2020 年公民科學事件簿:#長新冠(#Long Covid)
通過患者主導的研究和患者主導的行動主義,
(Amali Lokugamage, 2020 而後被世衛總幹事引用1
時空回到 2020 年 5 月下旬,台灣的新冠疫情頭條新聞是國內新冠肺炎疫情趨緩,連續超過一個月沒有本土確診病例,然而全球確診數卻已衝破 500 萬大關 2
全球大部分國家在封城與疫情無法控制的脈絡下,原本防疫科學辭典裡沒有的名詞,在 2020 年春季歐美英語使用者的網路社群中漸漸流傳開來。由於網路社群媒體允許患者在封鎖與身體狀態不佳的限制下,在網路社群中相互尋找和資訊交流,產生共鳴與共識進而發展出一個共通術語,也就是我們現在熟知的「長新冠(Long COVID)」或國內較不熟悉的另一個相似詞「長途運輸者(Long-hauler)/長途運輸的新冠 (long-haul COVID) 3
我們現在知道的「長新冠」已不是網路世界中的虛擬事件,而是科學家和國際組織認定的「科學物件 (scientific object)」。世界衛生組織正式定義:新冠後症狀(Post COVID-19 condition ),簡稱長新冠(Long COVID) 是指在初次感染新冠病毒三個月後繼續或出現新症狀,症狀持續至少兩個月,無法用其他診斷來解釋的病症 4 5
“有趣的是「長新冠」一詞是由倫敦大學考古學家艾爾莎・佩雷戈(Elsa Perego)在推特上推廣來自患者創造的術語而興起的。”
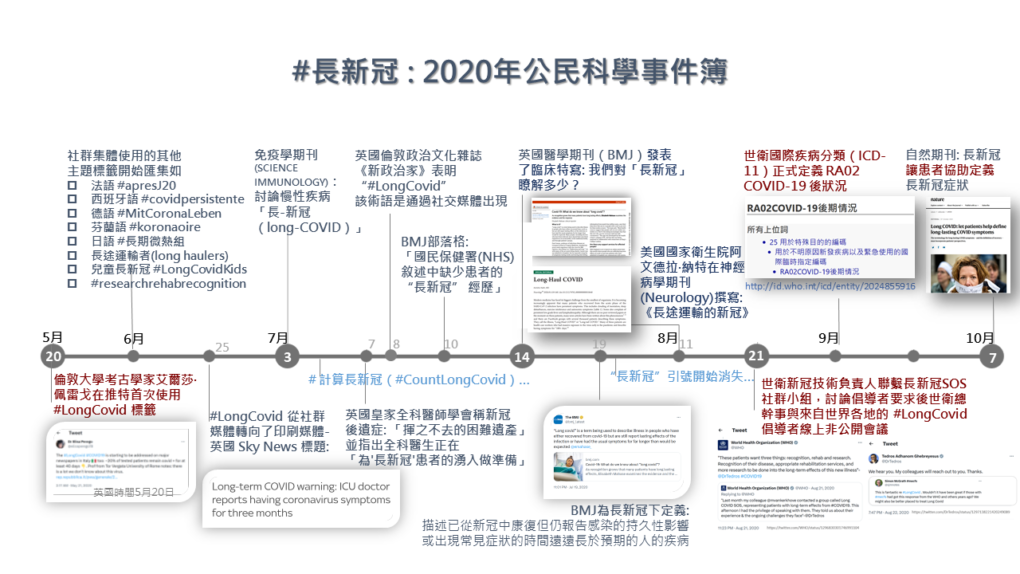
圖一:網路社群廣用的主題標籤來描述或分享長新冠資訊。圖/作者提供
這個來自 2020 年春天「患者創造的術語」, 2021 年 10 月 6 日世衛公布長新冠的正式定義,雖然使用的是「新冠後症狀(post COVID-19 condition)」,但長新冠仍是最通用的術語。在今年(2023)的 7 月 31 日美國衛生與公眾服務部(Health and Human Service, HHS)宣布正式成立「長新冠研究與實務辦公室 (the Office of Long COVID Research and Practice)」 ,同時也啟動了長新冠的臨床試驗 6 「公民科學(citizen science)」 7
那麼我們不禁好奇,這一切是如何開始的?
現在若按照世衛的「長新冠」定義,感染三個月後持續二個月症狀合計至少五個月的病程,那麼文獻上 2020 年 5 月這個時間點,反應了歐美國家初期大規模感染後,累積一定數量患者在確診後「理論上康復」但卻持續有各種症狀困擾的情形。當時各國的衛生當局和醫療機構尚未認識到新冠感染造成長期後遺症的可能性,而世衛最初資訊亦表示新冠輕症感染者的病程平均持續兩周。
佩雷戈在 2020 年 5 月 20 日(英國時間)是目前文獻上記載最早的長新冠推文,後續網路社群媒體陸續出現如圖一 所標示與長新冠有關的主題標籤。佩雷戈與其他科學家 2020 年 9 月發表了一封公開信,標題是「為什麼我們需要患者所提出的『長新冠』術語」,說明長新冠一詞強調了當時輕症卻持續超過二周以上的多種後遺症,這個術語有助於認識新冠發病機制本身具有特異性,而術語本身的簡單性和力量則有助於在全球範圍內爭取公平認可,並確保公眾在接觸新冠風險時,瞭解感染的潛在長期影響 8
圖二:2020 年自 5 月起長新冠公民科學形成的過程。圖/作者提供
圖二 摘要描述 2020 年自 5 月起長新冠公民科學形成的過程,主要依據佩雷戈與英國格拉斯哥大學人文地理學教授菲麗西蒂・卡拉德(Felicity Callard)、英國劍橋、牛津等大學研究學者梅洛迪・特納(Melody Turner)等人記錄這場 2020 年公民科學發展過程的三篇論文 9 , 10 , 11
以 2020 年自 5 月的第一條推文,推特社群與其他網路媒體(如臉書、 Slack 和 WhatsApp 社群)快速構建,並在此過程中引入了長新冠作為一種社會條件,導致在短短的三個月內被世衛確認長新冠為一種醫療狀況:世衛國際疾病分類(International Classification of Diseases 11th Revision, ICD-11)正式定義長新冠為新冠後症狀,圖二 最後以《自然》期刊編輯於該年 10 月發表的公開呼籲做結:「長新冠:讓患者協助定義長新冠症狀」 副標題:長新冠症狀的術語以及康復的定義必須納入患者的觀點。
「從一條相當不起眼的推文(引入了一個新的主題標籤,最初只被『點讚』一次),在短短三個月內轉變為世衛使用的詞」佩雷戈回憶說明, #longcovid 的使用呈指數級增長。一週內從社群媒體轉向印刷媒體,短短一個月醫學期刊從討論、呼籲、科學家開始下定義、到「長新冠」的引號在主流媒體與科學期刊內容消失,直接使用長新冠一詞,三個月後 2020 年 8 月 21 日在世衛新冠技術負責人瑪麗亞・范克爾霍夫 (Maria Van Kerkhove)聯繫英國的長新冠 SOS 組織(LongCovidSOS)了解宣導者要求後,世衛組織總幹事在線上會議與長新冠宣導者討論這一個疾病。
患者症狀故事:新冠不只影響肺部
佩雷戈與卡拉德指出,長新冠患者在網路社群的公民運動中通過與其他經歷長期後遺症患者集體分享而出現,提供了後來科學的新知,其貢獻包括:口頭、書面、視覺敘述、證詞和論點以及宣傳和政策干預,對傳統科學提出了挑戰,例如在大流行初期的新冠公眾資訊傳遞過程中僅限對肺部影響的討論,長新冠網路社群則協助擴大範圍。
2020 年 4 月一篇廣為流傳的推文,而後經由報紙專欄強調這位患者的後遺症「純粹是胃部症狀」而不是肺部系統,其他患者的多重器官後遺症則陸續在各種平台上,各自分享自身的醫學檢查,要求醫療單位進行更深入調查並向傳統研究團體致電等。現在這些「症狀故事」已在許多科學期刊的出版物中得到驗證,換言之,這些患者不僅提供了早期複雜的症狀,更有助於修正新冠損害的範圍,強調了需要關注所有潛在的面相,並提供有關疾病的機制和治療方法的假設。
新冠不只影響肺部,有位患者的後遺症純粹是胃部症狀。pexels
特納等人 2023 年發表的研究,在論文中提到是特納本人經歷長新冠症狀後與其他研究人員著手展開的。她反思自己的經歷如何影響她的研究,並質疑患者如何以及為何能在各種醫療機構前識別出長新冠,進而質疑傳統實證醫學的過程。他們蒐集整理 3 萬多筆帶有 #longcovid 和 #longhauler 標籤推文,進一步語意分析 974 條推文內容中的關鍵字後歸納指出:推特使用者最初將長新冠描述為一種無情、多器官、致殘的疾病,卻也因當時公眾和醫療機構缺乏認知,這些推特使用者面臨著恥辱和歧視的不公平待遇。但這些長新冠的早期推特使用者,後來被研究記錄為長新冠最初經歷的科學實證者,藉由此次的集體社會運動 (collective social movement)對長新冠患者的醫療保健需求建立共識。
同時另一個推特標籤 #researchrehabrecognition (#研究康復認知)也引起了世衛總幹事譚德賽的注意,最後承認長新冠問題並力促解決,特納等人解釋,長新冠患者賦予疾病經歷的含義在很大程度上被理解為有價值的知識形式,可以更全面地認識和治療病情及其影響,這些公民知識通過塑造臨床醫生與患者討論診斷的方式來直接影響臨床實踐,提高了就治療方案和任何建議的生活方式改變達成共識的能力。
長新冠公民運動:衛生服務部門的具體回應
佩雷戈與卡拉德提到的另一個網路社群運動也使得英國政府不得不採取具體行動。 2020 年 7 月,患有長新冠的英國南安普敦大學公共衛生教授尼斯林・阿爾萬(Nisreen Alwan)發起了社群媒體活動「#計算長新冠(#CountLongCovid)」,強調迫切需要正確的康復病例定義、收集數據的標準化方法以及大量基於人群的樣本資料,呼籲政府全面收集監測長新冠。
9 月,網友結合「六個月前」脈絡在推特上集合紛紛留下個人長新冠前後的對比故事。現在我們可藉由應用程式 Thread Reader App 將此推文串合併,一窺當時網路社群如何串連長新冠的個人經歷 12 13
另外針對兒童和青少年的長新冠症狀, 2020 年的 #兒童長新冠(#LongCovidKids)運動亦促成了英國國會跨黨派國會新冠小組(All-Party Parliamentary Group on Coronavirus in the UK)在 2021 年 1 月舉行的兒童長新冠公聽會,今(2023)年 2 月 16 日世衛也公布了兒童和青少年版長新冠的正式定義 14
特納等人綜合歸納 #longcovid 推文標籤的六個主題:
個人長期恢復
看不見的疾病,例如考慮最初對長新冠缺乏認識可能是一種孤立和無形的體驗
意外族群,如參與者對觀察結果表示驚訝和擔憂,許多長新冠患者很年輕而且以前「身體健康」
通過量化進行驗證,如對疫情統計資料和醫療系統有限投入的憂慮,強調最初兩週的定義的不足,要求通過監測計算患者發病率來了解病情
支持和研究的需要,如推特使用者擔心由於知識的缺乏,醫療機構可能無法充分提供醫療保健服務或投資長新冠的研究,因此使用 #researchrehabrecognition,最後獲得世衛的重視
衛生服務部門的認可
如推文中參與者評論醫療機構如何逐漸意識到長新冠與受到官方醫療保健的認同,如當時的美國首席醫療顧問安東尼・福奇以及世衛譚德塞,從而創造了衛生服務部門的具體行動以及為社會和科學新的認識契機。
網路社群媒體的開放性 網路社群在 2020 年經歷了所謂的醫療煤氣燈(medical gaslighting)效應,當他們處於科學對長新冠不確定性的大環境時,經常覺得被敷衍或誤診,就像是 1944 年經典電影《煤氣燈下》(Gaslight)明明房間裡煤氣燈忽明忽暗,但影片中的老公卻堅持一切正常,這些求助無門的人們,經歷許多令人沮喪的醫療保健挫折,藉由網路群眾的長新冠公民運動,將確診後揮之不去的各種後遺症和醫療狀況與具有相同經歷的人們聯繫起來,以尋求資訊、支持和認可,最終獲得了疾病的驗證和社會的支援 15
當他們處於科學對長新冠不確定性的大環境時,經常覺得被敷衍或誤診。pexels
特納等人分析推特如何促進集體社會運動的形成社會共識,通過社群媒體的公開和開放的系統,推特的社交網絡使得以前互不相干的使用者能夠分享這些情緒、資訊與交換知識,從普通公民、醫生、科學家到世衛總幹事等知名人士。推特與其他社交網站(如臉書和 Slack )使用方法不同,後者的長新冠社群多是封閉群組,限制公開分享;推特則在長新冠的推文中具有「去中心化」的特性:如沒有單一的意見領袖、使用者間訊息自由流動等。
例如推特使用者廣泛分享了 #research 、 #rehabilitation 和 #recognition 等單獨術語。 最終,使用者將這三個術語合併成 #researchrehabrecognition ,此標籤的演變展示了集體決策的過程,旨在挑戰長新冠患者由最初缺乏醫療認可和醫療保健規定而面臨的公民知識需求和認可狀態。
長新冠患者的知識因民眾直接地發起參與研究自己或社區、社群的環境和健康危害,提高學界醫界對新冠的新認識,知識從患者通過媒體傳播到正規的臨床和衛生政策管道,就像特納等人的分析,長新冠從一種看不見的疾病轉變為一種公認的疾病。
這些網路社群推文積極的行動,達成的集體共識足以令人信服地向包括世衛在內的醫療機構證明,儘管缺乏傳統的實證醫學,但長新冠是一種真實的疾病。一群網路公民在 2020 年集體編寫了第一本關於長新冠的教科書,此刻我們見證了網路社群的群眾力量,不僅促成了現實世界的真實變化,確保對醫療保健供應的認可,也揭開了科學研究的新序幕。
參考資料