
江殷儒
中央研究院生物多樣性研究中心 副研究員
台灣微生物歲時記

蓄水、防洪還能發電,萬用的翡翠水庫
住在臺北都會區的小確幸之一,就是品質優良的自來水。相信待過台灣西部其他城市的朋友們,都會心懷感激地用力點頭。首都台北的都市傳說之一,就是以為臺北自來水的主要水源來自翡翠水庫。
事實上,我們使用的自來水主要來源是南勢溪(佔 75% 左右)。翡翠水庫作為備用水源,調蓄供應公共用水。此外,翡翠水庫亦有發電及防洪等功能。翡翠水庫位於新店溪支流北勢溪之上,是型態極為狹長的水庫,上游起始於坪林附近,範圍涵蓋新北市的新店區、石碇區以及坪林區。

水庫興建於 1970年代,集水後淹沒了北勢溪原有的許多景點如翡翠谷與鷺鷥潭,也淹沒了烏來杜鵑的野生族群;但同時也創造了千島湖(位於水庫中段)等臺北新景點。如果有機會,搭乘水庫管理局的採樣船自大壩往坪林逆流而上,你將能體會前赤壁賦「縱一葦之所如,凌萬頃之茫然」的暢快。運氣更好的話,晴天時能望見數十隻黑鳶在水庫上空盤旋的奇景。


實際現場走一回,咦?為何水庫褐褐綠綠的
水庫的大壩目前並不開放觀光,進入主壩需向翡翠水庫管理局申請許可。但是驅車從坪林沿著台九線往新店方向,仍然可以經由產業道路進入水庫上游的黃櫸皮寮及灣潭,飽覽翡翠水庫的山光水色。附近的灣潭古道蜿蜒於灣潭溪,沿途綠樹蔭茵,流水潺潺,極盡視聽之娛。當你來到灣潭附近,眺望水庫,觸目所及是漫山遍野的大片茶園。

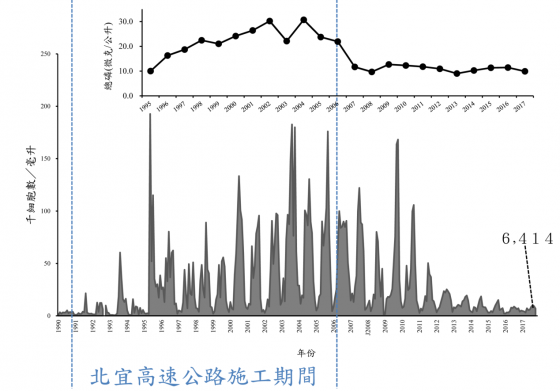
種植茶葉必須的肥料,尤其是氮肥與磷肥,無可避免地進入水庫,造成水質優養化,引發藻類的生長。水庫優養化的常用指標為卡爾森優養指數法。此方法根據透明度、水中葉綠素 a 及總磷量來決定優養化程度:指數小於 40 為貧養;40 到 50 之間為普養;大於 50 為優養等級。
簡單的講,淡水湖泊與水庫通常是缺磷的環境;磷酸鹽的輸入會造成藻類(主要色素是葉綠素 a) 生長,進而減低湖水的清澈程度。自水庫蓄水以來,中央研究院生物多樣性研究中心的退休研究員吳俊宗博士長期監測水庫藻類的種類與密度,時間持續 25 年之久。
這項重要的長期監測工作 4 年前由筆者接棒進行。我們的研究結果顯示,相對於茶園的肥料使用,集水區的大型開發工程,例如雪山隧道的興建,對水庫水質的影響更為鉅大。工程會導致大量磷酸鹽從土壤岩石中釋出,進入水庫,導致藻類的大量生長。即使工程停止,藻類密度也需經過 5 年左右的時間,才能回復到工程開發之前的貧養狀態(卡爾森指數年平均在 40 以下)。
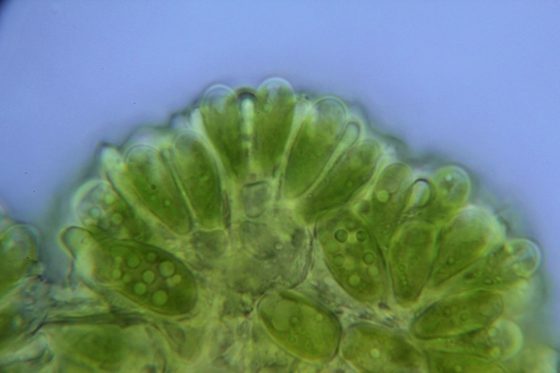
水庫內的葡萄藻也會產油酸?
近年來,翡翠水庫偶爾會出現大量的葡萄藻,導致水面上漂浮著許多褐棕色的團塊。這種形態特殊的群聚型綠藻,最適合的生長水溫約 20 至 23 度之間,因此常出現在春夏之交的貧養溫帶及亞熱帶湖泊及水庫。當水體的磷酸鹽濃度升高時,常會造成葡萄藻的優勢。十年前在花蓮鯉魚潭曾有數次葡萄藻藻華的發生。
我們(當時我是碩士班學生,指導者是吳俊宗教授)發現葡萄藻會生成大量的不飽和脂肪酸,例如亞麻油酸。這些不飽和脂肪酸會廣泛地抑制其他藻類(影響細胞膜結構及離子通透)及浮游動物的生長。也就是說,葡萄藻會製造生化武器來攻擊競爭對手或是攝食者。

除了造成湖泊與水庫的藻華,葡萄藻更引人注目的是生質能源的應用潛力。葡萄藻能產生大量的三萜類脂質 (triterpene),最多能佔到細胞乾重的一半,形成它那著名的褐色膜鞘結構,也是”葡萄藻”名稱的由來。
這些脂質與原油的結構已經很相近,經過簡單的轉化即可當成生質能源利用。可惜的是,至今尚未找到大量培養葡萄藻的方法。也就是說,湖泊水庫常大量發生,甚至造成生態問題;但實驗室環境卻無法穩定培養,且往往失去特徵性的膜鞘(三萜類脂質),僅剩下綠色的藻細胞,因此失去了生質能的用途。這讓我想起我的德國指導教授 Georg Fuchs 博士常常對我說的話:「微生物學,始於培養,終於培養。」微生物的分離培養與發酵技術,是生技利用的基礎與關鍵!
參考文獻
- Wu JT, Chiang YR, Huang WY, Jane WN 2006. Cytotoxic effects of free fatty acids on phytoplankton algae and cyanobacteria. Aquat Toxicol 80: 338-345.
- Chiang YR, Huang WY, Wu JT 2004. Allelochemicals of Botryococcus braunii (Chlorophyceae). J Phycol 40: 474-480.
- Banerjee A, Sharma R, Chisti Y, Banerjee UC. 2002. Botryococcus braunii: a renewable source of hydrocarbons and other chemicals. Crit Rev Biotechnol 223:245-279.

本文轉載自MiTalkzine,原文《夏天翡翠水庫的葡萄藻》
歡迎訂閱微雜誌MiTalkzine,加入 MiTalker 的行列,一起來認識這個星球上千萬種各式各樣的微生物吧!








































{kind=link}
{kind=link}
{kind=link}