
- 作者/吳育瑋 臺北醫學大學醫學資訊研究所助理教授
這篇文章是我在讀到 Nature Methods 在 2018 年 3 月 5 日刊登的文章「Using deep learning to model the hierarchicalstructure and function of a cell」1後,在臉書 MiTalk 社團寫下的三篇短文的整理集結。在這三篇短文中,我簡要地介紹了目前人工智慧的技術基礎「類神經網路」的概念,再將其延伸到這篇文章提及的系統生物學研究,並解釋目前類神經網路之所以被稱為「黑盒子」的原因,以及這項系統生物學研究處理黑盒子的手法。
資訊輸入和輸出,如何用「類神經網路」做出無人車?
我們先來聊聊目前機器學習中最火紅的演算法「類神經網路」究竟是什麼東西?
動物的神經元大致上都有著可以接受來自其他神經元的訊號的樹突 (dendrite),以及可以傳送訊號給其他神經元的軸突 (axon)。類神經網路的單位神經元架構與生物的神經元類似:都有著數個可以接受其他神經元的「輸入 (Input)」,以及數個傳送訊號給其他神經元的 「輸出 (Output)」。將一大堆這樣子的神經元連結起來,就是類神經網路了。
當然,這種連結也不是亂連的。類神經網路通常會分成好幾「層」,而每一層與每一層之間的神經元都會緊密連結著 (fullyconnected),以下我用個實際的例子來說明這所謂的「層」是怎麼回事。
在 1989 年的時候,卡內基美隆大學發明了第一台透過類神經網路控制的無人車 ALVINN 2。這台無人車的主要架構有三個:一台在車子前面隨時拍照的照相機或攝影機,一台執行類神經網路運算的電腦,以及由電腦控制的方向盤,請參考下圖:
- 第一層(最底層):照相機照出來的 30 x 32 個 pixel 的影像,以及8 x 32 個雷射距離測定器像。總共輸入單位是 30 x 32 + 8 x 32 = 1216 個。
- 第二層(中層):由 29 個類神經網路神經元構成的隱藏層(最初期的設計只有4 個)。
- 第三層(最上層):45 個輸出神經元,代表著方向盤要打那個角度;每個神經元代表一個角度,例如第一個神經元代表方向盤往右打 30 度,第二個代表方向盤往右打 28 度,依此類推。
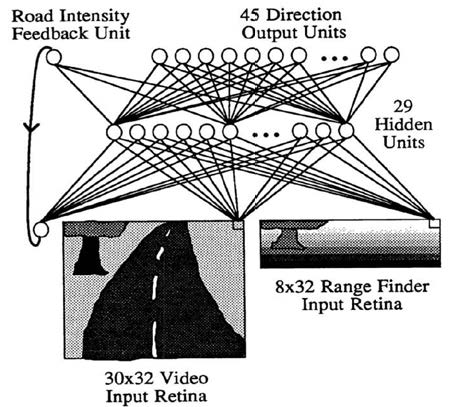
這麼簡單的類神經網路,就已經可以讓這台車在路上以 60 英哩的速度行駛了。可見得類神經網路機器學習的威力。
那麼類神經網路是怎麼訓練的呢?簡單地說,我們在訓練類神經網路時,必須要給它一組(通常是數量很多的一大組)已經知道正確答案的訓練樣本,讓類神經網路之間的神經元連結可以自動透過輸入訊號與正確答案的比對調整自身的參數。這樣的訓練會持續上數千或甚至數百萬次,直到正確率無法再提昇為止。比如說 ALVINN 無人車的訓練就是在真人開車時,將每張相機照出來的圖片與人類開車者的方向盤角度(也就是正確答案)進行連結,並持續調整參數直到答案錯誤率很低為止。
換句話說,ALVINN 這台無人車所做的事,就是模仿人類的開車行為。
除了無人車,「類神經網路」也能區分生物種類?
在上一段我們解釋了何謂類神經網路。一句話總結的話就是類神經網路就是連結在一起的人工神經元,而且可以透過無數次訓練盡量提高執行任務(比如說下棋或預測天氣)的準確率。在這一段中我將提到類神經網路與生物網路之間的關係。
類神經網路通常是由許多的「層」數以及每一層內的「神經元」數量所構成的;然而究竟需要多少層網路,或是每一層網路需要多少神經元,則沒有一定的準則。
我認為這是類神經網路最關鍵,卻也最難以決定的參數。舉例來說,先前提到過的自駕車 ALVINN 總共只有一層網路(不考慮輸入與輸出層的話),且這一層只包含 29 個神經元節點。但是現在如 Tesla 或其他品牌自駕車的類神經網路絕對比這個架構複雜許多。我們在設計類神經網路的時候,甚至需要不停地 trial-and-error 後才能決定「最佳」的網路架構,而這裡的「最佳」理所當然是由預測準確率來決定的。
那麼這和微生物或生命科學有什麼關係呢?這要先從一篇Nucleic Acids Research 論文3 講起。在這篇論文中,卡內基美隆的研究人員試圖透過類神經網路試圖研究不同的細胞(比如說胚胎分化時期的 early-2-cell、late-2-cell、8-cell、16-cell,或不同種類的細胞如 fibroblast、BMDC、以及上皮細胞等),並查看這些細胞的基因表現是否有著明顯的差異。他們的研究標的是不同研究團隊定序出來的 single-cell RNASeq 資料。
簡單來說,他們希望將許多人體內不同種類細胞的 RNASeq 資料透過類神經網路處理後,能夠過濾雜訊,留下最清楚的基因表現訊號。其最終目的當然是透過分群演算法視覺化看出每種細胞的區別。
舉例來說,在論文的圖中,我們可以看到不同的人類細胞在經過類神經網路處理後,能夠有著最大化的分群效果;而且群與群之間大致上距離都相當遠,顯示出基因的表現量的確會隨著細胞的不同而不同。
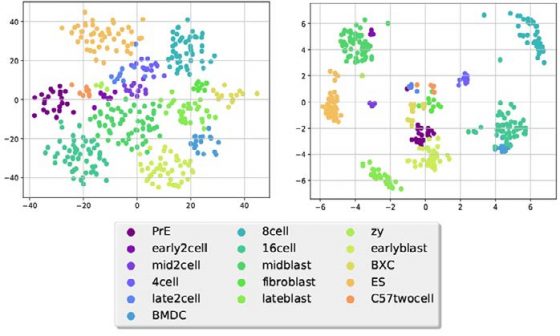
在同一項研究中,研究人員也發現如果小心地設計類神經網路架構,並將其與生物意義結合的話,將能達到最好的效果。這裡說的與生物意義結合的意思,指的是在設計的類神經網路層級中考慮到生物網路的數量以及結構。
他們首先算出這些基因表現量資料,並將資料建成 protein-protein interaction (PPI) 與 protein-DNA interaction (PDI) 的網路系統,並找出裡面總共有 348 個彼此之間有關聯的子網路;而就在找出「348」這個神奇數字後,研究人員就將類神經網路的隱藏層設計成兩層,且各有著 348 個神經元節點,分別代表這 348 組 PPI 與PDI 子網路。他們發現這樣子的類神經網路設計將能達到最理想的分群效果。
好的。到底我之所以鋪了類神經網路和生物意義這些梗要幹嘛呢?當然最主要的目的就是要說明 2018 年 Nature Methods的論文1 到底在講什麼。這篇論文雖然也是走類神經網路路線,但是他們網路的設計相當極端:完全按照生物的代謝途徑 (metabolic pathway) 來設計神經元的分佈(作者群在另一篇論文4 中提到他們就是受到這一篇 Nucleic AcidsResearch 的論文2 啟發而設計出這種奇妙的架構的)。
換句話說,這篇系統生物學的論文設計的類神經網路事實上已經不太有傳統的「隱藏層」的概念,而是完全按照代謝途徑連結人工神經元。透過這個方法,他們的類神經網路中總共包含了酵母菌的 2526 個子網路系統,分別代表不同的細胞代謝途徑。在經過訓練與比較後,這個經過特殊設計的網路結構可以準確地透過不同的基因表現預測酵母菌的細胞生長,並且預測的準確率比傳統數層緊密連結的類神經網路還要好上許多。
神秘的黑盒子,「類神經網路」是怎麼運作的?
在類神經網路的世界中,常常會聽到一個說法:以類神經網路為基礎架構的人工智慧預測模型是「黑盒子 (black box)」。這裡的黑盒子當然不是飛機出事後可以撿回來分析的那個,而是無法打開無法分析而且完全不曉得裡面到底在幹嘛的系統。為什麼會有這種說法呢?一切都要從類神經網路模型是如何訓練的開始講起。

在類神經網路的世界中,每一個神經元可以接收來自數十甚至數百個神經元的訊號,並且可以傳送訊號給數十到數百個其他神經元。這種連接方式讓類神經網路的參數異常地多,且輕易就可以上到百萬千萬甚至億這種等級。我再次拿 ALVINN,那台 1989 年的無人車來當例子好了。
ALVINN 的輸入層有 1216 個神經元節點,中間的隱藏層有 29 個神經元,而輸出層有 45個神經元。這個相對來說架構非常簡單的類神經網路的參數就有 1216 X 29 X 45 = 1586880 個參數要考慮了,更別提其他
更複雜的深度學習類神經網路模型了。
事實上,參數數量多還在其次,真正的關鍵在於類神經網路的訓練方式。在訓練類神經網路時,我們往往會做以下兩件事:
- 『 隨機』初始化類神經網路中的『所有』參數
- 隨著每個樣本的預測對錯微調所有的參數
我來用實際生活案例舉個例子好了。假設你要登一座山,目標是山頂。這座山每個地方的地型都完全不一樣。所以從 A 點上山和從不一樣的 B 點或 C 點上山的路都不盡相同。假設隨機把你放在這座山邊的某一點,要你朝著山頂為目標前進。這時候你的每一步就都會是在「那個當下」最佳的往山頂路線。所以從不同的點上山路線就有可能會差異極大,雖然最後都能到山頂就是了。
類神經網路的黑盒子,就是來自這個初始化與細微調整。因為參數太多,而且微調整的方式會隨著初始位置的不同而不同,所以一個調整好的類神經網路雖然可以達到不錯的預測成果,但是幾乎沒有人知道為什麼能夠達到這個預測效果。
- 題外話,這個議題已經受到機器學習以及人工智慧界的重視了。許多人都在想辦法解開這個「黑盒子之謎」5, 6, 7
再舉個例子。每個人的大腦會隨著發育環境的不同而有著不同的發展軌跡,所以幾乎沒有兩個人的大腦神經連結方式是完全相同的。雖然每個人都知道蘋果可以吃,或者是被打會痛;但是發展出這個知識的「神經元連結」則有可能每個人都不一樣。
參數設定越明確,越能解開「黑箱作業」!
回到主題。在前一段落提到的:完全按照代謝途徑建構的類神經網路,和其他網路系統不同的是,它有著「解開黑盒子」的效果呢。
這是因為這套「酵母菌的類神經網路預測模型」是完全按照「生物的代謝途徑」來連結的,所以雖然每個參數還是會因為類神經網路訓練過程而有所不同,但是我們可以得知某個神經元的總輸入參數值,也就是這個神經元的活化 (activation;中國翻成『激活』) 程度。只要將預測過程中每個神經元被活化的程度彼此比較,就能夠得知那個神經元扮演著最重要的角色;而這個神經元也就會是整個代謝途徑中最關鍵的基因或是調控因子。
下列 a、b 兩圖中皆可在這個類神經網路中,不同的基因活化後將會趨動不同的細胞反應,如 a 圖的 PMT1 與 IRE1 兩條基因與細胞壁的組成與強度有關,而 b 圖則可見 ERV7 與 RAD57 與DNA 的修復有著密切關聯性。
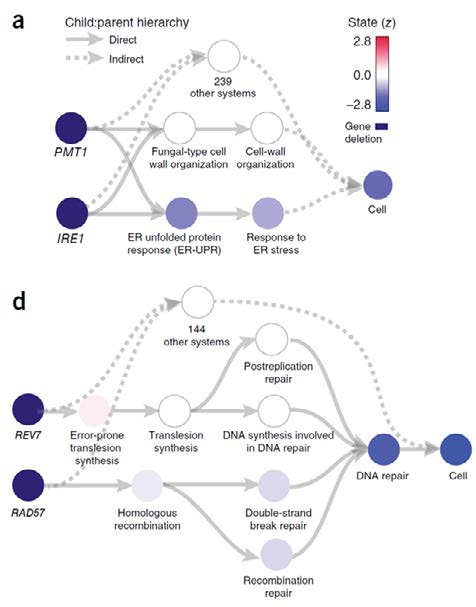
回到系統生物學,這套系統之所以對系統生物學的研究很有幫助的原因,在於它是一個可模擬生物在輸入各種訊號(如食物或環境刺激)後,將整個生物代謝途徑中最關鍵的基因標示出來的系統。礙於篇幅沒辦法將所有的元件講的非常清楚(比如說類神經網路本身就有一大堆參數要設定,然後訓練時也往往要扯到方程式微分模型之類的),只是很概略地將最大方向的概念用各種例子來說明。希望各位在讀完這個系列後能夠對何謂類神經網路有著最基本的認知,也能大致理解為什麼類神經網路會被詬病為「黑盒子」的原因。
參考文獻
- Ma et al., “Using deep learning to model the hierarchical structure and function of a cell”, Nature Methods, 15:290–298, 2018.
- Pomerleau D., “ALVINN: an autonomous land vehicle in a neural network”, Advances in Neural Information Processing Systems 1, pp. 305-313, 1989.
- Lin et al., “Using neural networks for reducing the dimensions of single-cell RNA-Seq data”, Nucleic Acids Research, 45(17):e156, 2017.
- Yu et al., “Visible Machine Learning for Biomedicine”, Cell, 173(7):1562-1565, 2018.
- Knight W., “The Dark Secret at the Heart of AI”, MIT Technology Review,2017.
- Wisdom D., “Deciphering The Black Box of AI”, Medium, 2018.
- Castelvecchi D., “Can we open the black box of AI?”, Nature 538:20-23, 2016.

- 本文轉載自MiTalkzine,原文《類神經網路、人工智慧與微生物》
- 歡迎訂閱微雜誌MiTalkzine,加入 MiTalker 的行列,一起來認識這個星球上千萬種各式各樣的微生物吧!



































