


Dear Abby 是 1956 年開始發行、流傳甚廣的美國顧問專欄,起初的作者 Pauline Phillips 已在 2013 年過世,現由她女兒繼續以同名執筆經營。Dear Abby 經常為讀者提供諮商,為他們解決各種疑難雜症。下面這封讀者來函曾被列入統計學教科書裡,我也常用來作為基本統計學的教材。
「Dear Abby:
妳在專欄寫過女人懷胎266天。這是誰說的?我懷我的寶貝懷了 10 個月又 5 天 (310天)。這一點都不容置疑,因為我知道寶貝是哪天開始懷的。我老公在海軍服役,上次我們只見面一個鐘頭,而且之後就一直到生產前一天再見面,因此寶貝一定是在那個時候懷的。我不喝酒也沒亂劈腿,寶貝不可能不是老公的,請務必修正女人懷胎 266 天的說法,否則我的麻煩大了。
聖地牙哥讀者。」
我把這個材料給學生看,然後引用醫學知識,說受孕至生產時間呈常態分配,其平均數為 266 天、標準差為 16 天,要他們計算女人懷胎最少 310 天的機率,他們算出答案為 0.003 時,都發出會心的微笑。
現在我把這題目略改如下:
某貝氏統計學家與老婆婚姻生活一向平靜無波。某年元旦,兩人慶祝新年,決定生產報國,嗣後依然恢復平靜無波的生活。該年 11 月 7 日,老婆產下一女。
老公是一位統計學家,善於數算,老婆生產後,他推算如果此女確為從他所出,則老婆懷孕時間長達 310 天。根據醫學知識,一般婦女懷孕時間呈常態分配,其平均數為 266 天,標準差為 16 天。老公推算懷胎至少 310 天的機率是 0.003。

統計學家老公算出這個機率後,不禁眉頭一皺。他想:0.003是小機率事件,比統計推論的顯著水平0.05還小很多,怎麼就發生在自己家裡?此機率是由老婆受孕日期在 1 月 1 日的假設推算出來,因機率甚小,依「以否定後件來否定前件」(modus tollens)的命題邏輯,不能接受這個假設,然則難道自己戴綠帽了!當下咬牙切齒,拍桌大罵老婆。
不過老公畢竟有些學問,他再仔細一想:0.003 的機率雖然小,但若樣本夠大,這麼小的機率也會發生在很多人身上。以台灣每年大約有 20 萬新生兒來說,假設大多數為單胞胎自然生產,則每年約有 600 個媽媽懷孕時間會長達 310 天或更久。
大樂透每注中頭獎的機率 0.00000007 比 0.003 要小很多,而經常都有人中獎。相較之下,老婆中到 0.003 機率的大獎,也沒什麼好奇怪的啊。統計學家老公想到這裡,不禁笑開了嘴:這寶貝女兒,說不定還會給自己帶來財運呢。立馬到彩券行買了十張樂透。

第二天樂透開獎,十張全部槓龜,統計學家老公又懊惱起來了。他想:雖然說經常都有人中樂透,偏偏自己從來沒中過,連每期對幾十張統一發票都難得中到 200 元的小獎,哪有說這 0.003 機率的事件就輪到我?畢竟「個人中獎」和「有人中獎」是不同的事件,不能一概而論。那怎麼辦呢?究竟我該不該相信老婆?還是乾脆去查驗 DNA 算了?
貝氏統計學家老公靈光一閃,發現自己面臨的難題其實並沒有那麼簡單,而應該用貝式定理來推算。他這樣想:0.003 是在老婆未出軌的假設下計算的,因此它是一個條件機率:
Pr(產期≥11/7|受孕期=1/1)= 0.003
但對一個貝氏統計學家而言,更該問的問題其實是:既然小孩是在 11 月 7 日出生,那老婆未出軌的機率為何?換句話說,更重要的機率應該是上面那個機率的反機率:
Pr(受孕期=1/1|產期≥11/7)=?
這就是老婆未出軌的後驗機率。以貝氏統計學家的專長,老公知道要算這個後驗機率需要考慮兩個變數:
- 老婆在 1 月 1 日之後,是否有出軌受孕的機會?假設真正的受孕期是 1 月 1 日之後的第X天。X=0 代表老婆沒出軌,受孕期真的是 1 月 1 日;X>0代表老婆在 1 月 1 日後出軌才受孕。
- 自己一向對老婆有多少信心?依自己的主觀判斷,老婆未出軌,即 X=0 的機率有多少?假設 X=0 的機率為Y,X>0的機率為 1-Y,則 Y 越接近 1 信心越高,越接近0信心越低。Y是X=0的邊際機率,1-Y是X>0的邊際機率。這邊際機率也就是貝氏定理所謂的先驗機率。
另外,如果我們以D來代表懷孕時間,則不論受孕期X是哪天,小孩在11月7日出生時,D都等於310-X。我們以D<310-X代表產期在11月7日之前,D≥310-X代表產期在11月7日這天或這天之後。

D≥310-X 的機率顯然與X有關,我們用p(X)來代表此一條件機率:p(X)=Pr(D≥310-X|X)。因為懷孕時間呈常態分配:D~N(266,162),我們可以導出:
\(p\left ( X \right )= Pr\left ( D\geq 310- X|X \right )= \frac{1}{2}Erf\left ( \frac{44-X}{16 \sqrt{2}} \right )\)
這裡Erf()是誤差函數;當 X=0時,p(0)=0.003。考慮這些變數後,我們可以用下列矩陣來呈現這個貝氏定理問題:
| 「行」的條件機率 | 老婆 1/1後未出軌:X=0 (受孕期=1/1) |
老婆 1/1 後出軌:X>0 (受孕期=1/1 後第X天) |
| D<310-X(產期<11/7) | 1-p(0) | 1-p(X) |
| D≧310-X(產期≧11/7) | p(0) | p(X) |
| 「行」的邊際機率 | Y | 1-Y |
關於貝氏定理的算法,請參考我寫的《會算「貝氏定理」的人生是彩色的!該如何利用它讓判斷更準確、生活更美好呢?》。老公要求的後驗機率是:Pr(受孕期=1/1|產期≥11/7)=Pr(X=0| D≥310-X)。
要求這個機率,首先必須把上表中「行」的條件機率轉化成聯合機率。這個只要記得「聯合機率等於條件機率乘以條件本身的邊際機率」的口訣就可算出如下:
| 聯合機率 | 老婆 1/1後未出軌:X=0 (受孕期=1/1) |
老婆 1/1 後出軌:X>0 (受孕期=1/1 後第X天) |
| D<310-X(產期<11/7) | Y(1-p(0)) | (1-Y)(1-p(X)) |
| D≧310-X(產期≧11/7) | Y(p(0)) | (1-Y)(p(X)) |
| 「行」的邊際機率 | Y | 1-Y |
算出聯合機率之後,再用「條件機率等於聯合機率除以條件本身的邊際機率」的口訣就可算出所要求的「列」的條件機率:
Pr(受孕期 =1/1 │產期≧11/7)\(=Pr\left ( X=0 | D\geq 310-X\right )\) \(= \frac{Y p(0)}{Y p(0)+(1-Y)p(X)}\)
把前面算出 p(0) 和 p(X) 套入上式之後,我們可以看到後驗機率 Pr(X=0|D≥310-X) 是X和Y的函數,為了更容易分析這函數,我們先把 Y值固定,再看它如何隨 X值變化。
首先,假設老公對老婆只有Y=0.5的信心,則後驗機率的函數圖形如下:
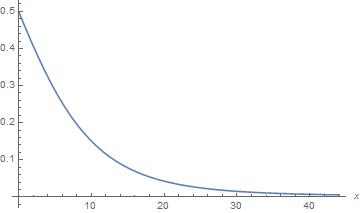
這個圖顯示如果老公本來就對老婆疑信參半,則當老婆在1月1日之後的一個半月之內有出軌的機會時,老公對老婆的信心會隨著X的增加而急速下降。當出軌的機會X 增加到預產期(1月1日後第 X+266 天)越接近 11 月 7 日時,X>0 顯得越「正常」而 X=0 顯得越「不正常」, 因此老公的信心會越低,疑心越重。特別是當老婆在二月 (X>30) 有出軌的機會時,那意謂著 11 月 7 日正是預產期的一個標準差(16天)之內,老公的信心會降至幾乎為0。
其次,如果老公平常對老婆有極高的信心,例如 Y=0.99,則後驗機率的圖形為
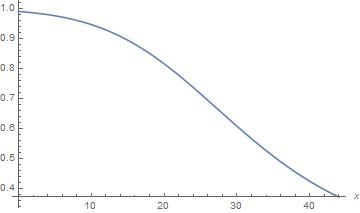
這圖顯示如果老公平常對老婆有充分的信心,則這信心隨著 X 的增加會下降得比較緩慢。即使到二月初才有出軌機會,也就是預產期開始接近 11 月 7 日時,老公對老婆仍然維持著 0.6 以上的信心。甚至當 X=44,即預產期恰恰為 11 月 7 日時,老公的信心仍在 0.37 的水平。
雖然信心不至於完全崩潰,但畢竟也會隨著 X 的增加而減小。老公算出貝氏後驗機率後應該了解,310 天是超乎尋常的懷孕時間,除非本來對老婆就有百分之百的信心,否則信心一定會下降的。雖說這只是「信者恆信,不信者恆不信」的貝氏詮釋,但在這個案例,信者卻必須要完全相信才能恆信,而不信者只要心中有點疑竇,終究會不信。
貝氏統計學者數算到這裡,長嘆了一口氣:「還是去查驗DNA吧!」
本文轉載自作者部落格,原文標題:數算日子的智慧:貝氏統計學家的婚姻難題



































 ——本文摘自《
——本文摘自《



{kind=link}