


編按:本文係林澤民老師在2016年中進行的相關系列演講之一的逐字稿修訂版,本場次為2016/6/6在政大社科院的演講,題目為《看電影學統計:p 值的陷阱》。原文刊於《社會科學論叢》2016年10月第十卷第二期。
院長、陳老師,各位老師、各位同學,今天很榮幸能夠到政大來,和大家分享一個十分重要的課題。我今年回來,今天是第六個演講,六月中之前還有兩個,一共八個,其中四個是談賽局理論,四個是談 p 值的問題。
賽局理論的部分,題目都不一樣,譬如我在政大公行系講賽局理論在公行方面的應用,而我第一個演講在台大地理系,談賽局理論在電影裏的應用。我在台大總共講了三部電影,一部是《史密斯任務》,講男女關係、夫妻關係;第二部是《少年 pi 的奇幻漂流》,講少年和老虎對峙的重覆性賽局;第三部電影是最新的電影:《刺客聶隱娘》,講國際關係賽局。
今天談的當然是不一樣的題目,雖然它是一個很重要、很嚴肅的題目,但我希望大家可以輕鬆一點,所以也要放兩部電影片段給大家看,一部是《玉蘭花》,另一部則是《班傑明的奇幻旅程》,這兩部電影都有助於我們來瞭解今天要談論的主題:p 值的陷阱。

科學的統計學危機:p 值有什麼問題?
為什麼要談論 p 值的問題?因為在近十多年來,不只是政治學界,而是很多學門,特別是在科學領域,有很多文章討論傳統統計檢定方法、尤其是 p 值統計檢定的問題,甚至有位很有名的統計學者,Andrew Gelman 寫了篇文章,叫作〈科學的統計學危機〉(The Statistical Crisis in Science),說是危機一點都不言過其實。這就是為何我說:今天要討論的其實是很嚴肅的問題。
投影片上這些論點,大部分是說我們在傳統統計檢定的執行上,對 p 值有各種誤解跟誤用。現在很多人談到「p 值的危險」、「p 值的陷阱」、「p 值的誤用」、還有「p 值的誤解」。甚至有些學術期刊,也開始改變他們的編輯政策。像這本叫作 Basic and Applied Social Psychology 的心理學期刊,已經決定以後文章都不能使用 p 值,大家能夠想像嗎?我們作計量研究,都是用 p 值,各位一直用,在學界用了將近一百年,現在卻說不能用。甚至有些文章,說從前根據 p 值檢定做出來的研究成果都是錯的,有人更宣告 p 值已經死了。
所以這是一個很嚴重的問題。在這本期刊做出此決定後,美國統計學會(ASA)有一個回應,表示對於 p 值的問題,其實也沒這麼嚴重,大部分是誤解跟誤用所造成,只要避免誤解與誤用就好。可是在今年,ASA 真的就發表了正式聲明,聲明裡面提出幾點,也是我今天要討論的主要內容,包括 p 值的真正的意義,以及大家如何誤用,換句話說就是:p 值到底是什麼?它又不是什麼?(圖一) 今天除了會深入探討這些議題之外,也請特別注意聲明的第三點提到:科學的結論,還有在商業上、政策上的決策,不應只靠 p 值來決定。大家就應該了解這問題影響有多大、多嚴重!

我舉個例子,在台灣大家都知道我們中研院翁院長涉入了浩鼎案,浩鼎案之所以出問題,就是因為解盲以後,發現實驗的結果不顯著。我今天不想評論浩鼎案,但就我的了解,食藥署、或者美國的 FDA,他們在批准一項新藥時,一定要看實驗的結果,而且實驗結果必須在統計上要顯著。可是 ASA 卻告訴我們說,決策不該只根據統計的顯著性,大家就可想像這影響會有多大。甚至有其他這裡沒有列出來的文章,提到為何我們使用的各種藥物,都是經過這麼嚴格的 p 值檢定出來、具有顯著性,可是在真正臨床上,卻不見得很有用。其實很多對 p 值的質疑,都是從這裡出來的。
有關 p 值的討論,其實並非由政治學門,而是從生命科學、例如醫學等領域所產生的。ASA 聲明的第四點說:正確的統計推論,必須要「full reporting and transparency」,這是什麼意思呢?這是說:不但要報告 p 值顯著的研究結果,也要報告 p 值不顯著的研究結果。
但傳統方法最大的問題是:研究結果不顯著,通通都沒有報告。在英文有個詞叫 ,摘櫻桃。什麼叫摘櫻桃?摘水果,水果熟的才摘,把熟的水果送到水果攤上,大家在水果攤上看到的水果,都是漂亮的水果,其實有很多糟糕的水果都不見了。我們在統計上也是,大家看到的都是顯著的結果,不顯著的結果沒有人看到。

可是在過程中,研究者因為結果必須顯著,期刊才會刊登、新藥才會被批准,所以盡量想要擠出顯著的結果,這之中會出現一個很重大的問題:如果我們作了 20 個研究,這 20 個研究裡面,虛無假設都是對的,單獨的研究結果應該是不顯著。可是當我們作了 20 個統計檢定時,最少有一個結果顯著的或然率其實很高。雖然犯第一類型錯誤的或然率都控制在 0.05,可是 20 個裡面最少有一個顯著的,或然率就不是 0.05,大概是 0.64。如果就報告這個顯著結果,這就是 cherry-picking。
ASA 給的建議是:實驗者必須要 full reporting and transparency,就是一個研究假如作了 20 個模型的檢定,最好 20 個模型通通報告,不能只報告顯著的模型。ASA 這個聲明是今天要討論的主要內容。
p 值是什麼?
p 值是什麼?我想在座有很多專家比我都懂,但是也有一些同學在場,所以還是稍微解釋一下。p 值是由 Ronald Fisher 在 1920 年代發展出來的,已將近一百年。p 值檢定最開始,是檢定在一個 model 之下,實驗出來的 data 跟 model 到底吻合不吻合。這個被檢定的 model,我們把它叫做虛無假設(null hypothesis),一般情況下,這個被檢定的 model,是假設實驗並無系統性效應的,即效應是零,或是隨機狀態。在這個虛無假設之下,得到一個統計值,然後要算獲得這麼大(或這麼小)的統計值的機率有多少,這個或機率就是 p 值。
舉一個例子,比如說研究 ESP (超感官知覺)時會用到比例(proportion)這個統計值。我們用大寫的 P 來代表比例,不要跟小寫的「p 值」的 p 混淆。在 p 值的爭論裡,有一篇研究 ESP 的心理學文章被批評得很厲害。文章中提到了一個實驗,讓各種圖片隨機出現在螢幕的左邊或者右邊,然後讓受測者來猜圖片會出現在哪邊。我們知道如果受測者的猜測也是隨機的,也就是沒有 ESP 的效應,則猜對的或然率應該是一半一半,算比例應該是差不多 P = 0.5,這裡比例 P = 0.5 就是我們的虛無假設。但這個實驗,實驗者是一位知名心理學教授,他讓受測者用各種意志集中、力量集中的辦法,仔細地猜會出現在左邊還是右邊。結果發現,對於某種類型的圖片——不是所有圖片,而是對於某些類型的圖片,特別是色情圖片——受測者猜對的比例,高達 53.1 %,而且在統計上是顯著的。所以結論就是:有 ESP,有超感官知覺。

這裡 p 值可以這樣算:就是先做一個比例 P 的 sampling distribution(抽樣分配)。如果虛無假設是對的,平均來講,P = 0.5。0.5 就是 P 的抽樣分配中間這一點,這個比例就是我們的虛無假設。在受測者隨機猜測的情況之下,P 應該大約是 0.5 的。可是假如真正得到的 P 是 0.531,抽樣分配告訴我們:如果虛無假設是對的,亦即如果沒有任何超自然的力量,沒有 ESP 存在,大家只是這樣隨機猜測的話,則猜對的比例大於或者等於 0.531 的機率,可以由抽樣分配右尾的這個面積來算。作單尾檢定,這面積就是所謂的 p 值。如果作雙尾檢定的話,這值還要乘以 2。以上就是我們傳統講的 p 值的概念。
我們得到 p 值以後,要作統計檢定。我們相約成俗地設定一個顯著水準,叫做 α,α 通常都是 0.05,有時候大家會嚴格一點用 0.01,比較不嚴格則用 0.10。如果我們的 α = 0.05,則若 p < 0.05,我們就可以拒絕虛無假設,並宣稱這個檢定在統計上是顯著的,否則檢定就不顯著,這是傳統的 p 值檢定方法。如果統計上顯著的話,我們就認為得到實驗結果的機會很小,所以就不接受虛無假設。
為什麼說 p 值很小,就不接受虛無假設?我個人的猜想,這是依據命題邏輯中,以否定後件來否定前件的推論,拉丁文稱作 modus tollens,意思是以否定來否定的方法,也就是從「若 P 則 Q」和「非 Q」導出「非 P」的推論,這相信大家都知道。p 值檢定的邏輯是一種有或然性的 modus tollens,是 probabilistic modus tollens。「若 H0 為真,則 p 值檢定顯著的機率很小,只有 0.05」,現在 p 值檢定顯著了,所以我們否定 H0。但是命題邏輯的 modus tollens,「若 P 則 Q」是沒有或然性、沒有任何誤差的餘地的。「若 H0 為真,則 p 值檢定不可能顯著」,這樣 p 值檢定顯著時,你可以否定 H0,大家對此都不會有爭議。
問題是假如容許或然性,這樣的推論方法還是對的嗎?舉一個例子:「若大樂透的開獎機制是完全隨機的,則每注中頭獎的機率很小,只有 1 / 13,980,000」,現在你中獎了,你能推論說大樂透開獎的機制不是隨機的嗎?p 值的問題,便是在於我們能不能夠因為 p 值很小,小到可能性很低,我們就用否定後件的方法來否定前件。我們用命題邏輯來作統計推論,但其實我們的推論方法跟命題邏輯卻不完全一樣,因為我們的 α 絕對不可能是零,如果 α 是零的話,就不是統計了。
再來就是看電影時間,電影很有趣,可以幫助我們了解什麼是 p 值,也可以再接著討論為什麼用 p 值來作統計推論會有錯。這部電影叫做「玉蘭花」,是 1999 年的電影,已經很舊了,可能在座年輕的朋友就沒看過。網路上在 Youtube有這一段,請大家觀賞。
相信大家應該都看得懂這短片的用意。玉蘭花這部電影,雖然裡面有講一些髒話,但是其實是一部傳教的影片。它的推論方式,其實就是我剛剛講的 p 值的推論方式,它有一個虛無假設,就是說事情發生沒有什麼超自然的力量在作用,都是隨機發生的,是 by chance,不是 by design,可是它發生了,竟然有這麼巧合的事情。大家可以想一下,如果事情的發生都是 by chance,都是隨機的,那麼像這種事件發生的機率有多少?很小很小,0.0…01,幾乎不可能發生。所以假如是隨機發生的,就幾乎不可能發生,可是它發生了,我們就以否定後件來否定前件,推論虛無假設-by chance 的這個假設-是不對的。
既然不是 by chance,它是什麼?就是 by design,是設計出來的。這是基督教的一種論證上帝創造世界的方法。在美國,有些學區還在爭論,生物是創造的還是進化的?創造論的主張者都會用這樣的論證,說你看我們人體,它是這麼複雜的一個系統,這種系統可能是隨機發生的嗎?若是隨機發生,機率有多少?是 0.0…01,所以它不可能是隨機發生,因此是創造的。這個理論叫做 intelligent design(智慧的設計)即我們這個世界都是上帝創造、是上帝很有智慧地依照藍圖設計出來的。我今天也不想爭辯這種推論對不對,我只是舉例來說明這種推論的邏輯。
p 值不是什麼?
我本來放這部電影都是為了在教學上解釋 p 值的概念,可是後來當我注意到對於 p 值的爭議之後,覺得其實這一部電影也可以用來幫我們了解為什麼用 p 值來做統計推論有可能是錯的。
下面這個表是大家都熟悉的。(圖二) 我們可以用這個表來呈現有關虛無假設是對或者不對,是被拒絕或者被接受的四種可能性,其中兩種是作出錯誤統計推論的情況。第一個情況,虛無假設是對的,但統計檢定是顯著的,因此虛無假設被推翻了。這種情況叫做 Type I error,我們保留了 α = 0.05 的機率容許它存在。第二個情況,如果虛無假設是錯誤的,但統計檢定不顯著,所以它沒有被推翻,這個情況叫做 Type II error。Type II error 剛學統計的同學可能不太了解,因為我們通常都不會很清楚地去計算它的機率——所謂 β。這個 β 跟 α 不一樣,不是你可以用相約成俗的方法來訂定,而是會受到若干因素的影響。

我們可以開始討論:傳統用 p 值來作統計檢定方式,為什麼有問題?剛剛 ASA 的聲明說:p 值 do not measure the probability that the studied hypothesis is true。p 值告訴你:如果虛無假設是對的,你「觀察到資料」的機率有多少,但它並沒有告訴你「虛無假設是對的」的機率有多少,或「研究假設是對的」的機率有多少。這是很不一樣的:前者是 data 的機率,後者是 model 的機率。進一步說明,p 值是在虛無假設為真的條件之下,你觀察到和你所觀察到的統計值一般大小(或更大/更小)的機率。但我們作檢定的時候,我們是看 p 值是不是小於你的統計水準 α,如果 p < α,我們就說統計是顯著的。
換句話說,如果虛無假設為真,那麼你的檢定是顯著的機率是 α = 0.05。但這其實不是我們作研究最想回答的問題;這個機率只告訴我們,如果你的虛無假設為真,有百分之五的機率,data 會跟它不合,但它沒有告訴我們虛無假設這個 model 為真的機率有多少,而這才是我們應該問的問題。所以我們應該反過來問,如果你統計檢定是顯著的,在此條件之下,「虛無假設是對的」的機率有多少?如果我們把關於 data 這個偽陽性的機率記作 α = Pr(Test=+|H0),大家可以看出這個關於 model 的機率其實是它倒反過來的:Pr(H0| Test=+),所以我把它稱作「偽陽性的反機率」。這兩個機率原則上不會相等;只有在 α = 0 的時候,兩者才都是零而相等。
譬如今天你去健康檢查,醫生給你做很多篩檢,如果篩檢結果是陽性,其實先不要怕,因為你應該要問,如果篩檢出來是陽性,那麼你真正並沒有病的機率是多少?也就是偽陽性的反機率有多少?大家可能會很驚訝,偽陽性的反機率通常都很高,但是這個機率,p 值並沒有告訴你。所以必須要去算在檢定是陽性的條件下,結果是一種偽陽性的反機率;這就必須要用「貝式定理」來算。

雖然在座有很多可能比我更高明的貝氏統計學家,但我還是要說明一下貝式定理。先舉一個我終身難忘的例子,剛剛陳老師說我是台大電機系畢業的,我在電機系的時候修過機率這一門課。我記得當時的期中考,老師出了一個題目,說我口袋裡面有三個銅板,其中有一個銅板是有偏差的銅板,偏差的銅板它得到正面的機率是 1/3 ——不是 1/2——而得到反面的機率是 2/3。考題問:現在我隨機從口袋裡面掏出一個銅板,這個銅板是那個偏差銅板的機率是多少?很簡單大家不要想太多,1/3 嘛。可是我現在拿銅板丟了一下,出現的是正面,我再問你這個銅板是那個偏差銅板的機率是多少?我不期望大家立刻回答,因為要用貝式定理來算,當你獲得新的資訊的時候,新的資訊會更新原來的機率。這裡我也沒有時間詳細告訴大家怎麼算,但是可以告訴大家,結果是 1/4。
如果我丟擲銅板,它得到了正面,它是偏差銅板的機率變成只有 1/4。這是因為偏差銅板出現正面的機率,比正常銅板要小,所以出現正面的話,它相對來講就比較不太可能是偏差的銅板,所以機率會比原來的 1/3 小些,只有 1/4。(大家可以想像如果偏差銅板出現正面的機率是 0,而丟擲得到正面,則此銅板是偏差銅板的機率當然是 0。)原來所知的「1/3 的機率是偏差銅板、2/3 的機率是正常銅板」這個機率分配在貝氏定理中叫做先驗機率(prior probability)。大家要建立這個概念,即是還沒觀察到數據之前,對於模型的機率有一些估計,這些估計就叫做先驗機率。至於觀察到數據之後所更新的模型機率,1/4 和 3/4,這個機率分配叫做後驗機率(posterior probability),也就是前面所說的反機率(inverse probability)。

我們再來看另外一個跟統計檢定問題非常接近的例子。可以用剛剛身體檢查的例子,但我這裡用美國職棒大聯盟對球員的藥物檢查為例,也許比較有趣。這裡假設大約有 6 % 的美國 MLB 的球員使用 PED(performance enhancing drugs),這是一種可以增強體能表現的藥物,是類固醇之類的藥物。這個估計數字可能是真的,是我從網頁上抓下來的。這邊的 6 % 即為我前面說的先驗機率:隨機選出一個球員,則他有使用 PED 的機率是 0.06,沒有使用 PED 的機率是 0.94。現在大聯盟的球員都要經過藥檢;舉大家熟知的火箭人 Roger Clemens 為例。他也是我心目中的棒球英雄,他被檢定有陽性的反應。
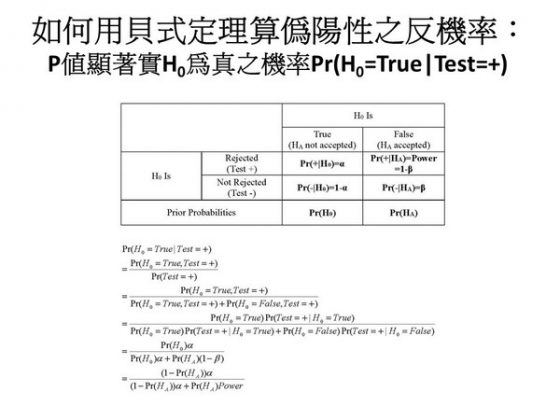
為了方便起見,假設藥檢的準確度是 95 %。所謂準確度 95 %的定義是:如果一個球員有使用藥物,他被檢定出來呈陽性反應的機率是 0.95;如果一個球員沒有使用藥物,他被檢定出來呈陰性反應的機率也是 0.95。也就是我假設兩種誤差類型的機率 α 跟 β 都是 0.05。在這假設之下,使用貝式定理來計算,當球員被篩檢得到的結果是陽性,但他並不是 PED 使用者的後驗機率或反機率,其實高達 0.45。大家可以從圖三看到貝氏定理如何可以算出這個機率。(圖三)

使用貝式定理算出來的結果大家應該會覺得很詫異,因為我們藥物篩檢的工具應該是很準確的,0.95 在我們想像中應該是很準確的,我們認為說我們錯誤的可能性只有 5 %,其實不然。檢定是陽性,但其實偽陽性的反機率可以高達45 %!所以雖然我不是醫學專家,不過大家健康檢查,如果醫生說,你的檢查結果呈現陽性反應,大家先不要慌張,你要先問一下醫生檢驗的準確度大概有多少,如果一個真正有這種病的人來檢定,呈現偽陽性的機率有多少?如果一個沒有病的人來檢定,呈現偽陰性的機率有多少,然後再問他先驗機率大概有多少?然後自己用貝氏定理去算一下偽陽性的反機率。醫學上很多疾病,在所有人口裡面,得病的比例通常很小的。也就是說,得病的先驗機率通常都很小,所以偽陽性的反機率會很大。
現在換成了統計檢定,看下圖的表格。(圖四)這表格跟圖三的表格很像,只是把內容改成了圖二的內容:虛無假設是真的、或是假的,然後統計檢定是顯著、或是不顯著的。然後再加上一行先驗機率,就是「虛無假設是對的」的先驗機率有多少、「虛無假設是錯的」的先驗機率有多少,都用符號來代替數目。我們可以用貝式理得到一個公式,顯示偽陽性的反機率是統計水準 α、檢定強度(power = 1 – β)、和研究假設之先驗機率(P(HA))的函數。α 跟檢定強度都沒問題,但公式裡頭用到先驗機率。你會問:在統計檢定裡面,先驗機率是什麼?
在此我必須要稍微說明一下,先驗機率,以淺白的話來講,跟你的理論有關係,怎麼說呢?如同剛剛提到 ESP 的實驗,好像只要就這樣用力去猜,你猜對的可能性就會比較高。發表這樣子的實驗報告,我們有沒有辦法告訴讀者,當受測者這樣皺著眉頭去想的時候,到底是什麼樣的一個因果機制,能夠去猜到圖片是出現在左邊還是右邊。
一般來說這種 ESP 的實驗,是沒有這種理論的,是在完全沒有理論的條件之下來做實驗。在此情況之下,我們可以說,此研究假設的先驗機率很小很小。當然我們作政治學的研究就不一樣,我們可能引用很多前人的著作,都有一個文獻回顧,我們也引用很多理論,然後我們說:我們的研究假設是很有可能展的。假如你有很好的理論,你的研究假設的先驗機率就會比較高,在這種情況之下,問題會比較小。但是還有一個問題,就是如果從文獻裡面來建立理論,來判定你的研究假設的先驗機率有多少,問題出在於:通常文獻回顧是從學術期刊裡面得來,而現在所有的學術期刊,發表的都是顯著的結果,不顯著的結果通通都沒有發表,從學術期刊上來判斷研究假設的先驗機率有多少,這樣的判斷是有偏差的。這是我今天要講的第二個問題,現在先繼續討論偽陽性反機率的問題。
現在要詳細討論影響偽陽性反機率的因素,就是影響到「統計檢定是顯著的條件之下,虛無假設為真」這一個機率的因素。這裡再重覆一下,我們一般了解的統計推論,奠基於虛無假設為真時,p 值顯著的機率,也就是偽陽性的機率被控制在 α 之內:Pr(Test=+|H0)= Pr(p<α|H0) = α。但我們現在要反過來問的是:統計檢定是顯著的情況下,H0 為真的機率,也就是偽陽性的反機率:Pr(H0| Test=+)= Pr(H0| p<α),這好比篩檢結果為陽性、但其實球員並未使用 PED、患者其實無病的機率。如果 α 等於零,可以很清楚的發現,這兩個機率是一樣的,都是零;但 α 不等於零的時候,它們就不一樣。由下圖來看,偽陽性的反機率跟先驗機率-研究假設的先驗機率-以及檢驗的強度有關。(圖五、六)看圖可以得知,power 越大,還有先驗機率越大的話,偽陽性的反機率就越小。可是當 power 越小的時候,還有先驗機率越小的時候,偽陽性的反機率就越大。
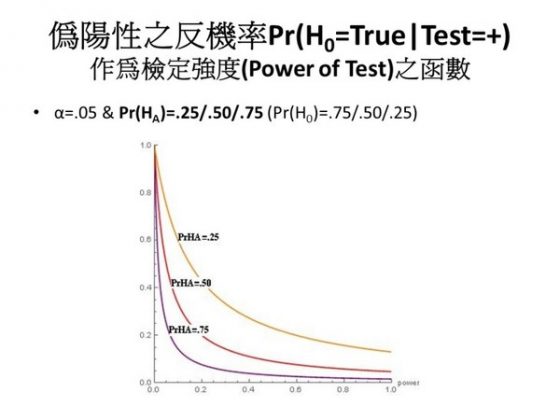
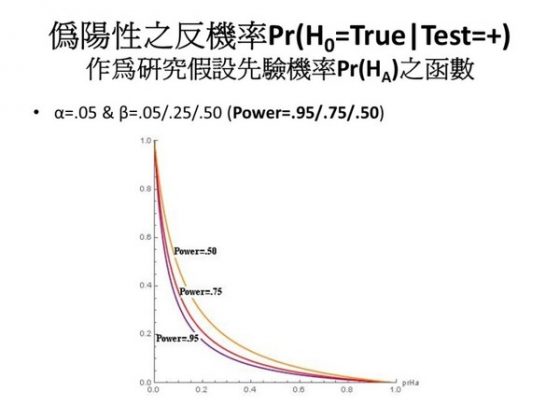
我做了一個表,列出研究假設的先驗機率,從最小排列到最大,可以看到在不同檢定強度之下,偽陽性的反機率是多少。(圖七)它可以高到近乎 1.00。換句話說,研究假設的先驗機率如果很小很小,則即使 p 值檢定顯著,但虛無假設仍然為真的機率其實還是很大很大的。如果研究假設的先驗機率是 0.5 ——你事先也許不知道哪一個是對的,你假設是 0.5,就像丟銅板一樣,此時,偽陽性的反機率才是 0.05,才跟 α 一樣。也就是說,研究假設的先驗機率必須要高於 0.5,偽陽性的反機率才會小於 0.05。可是假如你的研究假設,譬如剛剛提到的 ESP 研究,這種實驗沒有什麼理論、沒有什麼因果關係,然後你就去做了一個統計分析。換句話說這個研究假設的先驗機率可能很低,此時偽陽性的反機率其實是很高的。圖七第一欄是假設 power 為 0.95,如果 power 低一點到 0.75 呢?如果是 0.50 呢?我們可以看到其實結果差不多。當然 power 越低,問題會越嚴重,但其實差不多,當你的先驗機率是 0.5 的時候,原來是 0.05,現在是 0.09,所以差別不是特別大。原則上,power 對於偽陽性反機率的作用不是那麼強,作用強的是 prior,即是研究假設的先驗機率。
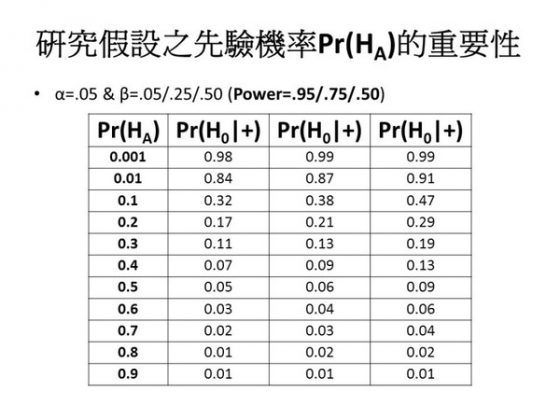
小結:當檢定強度或研究假設的先驗機率甚低的時候,α = 0.05 可能嚴重低估了偽陽性之反機率,也就是在 p 值檢定顯著的情況下,虛無假設 H0 仍然極有可能為真,而其為真的條件機率可能甚大於 α。此時如果我們拒絕虛無假設,便作出了錯誤的統計推論。
請繼續閱讀下篇:《p 值的陷阱(下):「摘櫻桃」問題》
本文《看電影學統計:p 值的陷阱》轉載自 Tse-min Lin 的部落格。









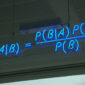




























{kind=link}
.jpg){kind=link}