時空旅行有可能嗎?我們如何感受時間?談談那些神秘的時空理論!

時空旅人存在嗎?霍金的未來派對
回到過去不只是科幻迷的夢想,每個人或多或少,都有一兩件想要改變或挽回的事。可惜的是,我們在空間中可以自由移動,甚至走到馬路對面再走回來,回到起點。(當然,也有人走個斑馬線就到了異世界)然而在時間軸上,我們卻不斷地向前進,不能倒頭。這是為什麼呢?
物理大師史蒂芬.霍金,對時間的研究可說是不遺餘力,他也透過著名的《時間簡史》、《大設計》等著作,向我們闡述宇宙與時空的奧妙。霍金是位時空旅行的夢想家,為了驗證世界上是否真的有時空旅人,他甚至曾經做了一個有趣的實驗。
2009 年 6 月 28 日中午 12 點,霍金認真地在劍橋大學舉辦一場盛大派對,桌上擺了美食與香檳,一旁的柱子上還綁了三色氣球。霍金仔細地準備好公開邀請函,上面寫著「誠摯地邀請您參加時空旅行者派對」,附上時間、地點甚至是準確的經緯度,希望時空旅人沒有迷路的藉口。
邀請函對外公開時間是派對結束「之後」,他確保這個訊息可以流傳數百年,並希望有時空旅人能看到邀請函,回到過去參加這個派對。可惜的是,無人響應、無人到場。霍金認為這證明了他的推論——時間旅人不存在。當然,如果當時有時空旅人跳出來打臉他,他也會感到非常開心。還是你認為,這只是因為時空管理局下明令,禁止未來人透露各種訊息給過去的人類,對於結果其實不需要感到意外呢?
為何我們不能讓時間倒轉?霍金的三支箭矢
在研究時空旅行之前,我們先來了解,為什麼我們總無法倒轉時間。
對於時間的流向,霍金提出了「三支箭矢」的構想,這不是安倍晉三的經濟學箭矢,而是時間箭矢。這三支時間箭矢,分別為心理學箭矢、熱力學箭矢、和宇宙箭矢。
心理學箭矢,就是我們生物感受到時間的流向。熱力學箭矢,則是熱力學中「熵」越來越大的方向,也是世上一切現象運行的方向。
所謂「熵」,是我們用來評估一個狀態的混亂程度的物理量。熵越大越混亂;例如,髒亂房間的熵比整齊的房間還大、摔成碎片的杯子熵比完整的時候還要大。根據熱力學第二定律,世間一切現象都會朝著熵變大的方向發展:杯子一定會摔碎、裡面的水一定會灑滿一地。但是,我不是可以把髒亂的房間整理整齊嗎?沒錯,但熱力學告訴你,在你整理房間的時候,你可能為世界增加了 20 點的秩序量,但你身體因為運動放出的熱能,可能會為整個宇宙增加 100 點的混亂量,整體的熵還是增加的。
 熱力學告訴你,在你整理房間的時候,你可能為世界增加了 20 點的秩序量,但你身體因為運動放出的熱能,可能會為整個宇宙增加 100 點的混亂量,整體的熵還是增加的。圖/envatoelements
熱力學告訴你,在你整理房間的時候,你可能為世界增加了 20 點的秩序量,但你身體因為運動放出的熱能,可能會為整個宇宙增加 100 點的混亂量,整體的熵還是增加的。圖/envatoelements
至於最後一根箭,宇宙箭矢,則是宇宙膨脹的方向。宇宙在膨脹過程中,粒子會越加分散,熵也會持續增加,因此宇宙箭矢會與熱力學箭矢同方向。
回到體感時間,既然熱力學箭矢代表世界運行的方向,如果熱力學箭矢與心理學箭矢的方向相同,那我們就會看到杯子掉到地上摔破、水灑出來。但如果反過來,熱力學箭矢跟心理學箭矢反向飛行,那我們就能看到天能中的逆熵,我們會看到杯子從碎片修復、回到桌上,水也跟著回到杯子之中。
既然如此,那我們要怎麼讓這兩支箭矢反向飛行呢?遺憾的是,因為我們的這具肉身限制,要感受環境、需要外界訊號刺激,並且轉為神經訊號到大腦;要思考,神經細胞必須透過呼吸作用,取得能量來持續運作。我們的一舉一動,建立在生物與化學反應上,也因此必須遵守熱力學第二定律。如果不遵守,我們甚至無法獲得能量,生命根本無法維持。這種現象也被稱為「弱人擇原理」。
為何心理學箭矢和熱力學箭矢必須同向?因為不同向,我們就無法存在,也就無法思考這個問題。
超光速可以連接過去?
在 DC 宇宙的影視作品中,能穿越時間的閃電俠肯定是經典代表。在 DC 宇宙,透過神速力的加持,閃電俠可以突破光速,回到過去。這會發生什麼事情呢?
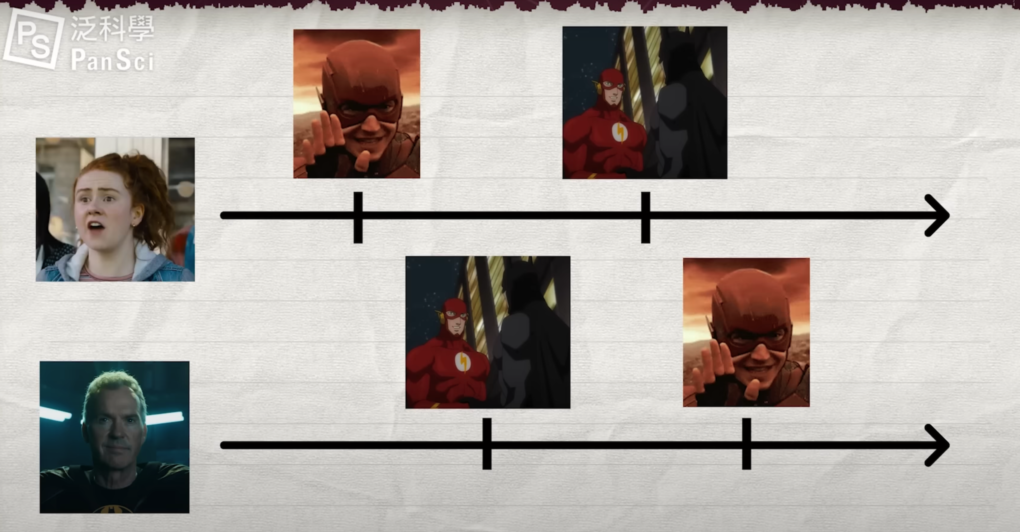
根據相對論,在速度接近光速時,時間會變為相對,對於不同速度的觀察者來說,也會產生歧異。舉例來說,如果閃電俠在路上與粉絲打招呼,卻被蝙蝠俠催著去開會。無奈的他,只好與粉絲說掰掰,接著以超光速前往蝙蝠俠基地,準時趕上會議。如果粉絲這時候用望遠鏡看著這一切,他們會看到,閃電俠先跟自己說了掰掰,接著才趕上遠處的會議,而且以距離計算,閃電俠肯定超越了光速。
 粉絲的時空視角:閃電俠先跟自己說了掰掰,接著才趕上遠處的會議。圖/Pansci
粉絲的時空視角:閃電俠先跟自己說了掰掰,接著才趕上遠處的會議。圖/Pansci
然而神奇的事來了,如果此時蝙蝠俠等得不耐煩,突然想回高譚市與小丑敘敘舊,他拿出了從沒有任何人知道的特製蝙蝠車,一台可以以接近光速移動的蝙蝠車,從基地離開。就在這個時候,從他的角度觀察閃電俠,他會發現,閃電俠先到達了會議室,接著才發生遠處閃電俠與粉絲說掰掰的場面。蝙蝠俠和粉絲們看到的情景大不相同,不同觀察者的時間產生歧異了。
 蝙蝠俠的時空視角:閃電俠先到達了會議室,接著才發生遠處閃電俠與粉絲說掰掰的場面。圖/Pansci
蝙蝠俠的時空視角:閃電俠先到達了會議室,接著才發生遠處閃電俠與粉絲說掰掰的場面。圖/Pansci
甚至對於獲得高速移動能力的蝙蝠俠來說,如果他的蝙蝠車也能以超光速移動而且速度夠快,他甚至能在閃電俠到達會議室前,就先跑去正在與粉絲說掰掰的閃電俠旁邊,告訴他開會的會議結論,你不用再跑一趟了。
看來透過超光速回到過去,還真的是有可能的。但別忘了相對論施加的限制,要將物體越加速到接近光速,所需要的能量就越大。如果要將有質量的物體加速到等於光速,就需要無限大的能量。或許閃電俠的神速力確實能辦到,當然這也就代表,閃電俠或許是DC宇宙中無敵的存在了。
顯然,沒有神速力,也不是超級英雄的我們,把自身加速到超光速來時間旅行,顯然不是一個好選項。但如果我們能扭曲時空、建立捷徑,達成超光速呢?
就算兩地相隔數公里,如果我們能將時空對折,並在中間打一個洞,創造出一個任意門,只要跨過一步就能跨越原本要走上半天的路程,不就超光速了嗎?事實上,不能超光速移動的我們,跨越時空的「蟲洞」,很有可能就是我們最後的選項。
蟲洞有辦法被製造嗎?
蟲洞的概念不只是存在於科幻小說的情節,1935 年,愛因斯坦與羅森發表一篇論文,指出根據廣義相對論的計算,在某些條件下,宇宙中可能出現連接不同時空區域的「蛀孔」,稱為愛因斯坦——羅森橋,也就是我們說的「蟲洞」。
 蟲洞在地面可能的樣子。圖/wikipedia
蟲洞在地面可能的樣子。圖/wikipedia
正常來說,宇宙中的能量或有質量的物質,會在宇宙中產生如同球面的正時空曲率,產生引力。如果想要產生負時空曲率,將時空向內凹陷,創造出蟲洞,我們就需要創造出負能量或具有負質量的物質。
那麼要怎麼做出負能量或負質量的物質呢?
接下來我們進入到腦洞大開的環節:還記得我們在量子系列第五集,介紹薛丁格的貓時提到的不確定性原理嗎?根據這個理論我們可以預測,就算在空無一物的「真空」中,其實非常熱鬧。在真空中,會不斷出現正粒子與反粒子組成的虛粒子對,他們一起出現,又重新碰撞、互相湮滅,這個過程被稱為量子漲落。雖然兩種粒子會互相湮滅,但不論正、反粒子都是擁有正能量與正質量,在量子漲落的過程中,為了維持整體的能量穩定,某些地方出現正能量密度,某些地方就會出現負能量密度。以此架構延伸,我們便能在真空中設計兩塊金屬板,能透過卡西米爾效應,在兩塊金屬板中,創造出負能量的區域。而這個卡西米爾效應,也在 1996 年在實驗中被實際觀測到。
 卡西米爾效應示意圖。圖/wikipedia
卡西米爾效應示意圖。圖/wikipedia
透過蟲洞時間旅行有可能嗎?
那麼通過蟲洞時間旅行是可能的嗎?根據後來的計算,愛因斯坦——羅森橋,也就是蟲洞的存在時間非常短,會在太空船通過之前,就塌縮成奇異點。而蟲洞的通道大小,也不足以讓任何粒子大小的物體穿過。
但霍金沒有將可能性說死,或許將來,會有技術可以撐開並維持蟲洞的存在,足以讓人類穿梭而行。或許時空旅行,將成為現實。除此之外,超弦理論也有一些說法證實蟲洞可能存在,但目前弦理論都還僅止在數學計算,還未能應用在實際現象中。
但你說,霍金不是已經透過時間旅人派對證實,沒有時空旅人了嗎?霍金解釋,根據時間悖論問題,我們看不到時空旅人,是非常正常的。至於為何無法修改過去,產生時間悖論,有可能是當過去已被「測量」,那宇宙就不能再被更改,又或是真的有某種有形或無形的時空管理局,在維持這個世界的安全呢?
歡迎訂閱 Pansci Youtube 頻道 獲取更多深入淺出的科學知識!











































{kind=link}
{kind=link}