- 施朝仁/財團法人食品工業發展研究所/生物資源保存及研究中心研究員
「我是誰?」微生物百百款,要如何鑑定?
對所有微生物研究的從業人員而言,無論是在學界、業界抑或是醫界,精確的微生物身份判定或鑑定,一直都是最重要的事情。
在學界,正確的菌種鑑定關係著研究生能不能順利畢業、教授的論文能不能發表;在業界,微生物產品中菌的正確性則關係著普羅大眾的健康與權益;在醫界,精確的菌種鑑別,更是影響醫生能否正確下藥,是攸關生死的重大任務。
傳統微生物的鑑定方法建立於形態觀察及生理生化反應的基礎上。
形態觀察不外乎菌長的圓還是扁?長還是短?有無鞭毛?會不會產生內孢子?革蘭氏染色是紅還是藍?菌落形態是濕潤隆起或是乾扁皺縮等等。生理反應要看菌的厭氧性、生長溫度、生長酸鹼值、耐鹽程度等。生化反應則是看對碳源的利用、碳水化合物的氧化或發酵、酵素反應等等。然而,這些檢測所謂的表現型特性 (phenotype) 的觀察或試驗,往往費時且耗工,甚至不一定精確。
時代在走,進步要有:微生物鑑定儀歷代演進
因應著科研人員對 「快速」、「可靠」 的渴望與需求,微生物鑑定平台也跟著快速演進中,更快、更準的套組與儀器不斷地推陳出新。以生化反應偵測為例,Biomerieux 公司在 1970 年代推出 的 API ® 鑑定產品堪稱全球最早開發的手工微生物鑑定系統。
這套系統將繁複的零散生化試劑融合成套裝式組合,曾被視為微生物領域中的黃金標準鑑定法,被廣泛運用在各領域當中,整個系統大約涵蓋 600 多種菌株,所需的鑑定時間只要 18-72 小時 。
然而,他畢竟還是 『手工套組』,操作時的試劑添加、結果判讀都還是得自己來。

於是另有廠商推出了半自動的鑑定系統,如 BiOLOG 公司推出的 MicroStation 微生物菌種鑑定系統 ,只要手動添加菌液到 96 孔樣本盤,反應結果就交由機器判讀、比對。這套系統可鑑定的菌株範圍更廣,多達 2500 種。

有了半自動系統後,當然就會有廠商研發全自動系統,Biomerieux 公司繼 API ® 系統後,再接再厲推出全自動微生物分析系統 Vitek 2 Compact,強調只要備妥菌液,機器就可以自動將菌液吸入測試卡內,在含有不同試劑的小反應槽裡進行反應,腸內桿菌最快 2-6 小時即可判定身份。

上述這些鑑定方式,都是根據微生物的表現型來進行判定,然而隨著分子生物技術的快速進步,基於微生物基因型的分類方法發展得如火如荼。不管是利用細菌的 16S RNA 基因序列,或是真菌的 18S RNA 基因序列,只要能取得目標微生物的 DNA,經過簡單的聚合酶連鎖反應 (PCR) 及定序反應就能獲得菌種的 DNA 序列。
也因此,線上基因序列資料庫的資料正以每日數以萬計的數量快速累積中。根據這些序列,生物資訊專家可快速的將各個微生物樣品進行比對分類,甚至畫出他們的系統演化樹圖。微生物學家只要將手上未知菌種的 16S 或18S rRNA 基因的序列與資料庫進行比對,很快地就能得到最接近的菌名,而且多數菌種的身份判定能精確到連同種不同品系都鑑定得出來。於是,現在的微生物從業人員,遇到未知菌株,第一個反應就是定序。至此,微生物鑑定平台正式進入了基因型的時代。
別再蝦等了,2小時內菌種鑑定迅速搞定
而隨著定序繼續的突飛猛進,尤其次世代定序儀的發展,更將微生物鑑定帶入另一個境地:不用純菌也不用活菌就可了解全菌組成的宏觀基因體世代 (metagenomics)。
不過這不是此篇重點,表過就好。對微生物生態學家、醫院微生物檢驗人員或食品、藥廠環境監控人員而言,每天所面對的絕對不會是簡單、少數幾株菌的鑑定工作,往往一次就是數百甚至上千個未知菌落。即使你的老闆很有錢,可以很豪邁地把全部的未知菌落 (菌液) 通通送去做定序,但別忘了還要先一個一個抽 DNA、跑 PCR、跑電泳確認增幅片段等等的工作得先進行,就算實驗室裡有錢到可以將上述工作都以全自動設備代勞,「時間」仍是無法避免的成本。
解決的方法就是基質輔助雷射脫附游離飛行時間式質譜儀,以下簡稱 MALDI-TOF MS ,這項技術近年已被廣泛應用在微生物鑑定與研究上。此儀器的原理為:
將樣品與基質 (通常為有機酸) 混合,以鐳射光激發樣品,讓樣品氣化游離後,飛行至偵測器,系統再將樣品中所有蛋白質、胜肽、代謝物等依質量大小以圖譜呈現。
這就像是要分析一個班級(細胞)的學生體重(全細胞蛋白質)組成,讓學生穿上感應槍聲會強迫起跑的特定衣物(基質),並排站於起跑線(樣本盤),鳴槍(雷射激發)後起跑。學生裡體重輕的跑得快,體重重的跑得慢,裁判在終點線依抵達順序將學生排序,排列於司令台(圖譜),則可得到該班級學生體重組成(蛋白質指紋圖譜)。
MALDI-TOF MS 解析微生物的全細胞蛋白質分子量大小範圍在 2000-20000 Da 之間,此區間的蛋白質以核醣體蛋白等胞內負責持家的蛋白質為主4。核糖體蛋白在不同菌種都需要用到且需求量相當,所以不易受到外在培養條件影響,故質譜訊號有良好重複性與再現性,可作為菌種鑑別之依據。MALDI-TOF MS 設備的製造商已與德國菌種中心合作,將已知菌株的蛋白質指紋圖譜建立資料庫,利用相同物種指紋圖譜一致的特性,將未知樣本圖譜與已知圖譜比對,則可快速完成微生物身分鑑定。
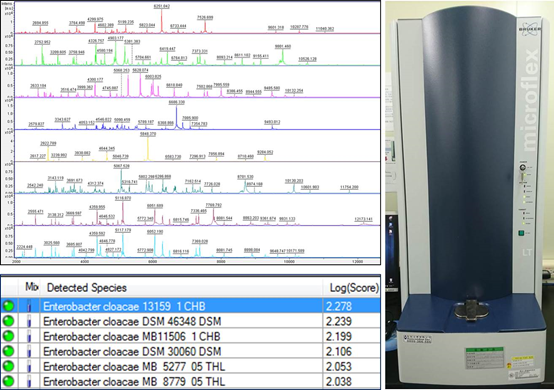
對於一般微生物而言,其解析度已能達到 「種」 層次的鑑別,甚至是近緣物種之區分,因而被認為具有取代細菌 16S rRNA 基因定序比對之潛力1,2,3。MALDI-TOF MS 技術比對菌株細胞裡的多種蛋白質,而 16S/18S rRNA 基因的比對只用一個基因為代表。想像要區分兩個班級的特色差異,分析全班同學的體重組成,似乎比只抓班長出來比較身高體重來的宏觀一些。
利用 MALDI-TOF MS 進行微生物分類鑑別最大優勢在於時間成本的降低。只要將欲分析的菌落直接塗抹於樣本盤,覆以特定基質即可,而且每個樣品盤可同時處理 96 個樣品,上機後 2 小時內即可完成所有分析。每一個樣品點所需使用的試劑耗材花費低於百元新台幣,相較於前述的手動微生物鑑定套組-API® 與半自動-BiOLOG 或全自動鑑定系統-Vitek 2,甚至是 16S rRNA 基因序列分析,在操作上更加簡便且成本更低,因此非常適用於短時間內進行大量樣品之快速分群鑑別分析。想做菌種鑑定,你不用再苦等生化反應與定序結果了,試試 MALDI-TOF MS吧!
參考文獻
- Dieckmann, R. Helmuth, R. Erhard, M. and Malorny, B. 2008. Rapid classification and identification of salmonellae at the species and subspecies levels by whole-cell matrix-assisted laser desorption ionization-time of flight mass spectrometry. Appl. Environ. Microbiol. 74:7767–7778.
- Ruiz-Moyano, S. Tao, N. Underwood, MA. and Mills, DA. 2012. Rapid discrimination of Bifidobacterium animalis subspecies by matrix-assisted laser desorption ionization-time of flight mass spectrometry. Food Microbiol. 30:432–437.
- Sedo, O. Vadurova, A. Tvrzova, L. and Zdrahal, Z. 2013. The influence of growth conditions on strain differentiation within the Lactobacillus acidophilus group using matrix-assisted laser desorption/ionization time-of- flight mass spectrometry profiling. Rapid Commun. Mass Spectrom. 27:2729–2736.
- Wieser, A, Schneider, L. and Jung, J. 2012. MALDI-TOF MS in microbiological diagnostics-identification of microorganisms and beyond (mini review). Appl. Microbiol. Biotechnol. 93:965–974.

本文轉載自MiTalkzine,原文《還在等菌種鑑定結果?試試 MALDI-TOF MS吧!》
歡迎訂閱微雜誌MiTalkzine,加入 MiTalker 的行列,一起來認識這個星球上千萬種各式各樣的微生物吧!