文 / 陳紹慶(慈濟大學人類發展學系專任助理教授)
現代科學知識的生產流程是專業研究者定義有意義的研究問題,再運用的研究方法搜集與分析資料,寫成論文投稿經過同行審查,才能在專業期刊或出版管道正式發表。科學社群發展這套流程的初衷是尊重每位科學研究者都有維持科學知識結構性誠篤(structural integrity)的自律意識,提出的研究結果都經得起再現研究的考驗。然而即使到今天,資料造假與抄襲等違反學術倫理的事件依然在許多科學領域不斷發生,而無法用具體倫理規範約束,卻會損害結構性誠篤的問題,是通過同行的專業審查才出版的研究成果,卻不能被其它研究者以相同或接近的方式重現(replication)。就以心理學來說,先前曾有台灣的學界大老對此問題挑起公開批判,只是後續輿論焦點都擺在由此衍生的計畫經費補助不公、專業人士翻譯錯誤等爭議,最初的批判起點反而沒有激起更深刻的了解與思考。在此介紹去年底由維吉尼亞大學的心理學教授Brian Nosek領導多位心理學實驗室主持人進行的跨國性開放式研究專案,以及一些對此專案成果的回應。
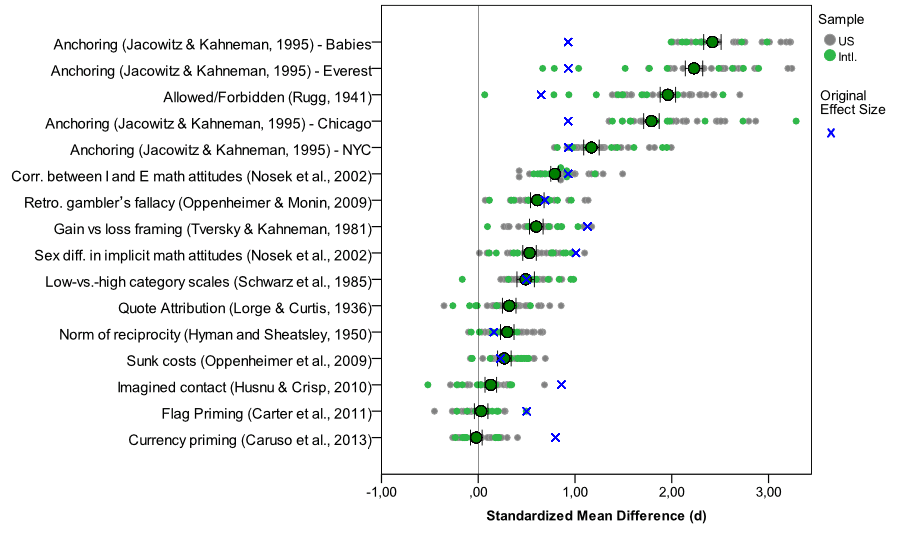
這項專案的實驗刺激及程式、原始實驗資料、還有分析程序,以及最後的論文初稿,完全公開在開放科學平台網站,上圖是所有實驗結果總結,讀者可至專案網頁,瀏覽或下載公開的研究資料。Nosek教授與幾位主要主持人,挑選已發表於專業心理學期刊的10篇論文,其中13項實驗。加入此專案的所有實驗室主持人,以邀請受試者到實驗室,或透過網路徵求自願者登錄指定網站進行實驗。為了各實驗室執行的實驗內容一致,且能快速完成,這13項實驗被選擇的考量是因為能透過網路進行,執行時間不長(每項實驗進行長度不超過2分鐘),設計簡單(只有一組實驗組與一組控制組),以及實驗效應的多樣性。這些實驗的測量變項是受試者的答對率、量表分數或同組內回答人數等等,因此每個實驗室完成一項實驗結果的分析,就轉換成效果量(effect size),評估每項實驗的原始研究結果與重現結果的差異,上圖中的每一點代表原始研究結果與每次重現結果的效果量,依所有重現結果的平均效果量大小由上而下排列。
對心理學研究有相當認識的讀者應能發現,13項實驗都是來自決策的認知心理學或相關的社會認知研究,例如Tversky與Kahneman建立學術權威的錨點效應(anchoring)與框架效應(framing)。但Nosek教授與其它共同主持人是根據容易執行的考量選擇進行這些實驗,並非每個實驗背後心理學理論有何關聯。所以即使重現研究的結果證實錨點效應與框架效應確實經得起考驗,再現的結果並不能告訴我們在這些議題上有什麼更新的知識。真正要注意的是所有原始研究公佈的統計結果都有達到顯著水準,轉換為標準化的效果量也都有顯示原始研究報告的實驗組與控制組有起碼差異,然而重現結果顯示排序最末的三項實驗重現結果平均效果量幾乎等於0,代表原始論文報告的效應並不能運用論文作者公開的方法做到起碼的重現。這些實驗都是經過同行審查的知識生產流程發表,如果同一個學術領域內所有研究者對自已發表的結果都有相同的自律意識,所有實驗的原始結果與再現結果應是一致,這個領域產生的知識才具備結構性誠篤。上圖所列的實驗原始出處,讀者可以從專案網頁公開的報告中了解更多背景資訊。
2013年11月下旬專案結果初次發表後,我注意到專業科普作家Ed Young與Zwaan教授隔天的回應。Ed Young在去年底之前撰寫了三篇與此專案有關的文章,分別發表在個人部落格、《Nature》期刊、與《Discovery Magazine》探討方向和近年來他持續追蹤的心理科學研究造假案例,剛好也是社會認知的研究有關。他肯定Nosek教授等人的做法,並提倡推廣開放科學研究,做為強化科學研究成果出版後審查機制(post-publication review)的概念。Zwaan教授在我之前的文章曾介紹他對重現研究的看法,原則上他也肯定出版後審查機制的重要性,他的回應提出更進一步的願景,就是專業的科學研究者,在提出原創性研究成果的時候,就能檢驗實驗結果的可重現性,讓同行研究者不必耗費更多的人力物力,來驗證或推翻一個概念不週全,但是有統計顯著的結果支持的主張。
為何有統計顯著的結果還要檢驗能否重現?因為一次實驗結果只是呈現多次實驗的一種可能性,如果最初的研究剛好是最極端的結果,其它研究者必須進行更多次實驗,或者招募更多受試者收集資料,才能說服所有人接受這項研究無法帶來有意義的知識。然而從最初的研究到後續研究的重現檢驗,這類研究發現完全不能帶來任何新的知識,我認為這是心理學等行為與社會科學被批評並非硬科學的主因。不過還是有許多經得起考驗的研究結果,不僅在相同或接近的研究條件下可被重現,在符合目的的範圍內改變研究設計或測量方法後,依然顯現同樣的結果,例如Stroop效應、遺忘曲線。一個成熟的科學領域需要經得起考驗的研究案例支持,才能建立整體的結構性誠篤,說服大眾相信一個科學社群生產的知識。而Nosek教授等研究者的作法,示範一種願意促進科學知識進步的專業與業餘人士,理解與檢驗公開的科學研究成果有沒有帶來真正有意義的知識。































-200x200.jpg)