從「看不見」到「看見病毒入侵」——顯微技術如何一步步解密流感?
2025年初知名藝人大S因流感過世,震驚社會;隨著冬季氣溫下降,流感疫情又將蠢蠢欲動。所幸得益於顯微技術的進步,科學家們在百年前「看見」流感病毒,現在進而拆解流感病毒進入細胞的動態過程,希望能進一步研發更有效的抗病毒療法。
流感是感染人類流感病毒所引發的急性病毒性呼吸道疾病,常引起發燒、咳嗽、頭痛、肌肉痠痛、疲倦、流鼻水、喉嚨痛等,多數國家每年均會發生週期性流行。
看不見的敵人,橫掃全球
除了週期性的地區流行,流感也曾出現大規模疫情,造成世界性大流行。其中1918年流感大流行(又稱西班牙流感)最為嚴重,導致全球數千萬人死亡。
1918年正值第一次世界大戰,美軍在主要入境港口之一,法國的布列斯特(Brest)首次出現流感疫情;4月中旬,波爾多軍醫院也出現了疫情。這些疫情持續時間短暫且無害,死亡人數很少,士兵們很快就從所謂的「三日熱」(the three-day fever)中恢復。
之後,法國和英國部隊也陸續出現流感病例,位於法國聖納澤爾(Saint-Nazaire)的年輕士兵成群感染。1918年5月疫情擴散至索姆河前線(Somme)和洛林地區(Lorraine),前線每天報告新增1500至2000名病例。巴黎於6月受到影響,疫情持續蔓延至英國、德國、義大利,西班牙也未能倖免。
但當時第一次世界大戰的主要參戰國家,如德、英、法、美等國為了避免影響士氣,嚴格管制媒體報導疫情。然而保持中立而未參戰的西班牙,因為沒有實施戰時審查制度,西班牙媒體自由報導著流感相關新聞,甚至連西班牙國王阿方索十三世(King Alfonso XIII)感染重症的消息也被廣泛報導,造成西班牙疫情特別嚴重的錯覺,也因此被命名為「西班牙流感」。
1918年5月28日《太陽報》的頭條新聞,內容為:馬德里三日熱病肆虐,八萬人罹病,國王陛下病重。圖片來源:Wiki 經由戰爭和海運,疫情擴散至全球,西班牙流感出現三波疫情高峰。第一波發生於1918年春季;到了1918年秋季,出現第二波疫情,是死亡率最高的一波;第三波則發生於1919年冬季至1920年春季,死亡率介於第一波和第二波之間。1918到1920年,估計西班牙流感造成全球約5000萬人死亡。
雖然流感造成的死亡人數更甚於一戰死亡人數,但人們還不清楚流行性感冒是由什麼病原體造成。許多科學家開始積極投入假定病原體的研究,大量患者體內存在流感嗜血桿菌(Haemophilus influenzae,前稱費弗氏桿菌Pfeiffer’s bacillus),但也有些病患體內無法分離出病菌,無法滿足柯霍式法則的條件。不過當時流感嗜血桿菌仍被認定是流感的病原體。
柯霍氏法則(Koch’s postulates):
病體罹病部位經常可以找到大量的病原體,而在健康活體中找不到這些病原體。
病原體可被分離並在培養基中進行培養,並記錄各項特徵。
純粹培養的病原體應該接種至與病株相同品種的健康植株,並產生與病株相同的病徵。
從接種的病株上以相同的分離方法應能再分離出病原體,且其特徵與由原病株分離者應完全相同。
直到1933年,英國科學家史密斯(Wilson Smith)、安德魯(Christopher Andrewes)和萊德勞(Patrick Laidlaw)在倫敦國家醫學研究所(NIMR)分離並鑑定出人類A型流感病毒。他們在流感患者身上收集鼻涕和喉嚨漱口液,過濾後滴入雪貂體內。之後雪貂開始打噴嚏並出現類似流感的症狀,並且傳染給同一籠的雪貂。他們證明了這種感染是可重複的,顯示該病原具感染性,而不是偶然。
1936年,一名年輕的倫敦國家醫學研究所研究員意外接觸到已感染流感病毒的雪貂的噴嚏分泌物。兩天後,他也出現流感症狀,並在喉嚨分離出病毒,血清出現特定抗體。這次意外完成的傳播鏈,實現了柯霍氏法則第三條。之後,B型和C型流感病毒也分別在1940年、1947年被陸續分離出來。
揭開奈米級真實樣貌
儘管此時人們已經知道流感的病原體是可過濾、體積比細菌小的病毒,但一直沒有「見到本尊」。
1931年德國科學家克諾爾(Max Knoll)與魯斯卡(Ernst Ruska)合力製作並發表了史上第一台電子顯微鏡。電子顯微鏡以電子束取代光來觀察物體,由於電子波長短於可見光,解析度提升到奈米等級,也使得病毒得以現形。
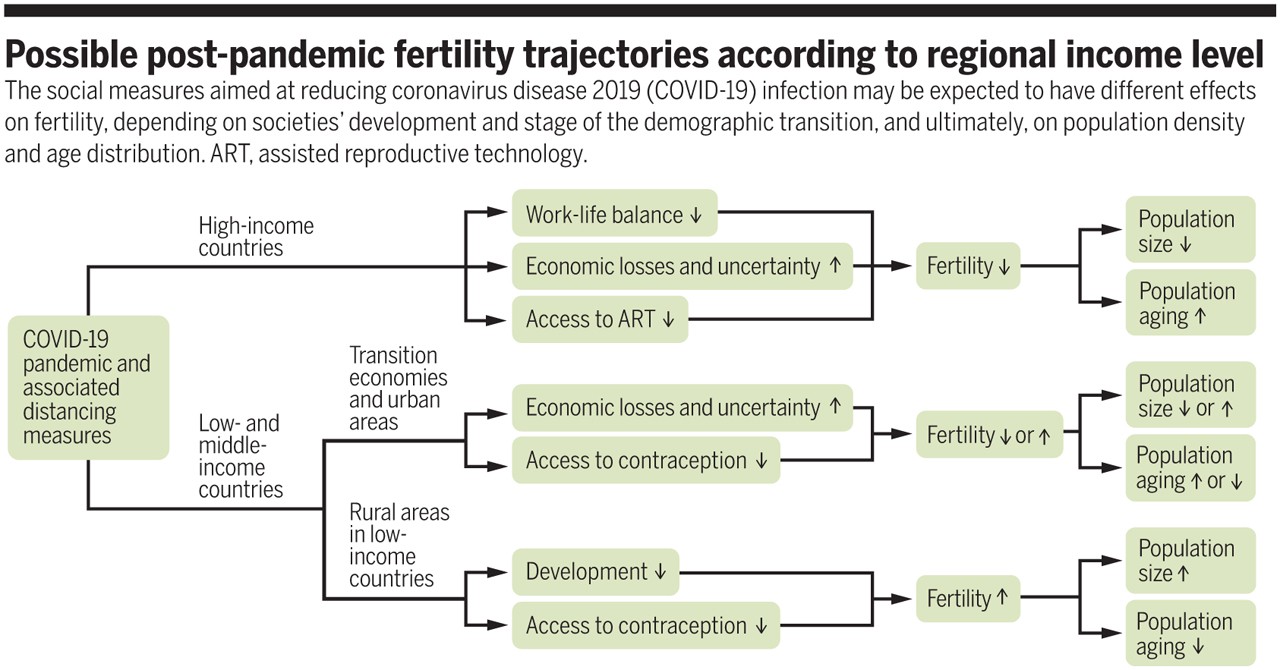
用電子顯微鏡觀察,流感病毒呈現球形或絲狀;球形病毒的直徑約100奈米,絲狀病毒的長度則通常超過300奈米。
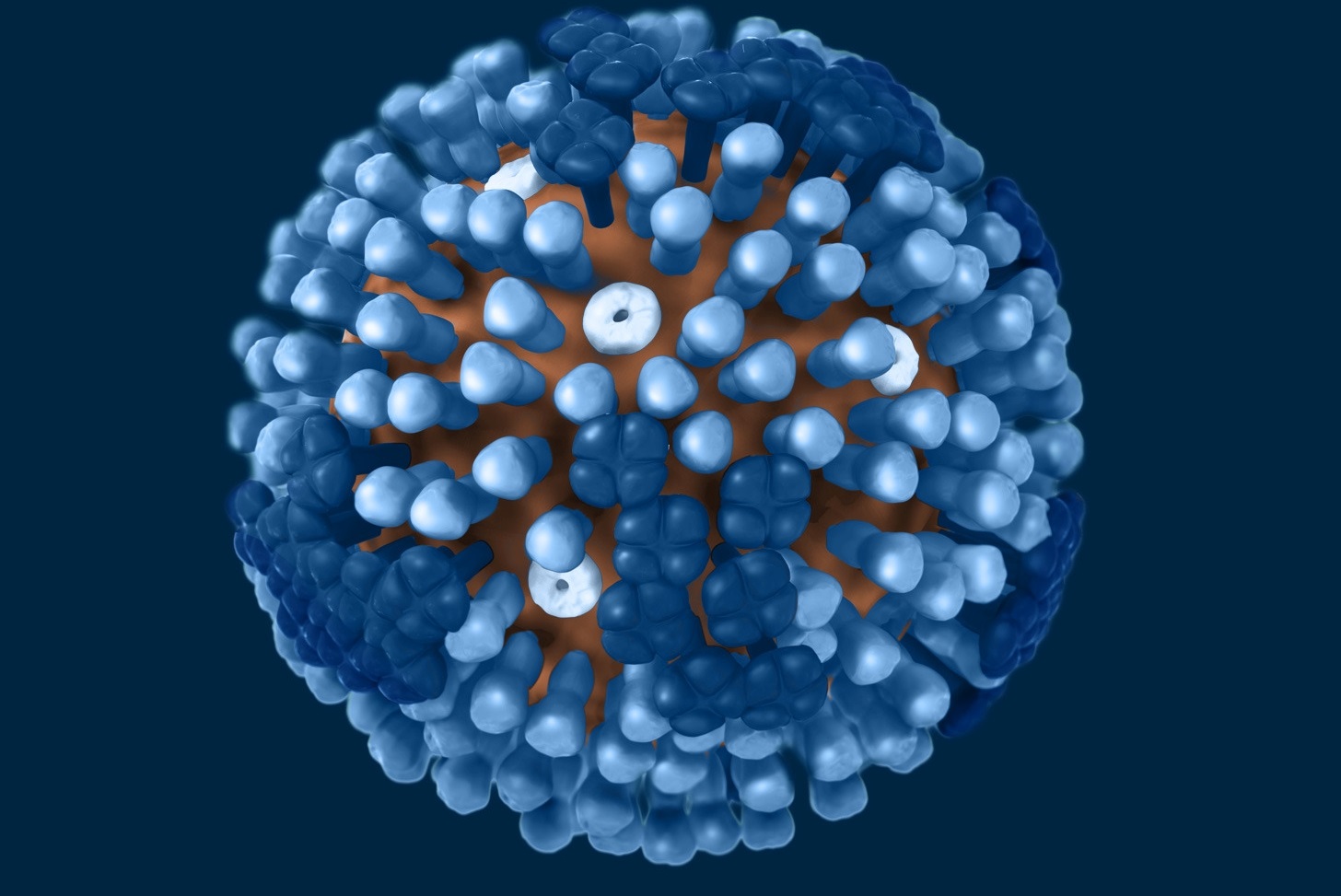
在電子顯微鏡下,其實很難僅靠外觀分辨A型和B型流感病毒。A型流感病毒的最外層是一層來自宿主細胞的脂質膜,就像穿上「外套」一樣。套膜外則有明顯的尖釘(spikes)構造,就像佈滿尖刺的球體。這些「尖刺」主要由兩種醣蛋白組成:血凝素(HA)和神經胺酸酶(NA),是流感病毒感染能力的關鍵,也正是H1N1、H3N2等亞型命名的由來。
病毒外殼上還零星分布M2離子通道蛋白(M2 ion channel protein),但數量非常少,平均每100至200個HA,才有一個M2。套膜下則有M1基質蛋白(matrix protein M1)支撐病毒結構,維持病毒穩定。B型流感病毒的整體結構和A型非常類似,只是膜蛋白組成略有不同,除了HA和NA之外,另有兩種B型流感獨有的NB和BM2蛋白。至於C型流感病毒,外型就和A、B型明顯不同,它們在感染細胞表面時,能形成長達數百微米的「繩索狀結構」。
然而,電子顯微鏡有其限制:樣本必須固定、脫水,只能看到「結果」,而非「過程」。雖然隨著螢光標記與活細胞顯微術的進步,研究者也開始追蹤流感病毒在細胞內的移動路徑。但螢光顯微鏡看到的是標記訊號,而非病毒的真實形貌;病毒如何與細胞膜互動、是否造成結構變形,仍多半停留在推測層次。
(左)穿透式電子顯微鏡(TEM)下所見的流感病毒顆粒,周圍環繞明顯的釘突;(右)流感病毒的3D模型。圖片來源:美國CDC Public Health Image Library (PHIL) 以「病毒視角」看流感病毒互動
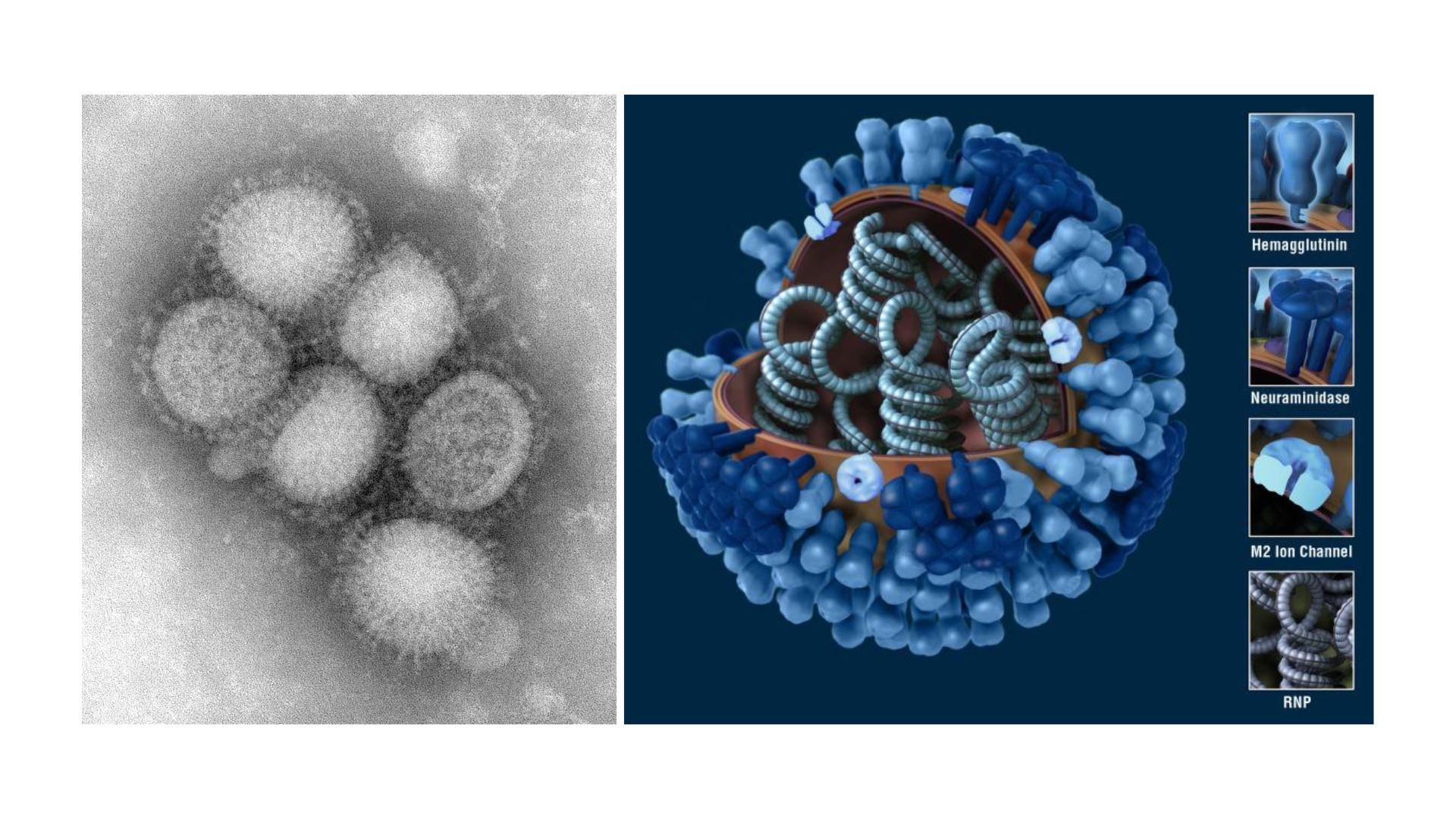
蘇黎世聯邦理工學院分子醫學教授山內洋平(Yohei Yamauchi)帶領的研究團隊,使用改良的「病毒視角」原子力顯微鏡(virus-view atomic force microscopy),首次在活細胞表面即時觀察到單顆A型流感病毒進入細胞的過程。
原子力顯微鏡是以奈米探針,在樣本表面掃描,透過感測微小的力學變化來重建樣本形貌。研究團隊將原子力顯微鏡與共軛焦螢光顯微鏡整合,一邊確認顆粒的「身分」,一邊記錄其造成的細胞膜變形。
他們看到流感病毒在細胞表面並非立刻被吞噬,而是先停留一段時間,並在接觸處誘導細胞膜產生局部下陷。慢慢地病毒被細胞膜包覆,最終完成內吞。結果顯示病毒不是「自行闖入」,細胞也「主動」參與反應。細胞將對內吞作用重要的網格蛋白(clathrin protein)聚集到病毒所在的位置,細胞表面也會在病毒所在位置隆起,把病毒「往內拉」。如果病毒遠離細胞表面,這種波浪狀的膜運動也會增強,彷彿細胞要把病毒「抓回來」一般。
從光學顯微鏡的「看不見」,到電子顯微鏡的「看見結構」,再到原子力顯微鏡的「看見動態互動」,顯微技術的演進不只是解析度的提升,更不斷改變人們對流感病毒的理解,進一步為疾病研究和防治開啟新的可能。
「病毒視角」顯微鏡(ViViD-AFM)示意圖及觀察病毒互動影像。圖片來源:Yohei Yamauchi團隊論文 參考資料:
Bouvier, N. M., & Palese, P. (2008). The biology of influenza viruses. Vaccine , 26 Suppl 4(Suppl 4), D49–D53.
Berche P. (2022). The Spanish flu. Presse medicale (Paris, France : 1983) , 51(3), 104127.
Yoshida, A., Uekusa, Y., Suzuki, T., Bauer, M., Sakai, N., & Yamauchi, Y. (2025). Enhanced visualization of influenza A virus entry into living cells using virus-view atomic force microscopy. Proceedings of the National Academy of Sciences of the United States of America , 122(38), e2500660122.
A year-round disease affecting everyone. WHO
延伸閱讀:













































{kind=link}