一、前言 選後的立法院三黨不過半,但民眾黨有八席不分區立委,足以與民進黨或國民黨結成多數聯盟,勢將在國會居於樞紐地位。無獨有偶的是:民眾黨主席柯文哲在總統大選得到 26.5% 的選票,屈居第三,但因其獲得部分藍、綠選民的支持,在選民偏好順序組態的基礎上,它卻也同樣地居於樞紐地位。這個地位,將足以讓柯文哲及民眾黨在選後的台灣政壇持續激盪。
二、柯文哲是「孔多塞贏家」? 這次總統大選,誰能脫穎而出並不是一個特別令人殷盼的問題,更值得關心的問題是藍白綠「三跤㧣」在選民偏好順序組態中的消長。台灣總統大選採多數決選制,多數決選制英文叫 first-past-the-post(FPTP),簡單來講就是票多的贏,票少的輸。在 10 月中藍白合破局之後,賴蕭配會贏已經沒有懸念,但這只是選制定規之下的結果,換了另一個選制,同樣的選情可能就會險象環生。
從另一個角度想:選制是人為的,而選情反映的是社會現實。政治學者都知道天下沒有十全十美的選制;既定的選制推出了一位總統,並不代表選情的張力就會成為過眼雲煙。當三股社會勢力在制度的帷幕後繼續激盪,台灣政治將無法因新總統的誕生而趨於穩定。
圖/作者自製
如果在「三跤㧣」選舉之下,選情的激盪從候選人的得票多少看不出來,那要從哪裡看?政治學提供的一個方法是把候選人配對 PK,看是否有一位候選人能在所有的 PK 中取勝。這樣的候選人並不一定存在,如果不存在,那代表有 A 與 B 配對 A 勝,B 與 C 配對 B 勝,C 與 A 配對 C 勝的 A>B>C>A 的情形。這種情形,一般叫做「循環多數」(cyclical majorities),是 18 世紀法國學者孔多塞(Nicolas de Condorcet)首先提出。循環多數的存在意涵選舉結果隱藏了政治動盪。
另一方面,如果有一位候選人能在配對 PK 時擊敗所有的其他候選人,這樣的候選人稱作「孔多塞贏家」(Condorcet winner),而在配對 PK 時均被擊敗的候選人則稱作「孔多塞輸家」(Condorcet loser)。三角嘟的選舉若無循環多數,則一定會有孔多塞贏家和孔多塞輸家,然而孔多塞贏家不一定即是多數決選制中贏得選舉的候選人,而多數決選制中贏得選舉的候選人卻可能是孔多塞輸家。
如果多數決選制中贏得選舉的候選人不是孔多塞贏家,那與循環多數一樣,意涵選後政治將不會穩定。
那麼,台灣這次總統大選,有沒有孔多塞贏家?如果有,是多數決選制之下當選的賴清德嗎?我根據戴立安先生調查規劃的《美麗島電子報》追蹤民調第 109 波(1 月 11 日至 12 日),也是選前最後民調的估計,得到的結果令人驚訝:得票墊後的柯文哲很可能是孔多塞贏家,而得票最多的賴清德很可能是孔多塞輸家。果然如此,那白色力量將會持續地激盪台灣政治!
我之前根據美麗島封關前 第 101 波估計,侯友宜可能是孔多塞贏家,而賴清德是孔多塞輸家。現在得到不同的結果,顯示了封關期間的三股政治力量的消長。本來藍營期望的棄保不但沒有發生,而且柯文哲選前之夜在凱道浩大的造勢活動,還震驚了藍綠陣營。民調樣本估計出的孔多塞贏家本來就不準確,但短期內的改變,很可能反映了選情的激盪,甚至可能反映了循環多數的存在。
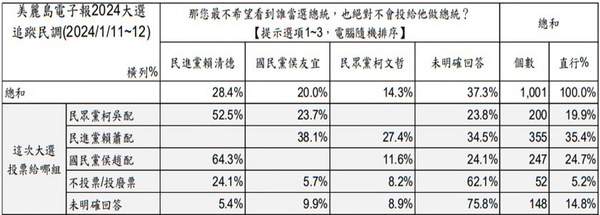
三、如何從民調樣本估計孔多塞贏家 根據這波民調,總樣本 N=1001 位受訪者中,如果當時投票,會支持賴清德的受訪者共 355 人,佔 35.4%;支持侯友宜的受訪者共 247 人,佔 24.7%。支持柯文哲的受訪者共 200 人,佔 19.9%。
美麗島民調續問「最不希望誰當總統,也絕對不會投給他的候選人」,在會投票給三組候選人的 802 位支持者中,一共有 572 位對這個問題給予了明確的回答。《美麗島電子報》在其網站提供了交叉表如圖:
根據這個交叉表,我們可以估計每一位明確回答了續問的受訪者對三組候選人的偏好順序,然後再依這 572 人的偏好順序組態來判定在兩兩 PK 的情形下,候選人之間的輸贏如何。我得到的結果是:
柯文哲 PK 賴清德:311 > 261(54.4% v. 45.6%)
柯文哲 PK 侯友宜:287 > 285(50.2% v. 49.8%)
侯友宜 PK 賴清德:293 > 279(51.2% v. 48.8%)
所以柯文哲是孔多塞贏家,賴清德是孔多塞輸家。當然我們如果考慮抽樣誤差(4.1%),除了柯文哲勝出賴清德具有統計顯著性之外,其他兩組配對可說難分難解。但在這 N=572 的小樣本中,三位候選人的得票率分別是:賴清德 40%,侯友宜 33%,柯文哲 27%,與選舉實際結果幾乎一模一樣。至少在這個反映了選舉結果的樣本中,柯文哲是孔多塞贏家。依多數決選制,孔多塞輸家賴清德當選。
不過以上的分析有一個問題:各陣營的支持者中,有不少人無法明確回答「最不希望看到誰當總統,也絕對不會投給他做總統」的候選人。最嚴重的是賴清德的支持者,其「無反應率」(nonresponse rate)高達 34.5%。相對而言,侯友宜、柯文哲的支持者則分別只有 24.1%、23.8% 無法明確回答。為什麼賴的支持者有較多人無法指認最討厭的候選人?一個假設是因為藍、白性質相近,對許多綠營選民而言,其候選人的討厭程度可能難分軒輊。反過來說,藍、白陣營的選民大多數會最討厭綠營候選人,因此指認較無困難。無論如何,把無法明確回答偏好順序的受訪者歸為「遺失值」(missing value)而棄置不用總不是很恰當的做法,在這裡尤其可能會造成賴清德支持者數目的低估。
補救的辦法之一是在「無法明確回答等於無法區別」的假設下,把「遺失值」平分給投票對象之外的其他兩位候選人,也就是假設他們各有 1/2 的機會是無反應受訪者最討厭的候選人。這樣處理的結果,得到
柯文哲 PK 賴清德:389 > 413(48.5% v. 51.5%)
柯文哲 PK 侯友宜:396 > 406(49.4% v. 50.6%)
侯友宜 PK 賴清德:376 > 426(46.9% v. 53.1%)
此時賴清德是孔多塞贏家,而柯文哲是孔多塞輸家。在這 N=802 的樣本中,三位候選人的得票率分別是:賴清德 44%,侯友宜 31%,柯文哲 25%。雖然依多數決選制,孔多塞贏家賴清德當選,但賴的得票率超過實際選舉結果(40%)。用無實證的假設來填補遺失值,反而造成賴清德支持者數目的高估。
如果擔心「無法明確回答等於無法區別」的假設太勉強,補救的辦法之二是把「遺失值」依有反應受訪者選擇最討厭對象的同樣比例,分給投票對象之外的其他兩位候選人。這樣處理的結果,得到
柯文哲 PK 賴清德:409 > 393(51.0% v. 49.0%)
柯文哲 PK 侯友宜:407 > 395(50.8% v. 49.2%)
侯友宜 PK 賴清德:417 > 385(52.0% v. 48.0%)
此時柯文哲又是孔多塞贏家,而賴清德又是孔多塞輸家了。這個樣本也是 N=802,三位候選人的得票率分別是:賴清德 44%,侯友宜 31%,柯文哲 25%,與上面的結果一樣。
以上三種無反應處理方法都不盡完美。第一種把無反應直接當遺失值丟棄,看似最不可取。然而縮小的樣本裡,三位候選人的支持度與實際選舉結果幾乎完全一致。後兩種以不同的假設補足了遺失值,但卻過度膨脹了賴清德的支持度。如果以樣本中候選人支持度與實際結果的比較來判斷遺失值處理方法的效度,我們不能排斥第一種方法及其結果。
無論如何,在缺乏完全資訊的情況下,我們發現的確有可能多數決輸家柯文哲是孔多塞贏家,而多數決贏家賴清德是孔多塞輸家。因為配對 PK 結果缺乏統計顯著性,我們甚至不能排除循環多數的存在。此後四年,多數決選制產生的總統能否在三角嘟力量的激盪下有效維持政治穩定,值得我們持續觀察。
四、結語 柯文哲之所以可以是孔多塞贏家,是因為藍綠選民傾向於最不希望對方的候選人當總統。而白營的中間偏藍位置,讓柯文哲與賴清德 PK 時,能夠得到大多數藍營選民的奧援而勝出。同樣的,當他與侯友宜 PK 時,他也能夠得到一部份綠營選民的奧援。只要他的支持者足夠,他也能夠勝出。反過來看,當賴清德與侯友宜 PK 時,除非他的基本盤夠大,否則從白營得到的奧援不一定足夠讓他勝出。民調 N=572 的樣本中,賴清德得 40%,侯友宜得 33%,柯文哲得 27%。由於柯的支持者討厭賴清德(52.5%)遠遠超過討厭侯友宜(23.7%),賴雖然基本盤較大,能夠從白營得到的奧援卻不多。而侯雖基本盤較小,卻有足夠的奧援。柯文哲之所以成為孔多塞贏家,賴清德之所以成為孔多塞輸家,都是這些因素的數學結果。
資料來源


 總統大選在即,除了選舉文宣及口水戰不斷外,各式各樣的民意調查結果幾乎攻佔了每日新聞版面,牽扯整體社會的神經。民調領先的一方,自不免心喜,民調落後者,則有各種安慰排解之道;甚至有候選人怒斥平面媒體民調不公,網路民意才準。我們不免要問:到底民調可靠嗎?
總統大選在即,除了選舉文宣及口水戰不斷外,各式各樣的民意調查結果幾乎攻佔了每日新聞版面,牽扯整體社會的神經。民調領先的一方,自不免心喜,民調落後者,則有各種安慰排解之道;甚至有候選人怒斥平面媒體民調不公,網路民意才準。我們不免要問:到底民調可靠嗎?