方提供的訓練說明圖上,最後所形成的那些方塊就是 patch,這些 patch 是包含時間在內的 4D 立體拼圖,可以針對畫面與時間的連續性進行計算。
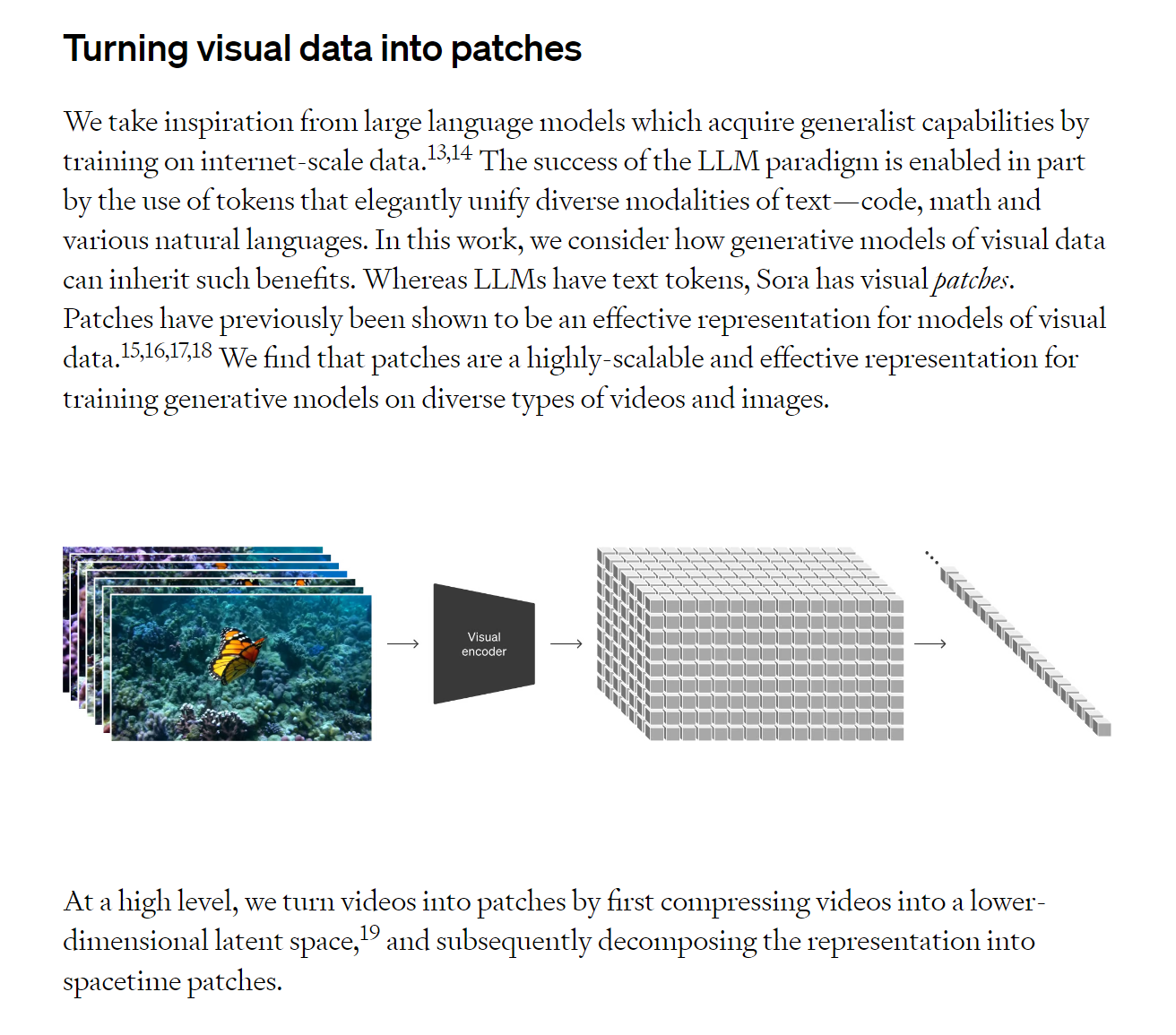
那這個 patch 要怎麼做呢?以 Sora 提供的參考文獻 15 來說明會比較容易懂,patch 是將影像切成一樣等大的區塊後,進行編碼、壓縮,產生類似 ChatGPT 能分析的文字語意 token。
有了這些 patch 後,Transformer 就可以計算 patch 之間的關聯性形成序列,例如論文中被分割在中上與右上的兩塊藍天,就會被分類在天空,之後算圖的時候,就會知道這兩塊 patch 是一組的,必須一起算才行。
也就是說,畫面上的這塊天空已經被鎖定,必須一起動。
雖然這篇論文只提圖片,但影片的處理只要再加上 patch 間的先後順序,這樣就能讓 transformer 理解隨時間改變的演化。
同樣是上面被鎖定的天空,多了先後順序,就相當於是增加了前一個影格與後一個影格限制條件,讓這塊天空在畫面中移動時,被限縮在一定範圍內,運動軌跡看起來更加合理。
而他的成果,就是在 Sora 官網上看到的驚人影片,那種絲滑的高畫質、毫無遲滯且高度合理、具有空間與時間一致性的動作與運鏡,甚至可以輕易合成跟分割影片。
不過啊,能把 Sora 模型訓練到這個程度,依舊是符合 OpenAI 大力出奇跡的硬道理,肯定是用了非常驚人的訓練量,要是我是 Runway 或 Pika 這兩家小公司的人,現在應該還在咬著牙流著血淚吧。別哭,我相信很多人還是想要看威爾史密斯繼續吃義大利麵的。
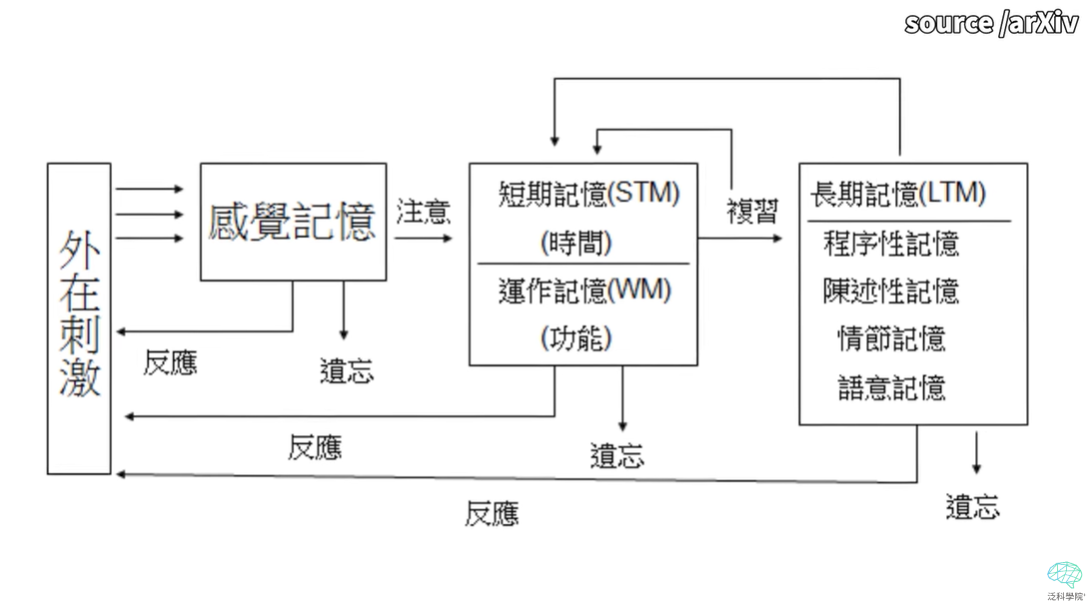
在訓練過程中,Sora 從提取影像特徵,到形成有意義的 patch,到最後串聯成序列,如果你接觸過認知心理學,你會發現這其過程就跟認知心理學描述人類處理訊息的過程如出一轍。都是擷取特徵、幫特徵編碼形成意義、最後組合長期記憶形成序列,可以說 Sora 已經接近複製人類認知過程的程度。
這邊是我的推測,影片中那些逼真的物理效果,不是有特定的物理模型或遊戲引擎在輔助,而是在 patch 的訓練與序列推理中,就讓 Sora 理解到要讓物體這樣動,看起來才會是真實的,這跟 GPT-4 並不需要文法引擎是一樣的,只要玩文字接龍,就能生成流暢又有邏輯的文字跟代碼。但這也是為什麼,GPT 依舊很會胡說八道,產生幻覺。如果不是這樣,我很難想像 Sora 會算出這種影片。

Sora 能理解並產生人類眼睛能接收的視覺影片,同樣的技術若能做出聽覺、觸覺等其他人類感官,這樣我們被 AI 豢養的時刻是不是就越來越近了呢?
後 Sora 時代到底會發生什麼事,老實講我不知道,上面提到的 diffusion transformer 或 patch,都是近一年,甚至是幾個月前才有研究成果的東西。
臉書母公司 Meta 的首席人工智慧科學家 Yann Lecun 也在他自己的臉書公開抨擊 Sora 這種基於像素預測的技術註定失敗,但這篇感覺比較像是對自己的老闆 Zuckerberg 喊話:「欸這沒戲,不要叫我學 Sora,拿寶貴的運算資源去搞你的元宇宙。」是說今年初就有新聞說祖老闆 2024 年預計買超過 35 萬顆 H100 處理器,這明顯就是要搞一波大的吧,這就是我想要的血流成河。
而且,從去年 ChatGPT 出來開始,我感覺就已經不是討論 AI 會怎麼發展,而是要接受 AI 必定會發展得越來越快,我們要怎麼面對 AI 帶來的機會與衝擊。
我們去年成立泛科學院,就是希望跟大家一起,透過簡單易懂的教學影片,把對 AI 的陌生跟恐慌,變成好奇與駕馭自如。Sora 或類似的模型應該可以協助我把這件事做得更好,可惜的的是目前 OpenAI 僅開放 Sora 給內部的 AI 安全團隊評估工具可能帶來的危害與風險,另外就是與少數外部特定的藝術家、設計師跟電影製片人確保模型用於創意專業領域的實際應用,若有新消息,我會再即時更新。
最後也想問問你,若能用上 Sora,你最想拿來幹嘛呢?歡迎留言跟我們分享。喜歡這支影片的話,也別忘了按讚、訂閱,加入會員,下集再見~掰!
更多、更完整的內容,歡迎上泛科學院的 youtube 頻道觀看完整影片,並開啟訂閱獲得更多有趣的資訊!


































