新物種如何誕生,是演化最重要的主題之一,正如達爾文代表作的書名《物種起源》(The Origin of Species,也常譯作《物種源始》)。隨著基因體學帶來愈來愈多新知識,人們對物種的想法也不斷演變。
2023 年發表的一項研究調查多種金絲猴的基因組,意外發現有一種金絲猴,竟然直接由不同物種合體形成。這是靈長類的第一個案例,動物中也相當少見。
黔金絲猴。圖/Current status and conservation of the gray snub-nosed monkey Rhinopithecus brelichi (Colobinae) in Guizhou, China 五種金絲猴的親戚關係
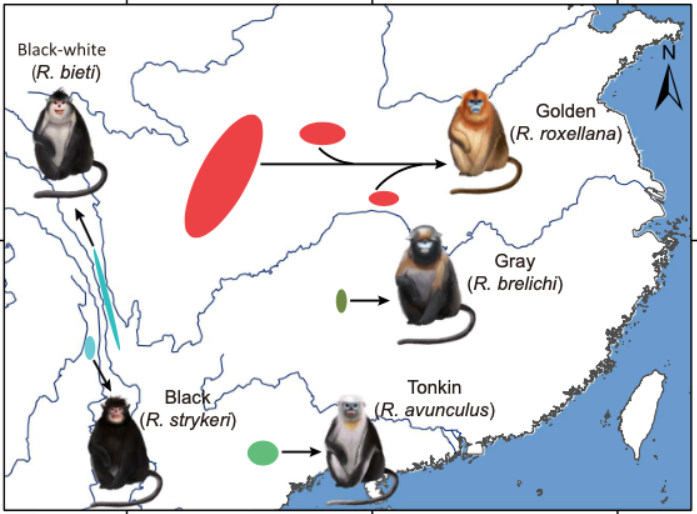
金絲猴(snub-nosed monkey,學名 Rhinopithecus ,也稱為仰鼻猴)主要住在中國西南部和東南亞,目前有五個物種。牠們的中文名字依照地名,英文名字則多半根據顏色。
古時候金絲猴的分布範圍更廣,像是台灣也曾經存在過,如今卻只剩下化石。現今五個物種分別為:
*(雲南)滇金絲猴(black-white 黑白,學名 Rhinopithecus bieti )
* 緬甸金絲猴(black 黑,學名 Rhinopithecus strykeri )
*(四川)川金絲猴(golden 金,學名 Rhinopithecus roxellana )
*(貴州)黔金絲猴(gray 灰,學名 Rhinopithecus brelichi )
* 越南金絲猴(Tonkin 越南東京,學名 Rhinopithecus avunculus )
五種金絲猴。圖/參考資料1 比對五款吱吱的 DNA 差異,可知滇、緬甸金絲猴的親戚關係最近,川金絲猴則和黔金絲猴較近,但是黔金絲猴明顯介於兩者之間。黔金絲猴在自己獨特的變異之外,僅管基因組整體更接近川金絲猴,也有不少部分和滇、緬甸金絲猴相似。
見到不同物種之間共享血緣,最直覺的想法是,兩者的祖先發生過遺傳交流。但是詳細比對後,研究猿認為還有機率更高的可能性。
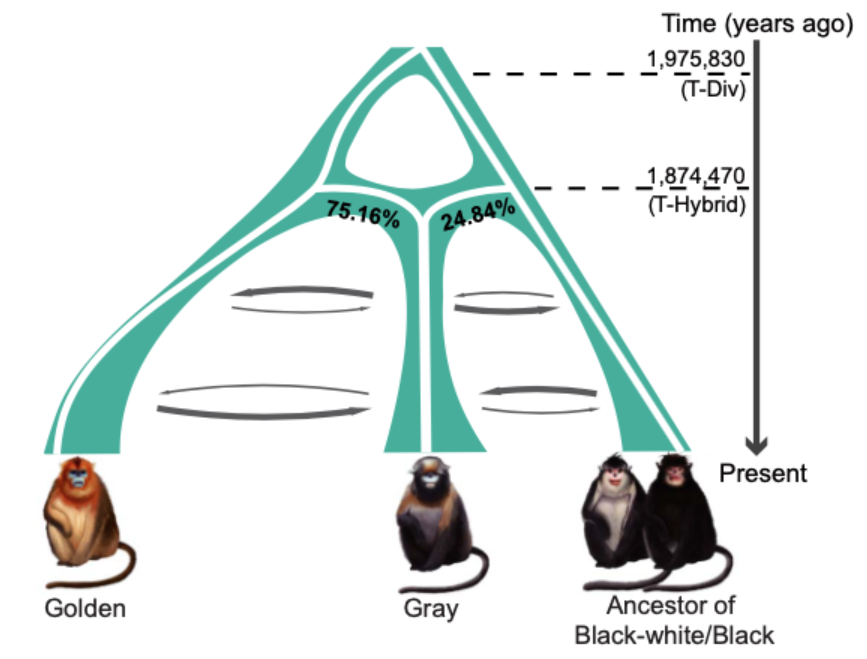
最滑順的劇本是,大約 197 萬年前,滇、緬甸金絲猴的共同祖先,和川金絲猴分家;又經過十幾萬年,約莫 187 萬年前,兩群金絲猴再度合體,形成一個全新的支系,也就是黔金絲猴的祖先;後來滇、緬甸金絲猴再衍生出兩個物種。
這形成如今我們見到的狀態:黔金絲猴大約 75% 血緣來自川金絲猴,25% 源於滇、緬甸金絲猴的共同祖先。
四種金絲猴的親戚關係,與遺傳交流。圖/參考資料1 靈長類首見,雜交直接形成新物種
或許有人會疑惑,看起來都是共享 DNA 變異,上述說法和「不同物種之間,發生過遺傳交流」有何差別?
差別在於,所謂「不同物種之間」,指的是新物種已經誕生一段時間以後,彼此間又發生 DNA 交流,這個一點都不稀奇。例如 A、B 物種間發生關係,變成 A 的遺傳背景下,又有一點 B 血緣的物種。
但是黔金絲猴的狀況是,新物種之所以誕生,就是不同物種直接合體所致。例如 A、B 物種發生關係,衍生出差異更大,不是 A 也不是 B,足以認定為新物種的 C。
假如重建的劇本為真,這就是首度在靈長類中觀察到,不同物種直接合體形成新物種的「hybrid speciation」。可以翻譯為「雜交種化」,不過「合體種化」似乎更直觀。
哥倫比亞猛獁,想像畫面。圖/wiki 經由兩個物種雜交,直接產生新物種的方式,植物較為常見,哺乳類動物極少。此前古代 DNA 研究認為,已經滅絕的美洲大象「哥倫比亞猛獁」(Columbian mammoth,學名 Mammuthus columbi )是不同猛獁象合體產生的新物種,但是證據沒那麼充分。
或許沒有那麼罕見?
直接雜交產生新物種,會很難想像嗎?仔細想想,金絲猴的案例可能沒那麼驚悚,或許還有某種程度的普遍性。
回到當初的情境,所謂「兩個物種」在當時其實只分家十萬年而已,差異應該仍很有限。是又累積 180 萬年的分歧到今日,才顯得親戚之間明顯有別。
這邊 197 萬、187 萬、十萬年都是根據 DNA 變異的估計,實際數字未必如此。不過順序大概差不太多,就是首先分出兩群,很短的時間後又合體產生第三群,再經歷好幾倍的時間直到現在。
假如川金絲猴不幸滅團,缺乏樣本可供比較,那麼黔金絲猴與另外兩種近親,看起來就單純是 187 萬年前分家。 值得注意的是,我們能判斷演化樹上的不同分枝曾經合流,來自對樹形的比對。假如川金絲猴不幸滅團,這棵演化樹中我們只剩下三個物種的樣本,便會判斷黔金絲猴是跟另外兩種親戚分家而成,卻完全不會察覺有過合體種化。
這麼想來,雜交誕生新物種的現象,或許沒那麼罕見,只是時光抹去了許多痕跡。
血緣融合,猴毛也是奇美拉
另一有趣的發現是毛色演化。金絲猴現今四個物種,外表的毛色為一大差異。毛色與深色素有關,深色素愈多,毛色會顯得愈黑,相對則是愈淡,會呈現白毛、黃毛、金毛。
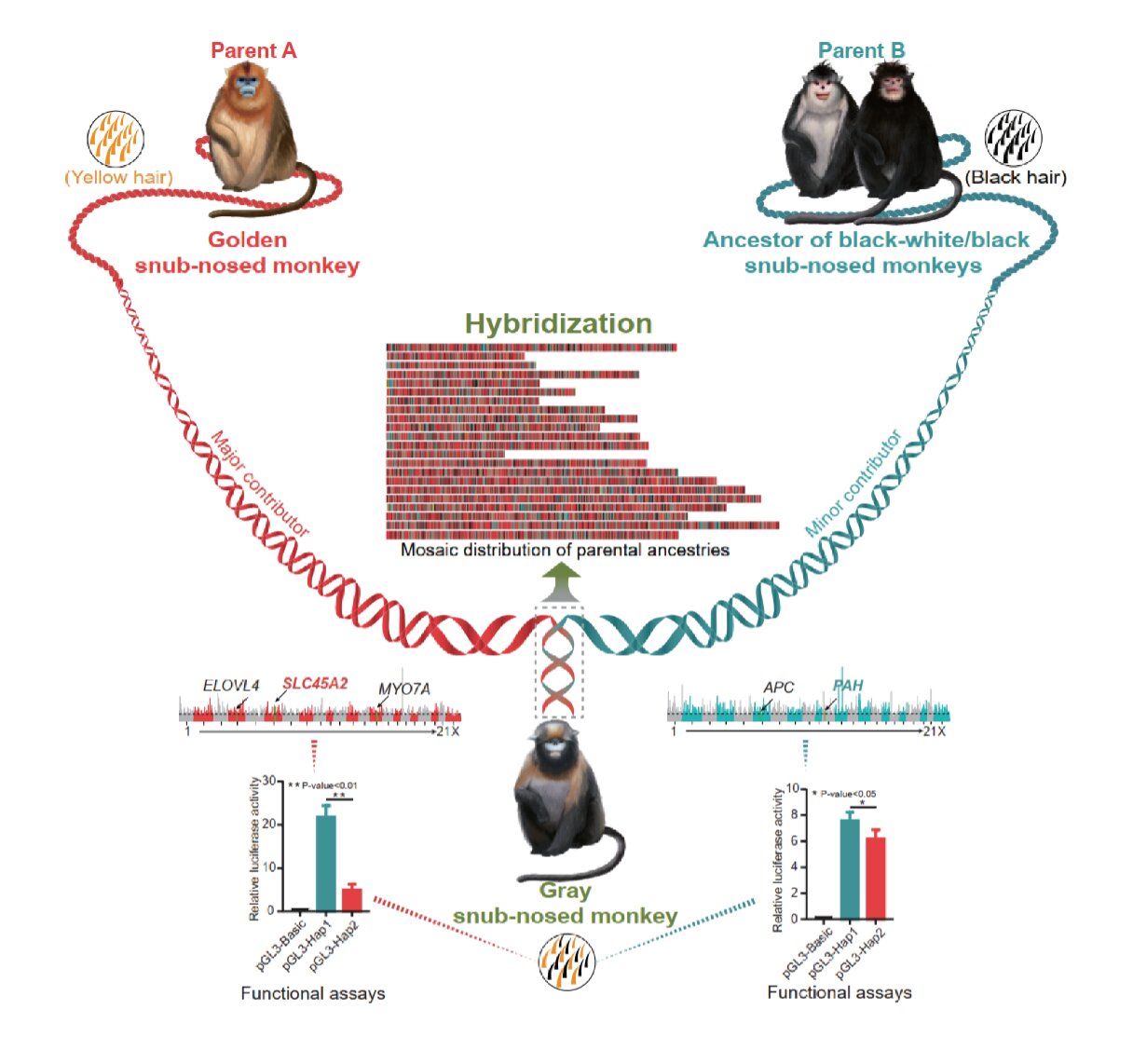
身為不同演化支系合體的產物,黔金絲猴的毛色也混合兩邊的風格。頭和肩膀的淺色,類似川金絲猴;手腳的深色,則類似滇、緬甸金絲猴。
基因組合體以後,兼具兩群影響毛色的基因,形成混合的毛色搭配。圖/參考資料1 金絲猴毛的顏色深淺,取決於不同色素的相對比例。棕黑色素(pheomelanin)愈高,毛色愈淡;真黑素(eumelanin)愈高,毛色愈深。例如猴毛中含有大量棕黑色素、少量真黑素,便會呈現金毛。
很多基因有機會影響色素與毛色。分析得知金絲猴們有 5 個基因和毛色關係密切,黔金絲猴的基因組來自兩個支系,比對發現,三個基因 SLC45A2 、MYO7A 、ELOVL4 繼承自川金絲猴,兩個基因 PAH 、APC 則源於滇、緬甸金絲猴。
這些基因如何影響毛色,仍有許多不明朗之處。最明確知道的是,SLC45A2 基因表現降低,會使得棕黑色素產量上升,令顏色變淡。PAH 基因表現增加,可以讓顏色加深。
同一隻金絲猴不同部位的細胞,同一批基因經由不同調控,就能控制毛色深淺。
這篇文章介紹的演化基因體學分析手法,對許多人大概不算容易,但是這些研究帶來的趣味,倒是不難體會。
延伸閱讀
參考資料
Wu, H., Wang, Z., Zhang, Y., Frantz, L., Roos, C., Irwin, D. M., … & Yu, L. (2023). Hybrid origin of a primate, the gray snub-nosed monkey. Science, 380(6648), eabl4997. The Primate Genome Project unlocks hidden secrets of primate evolution Biggest ever study of primate genomes has surprises for humanity Hundreds of new primate genomes offer window into human health—and our past van der Valk, T., Pečnerová, P., Díez-del-Molino, D., Bergström, A., Oppenheimer, J., Hartmann, S., … & Dalén, L. (2021). Million-year-old DNA sheds light on the genomic history of mammoths. Nature, 591(7849), 265-269. 本文亦刊載於作者部落格 《盲眼的尼安德塔石匠》 暨其 facebook 同名專頁 。