作者︱黎偉健
2012 年 7 月 4 日,位於歐洲核子研究中心(CERN)的大型強子對撞機(Large Hadron Collider(LHC))的 ATLAS 和 CMS 實驗團隊宣佈了希格斯玻色子的發現,轟動了整個物理學界。提出希格斯玻色子的希格斯(P. Higgs)、恩格勒(F. Englert)和布勞特(R. Brout)迅速在翌年獲頒諾貝爾物理學獎。
在粒子物理的標準模型裡,希格斯玻色子關係到基本粒子質量的來源,具有重大意義。此外,由於希格斯玻色子很可能與一些未知的物理有關,以後對該粒子的進一步研究很可能有助解開現今物理學的一些謎團。藉著希格斯玻色子發現十週年,讓我們回顧一下希格斯玻色子的研究在過去十年的進展,並前瞻未來對它的更深入探測與其蘊含的意義。
粒子物理標準模型 現代物理學的一項輝煌成就,是認識到物質皆由基本粒子(elementary particle)組成,而一切已知的物理現象可歸結為基本粒子之間基本交互作用(fundamental interaction)的結果。例如水,它由水分子組成,而水分子由氫原子和氧原子組成;原子則由電子和原子核組成,而原子核由質子和中子組成;質子和中子則由夸克組成。
從此可見,電子和夸克組成了我們日常接觸到的所有物質。它們是「基本」粒子,因為至今物理學家並未發現到它們有內在結構。基於夸克之間存在強交互作用,夸克能組成質子和中子,質子和中子能組成原子核;基於電子和夸克之間存在電磁交互作用,電子和原子核能組成原子,原子能組成分子。
基本交互作用有四種:重力交互作用(gravitational interaction)、電磁交互作用(electromagnetic interaction)、強交互作用(strong interaction)和弱交互作用(weak interaction)。重力交互作用即萬有引力,它主宰著如星體的形成及運行等天文尺度的物理現象,由廣義相對論描述【註 1】;電磁交互作用、強交互作用和弱交互作用主宰著微觀世界的物理現象,由粒子物理的標準模型(Standard Model)描述。
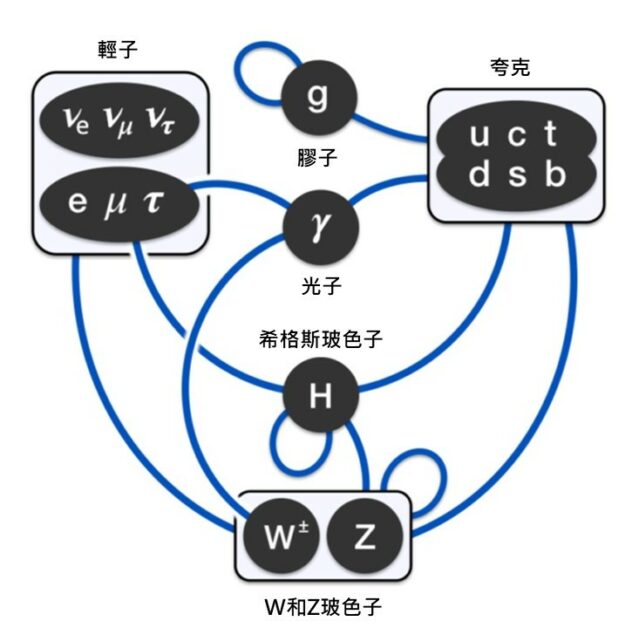
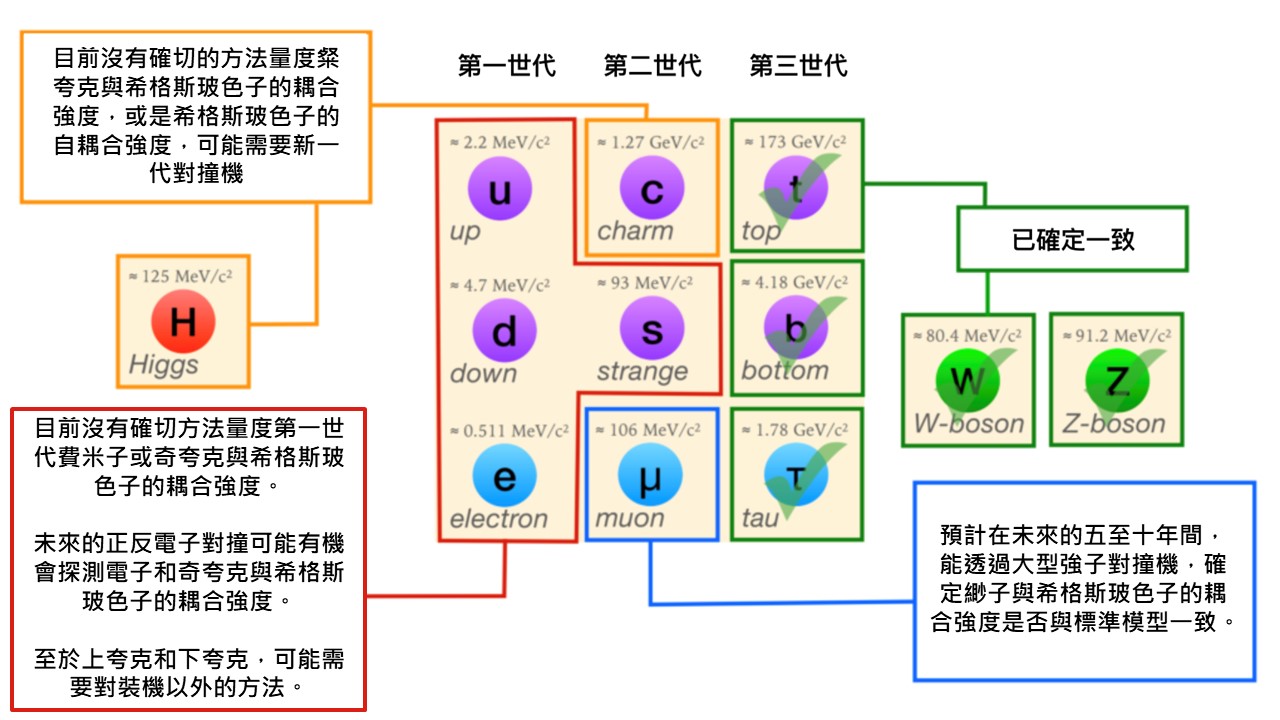
圖一:標準模型中的基本粒子。 圖一列出了標準模型中的基本粒子,它們分為三類:費米子(fermion)、規範玻色子(gauge boson)和希格斯玻色子(Higgs boson)。費米子分為兩種:夸克(quark)和輕子(lepton),有三個世代(圖一中左邊的首三列)。第一世代的費米子為最常見,上夸克、下夸克和電子組成了原子,從而組成了我們日常接觸到的物質。規範玻色子是傳遞基本交互作用的粒子,其中光子傳遞電磁交互作用,W 和 Z 玻色子傳遞弱交互作用,膠子傳遞強交互作用。希格斯玻色子是希格斯場(Higgs field)的激發。希格斯場與其他粒子的交互作用使得這些粒子具有質量,而希格斯玻色子會與帶有質量的基本粒子發生直接交互作用。
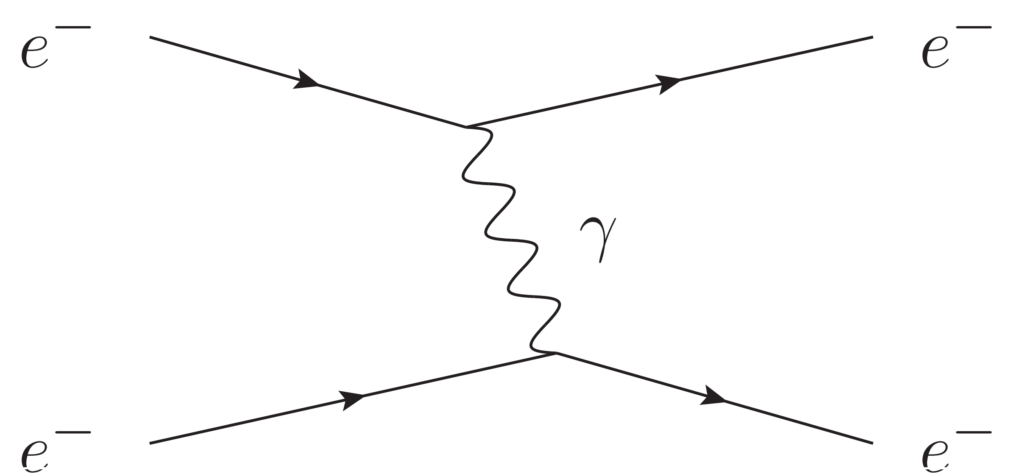
圖二:基本粒子的交互作用。 圖二顯示了標準模型中基本粒子的直接交互作用情況,其中藍線兩端的粒子會發生直接交互作用。例如光子(γ )和電子(e– ),它們之間有一藍線連接,即具有直接交互作用。粒子之間的交互作用可以形像地用費曼圖(Feynman diagram)表示。例如電子和電子之間的靜電排斥現象,可看作散射過程 e – e – →e – e – ,其費曼圖如圖三,其中縱向代表空間,横向代表時間,時間流逝方向從左到右,左端為初態,右端為終態,實綫代表電子,波浪綫代表光子,而綫的交點(稱為頂點(vertex),圖中有兩個)代表電子和光子之間的直接交互作用。直接交互作用顯示為一頂點,即交互作用發生在某時空點上。
圖三:以費曼圖表示電子之間的靜電排斥現象。 根據圖三的圖像,我們可以把電子和電子之間的遙距靜電排斥現象理解為一顆電子釋放出一顆光子,然後該顆光子被另一顆電子吸收,從中光子把能量和動量從一顆電子攜帶到另一顆電子,因此我們說光子傳遞電磁交互作用;這好比兩個籃球員在傳球,籃球員是電子,籃球是光子,而籃球員在拋球和接球時之所以感受到對籃球施了力,正是因為籃球傳遞了動量。
從這角度看,世上並沒有遙距的力,一切基本交互作用都發生在某時空點上,即費曼圖中的頂點。這種交互作用的局域性(locality)是現代粒子物理學的特點,它是狹義相對論和量子力學結合——量子場論 ——的結果。類似地,圖二中的每條藍線都有對應的費曼圖頂點。
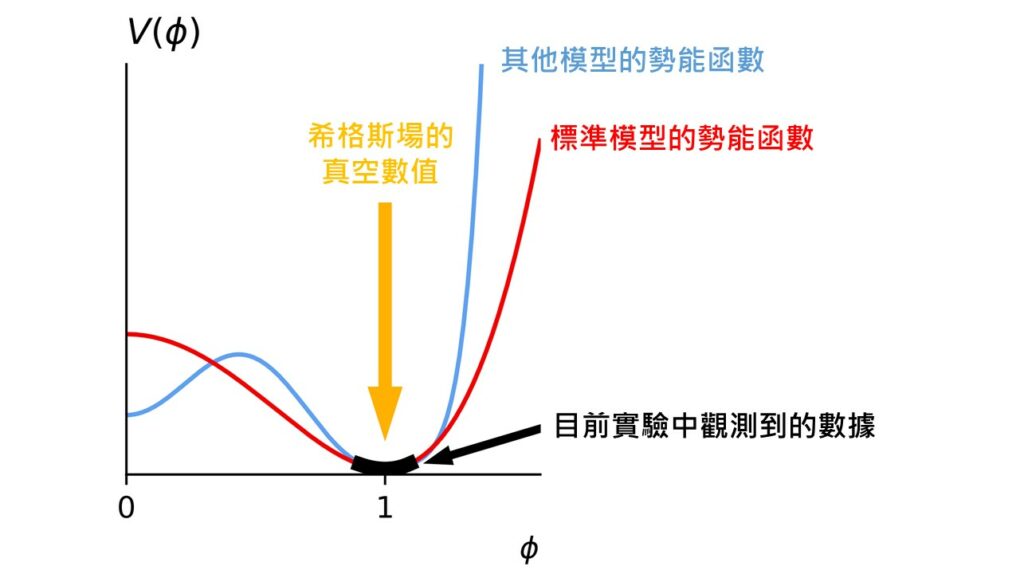
希格斯場與希格斯玻色子 根據量子場論,粒子是場的激發。這就是為什麼每顆電子都相同,因為它們都是同一個場——電子場——的激發。在量子場論中,真空被定義為能量最低的態。對於一般的場,它的值在真空中為零。例如,由於電磁場由光子組成,帶正能量,因此電磁場非零的態能量必定比電磁場為零的態高,所以真空中電磁場必為零。希格斯場則不同,它在真空中的值由一個勢能函數取極小值決定,該勢能函數對希格斯場 ϕ 的依賴形式如圖四中的紅線。
圖四:勢能函數 V(ϕ)對希格斯場 ϕ 的依賴形式,黑色粗體的區段是我們目前能觀測到的,紅線為標準模型的預言,藍線是某個其他模型的預言。(本圖出自參考文獻1) 從圖四可見,勢能在希格斯場為一非零值時取最小值,即希格斯場的真空期望值(vacuum expectation value(vev))為非零【註 2】。也就是說,真空中充滿著希格斯場,而任何粒子在任何地方任何時間原則上都有可能與其發生交互作用。
在標準模型裡,只有特定幾種粒子能與希格斯場發生交互作用。這些粒子包括夸克、帶電輕子(e – , μ – ,τ – )以及 W 和 Z 玻色子。這些粒子因為與真空中的希格斯場發生交互作用,從而獲得質量。對於這些粒子,它們與希格斯場的耦合強度與它們自身的質量成正比。所謂的希格斯玻色子,其實就是希格斯場在其真空值背景上的激發。
因此,只有帶質量的粒子才能與希格斯玻色子發生直接交互作用(如圖二中與希格斯玻色子有藍線連結的粒子),而這些粒子與希格斯玻色子的耦合強度也正比於他們自身的質量【註 3】。值得注意的是,希格斯玻色子能與自身發生直接交互作用(見圖二)。
基本粒子的質量直接影響著宇宙中物質存在的形式。例如,我們知道,上夸克比下夸克輕,而質子由兩顆上夸克和一顆下夸克組成,中子則由一顆上夸克和兩顆下夸克組成【註 4】,因此質子比中子輕,從而質子是穩定粒子,這使得氫原子的組成變成可能。如果下夸克比上夸克輕,那麼質子會衰變成中子,即氫原子不穩定,宇宙便不可以如已知的含大量氫。又例如,原子的大小與電子的質量成反比,而原子的能階與電子的質量成正比,因此電子的質量直接影響著物質的化學特性。再例如,太陽中心核反應的其中一環取決於弱交互作用,其發生的機率正比於 1/m w 4 ,其中 m w 為 W 玻色子的質量。可見,希格斯場作為基本粒子質量之源,對物質的存在形式扮演著決定性角色。
希格斯玻色子於 2012 年在位於歐洲核子研究中心(CERN)的大型強子對撞機(LHC)中被發現,是標準模型中最後一顆被發現的基本粒子。
對希格斯玻色子的最新認識 我們對希格斯玻色子的認識源自大型強子對撞機(LHC)的實驗數據。在 LHC 中,兩束質子互相對撞,質子裡的夸克或膠子會發生散射,有可能從中產生希格斯玻色子。由於希格斯坡色子的壽命很短,只有约 10 -22 s 秒,被產生的希格斯玻色子在到達粒子探測器前已衰變成較穩定的粒子。
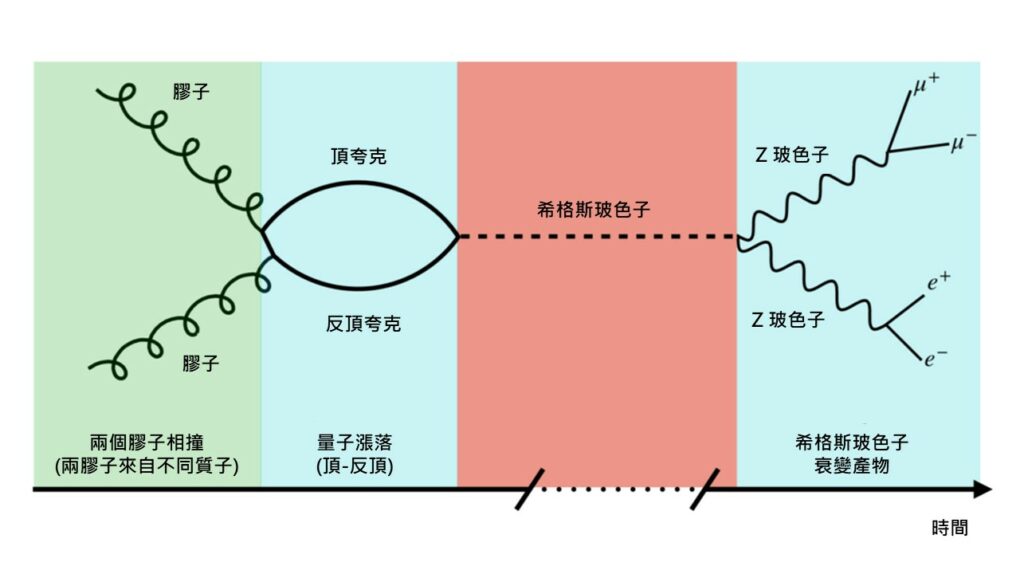
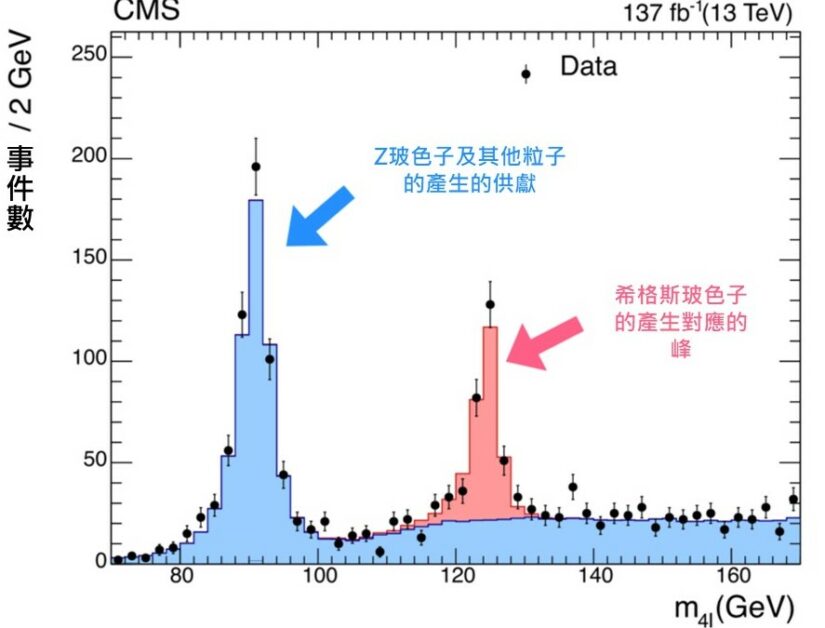
圖五 a:LHC 中產生希格斯玻色子的典型過程費曼圖 (本圖出自參考文獻1) 圖五 a 顯示了一個 LHC 中產生希格斯玻色子的典型過程的費曼圖。該過程的初態是兩顆來自質子的膠子(gluon),這兩顆膠子互相碰撞,產生了一對正反頂夸克,而由於頂夸克質量很大,從而與希格斯玻色子的耦合也很大,因而很有可能產生一顆希格斯玻色子,而該顆希格斯玻色子稍後衰變成兩顆 Z 玻色子,而這兩顆 Z 玻色子又各自衰變成一對正反帶電輕子(e + e – 或 μ + μ – ),粒子探測器會探測到終態的四顆帶電輕子。
圖五 b:實驗中探測到的四顆帶電輕子的質心系總能量 m4l 分佈。(本圖出自參考文獻1) 圖五 b 顯示了實驗中探測到的四顆帶電輕子的質心系總能量 m4l 分佈。藍色的部分顯示了非希格斯玻色子產生過程的供獻,而紅色部分即為產生希格斯玻色子所致,其峰位於希格斯玻色子的質量(125 GeV)。
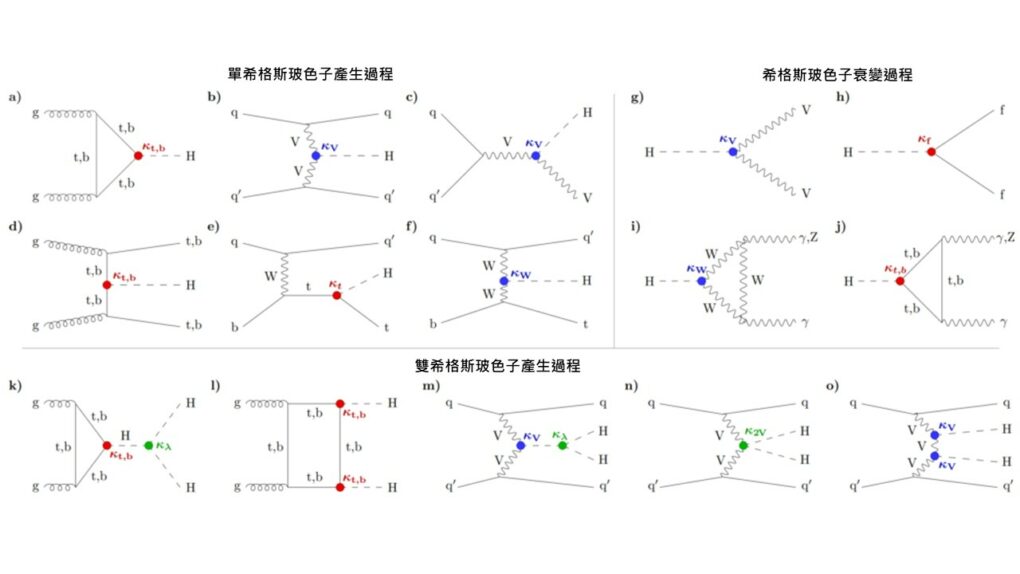
當然,在 LHC 中,希格斯玻色子的產生和衰變不是只有如圖五 a 的過程,所有可能的產生和衰變過程的費曼圖如圖六。
圖六:希格斯玻色子在LHC實驗中的產生和衰變過程。 (本圖出自參考文獻 3) 在圖六中,(a)至(f)是產生一顆希格斯玻色子的過程,(g)至(j)是希格斯玻色子的衰變模式,(k)至 (o)是產生兩顆希格斯玻色子的過程。在這些圖中,粒子的記號如圖一,而 q 代表夸克,V 代表 W 或 Z,f 則代表質量非零的費米子,粒子 X 與希格斯玻色子的歸一化耦合強度記為 κ X 【註 5】(標準模型對應 κ =1)。值得注意的是,希格斯玻色子可以透過因量子漲落而產生的粒子迴圈與質量為零的膠子和光子發生間接交互作用(見圖六(a)、(i)和 (j))。產生過程(a)至(d)以及衰變過程(g)至(j)都已被實驗證實。我們可以從這些眾多的過程所獲得的數據推斷出粒子與希格斯玻色子的歸一化耦合強度 κ 。
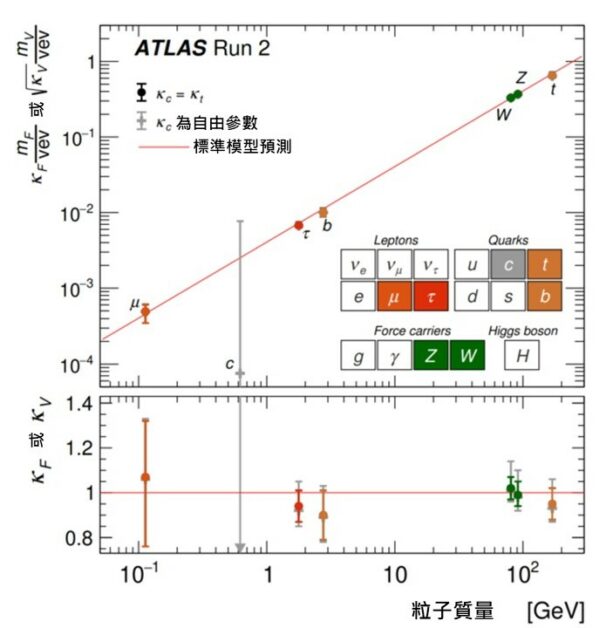
圖七 a:從實驗數據中得到的 κ 值,紅色直線代表標準模型的預測值。(本圖出自參考文獻2) 圖七 a 中的點顯示了從實驗數據中抽取出來的 κ 的值,紅色直線則表示了標準模型的預測。從圖可見,對於 W 玻色子、Z 玻色子、頂夸克(t )、底夸克 (b )和濤子(τ– ),它們與希格斯玻色子的耦合強度已被精確量度,並且其值與標準模型預測一致。
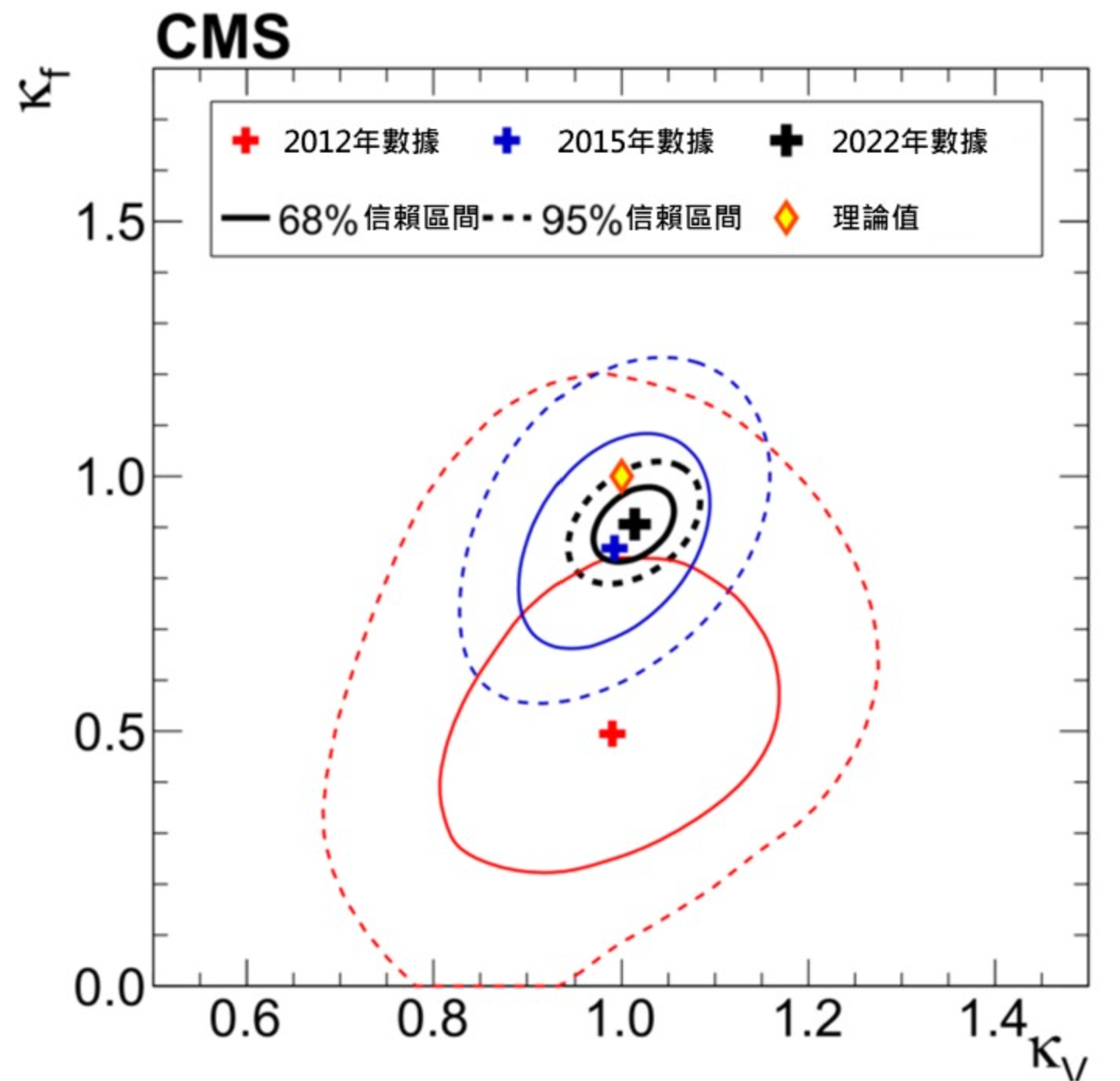
圖七 b:κf 和 κV 的量度精確度,中間黃色菱形為標準模型的預測值,越靠近黃色菱形表示實驗數據越符合理論值。(本圖出自參考文獻3) 圖七 b 顯示了 κ f 和 κV 的量度精確度在過去十年內的改善。紅色的圈表示 2012 年剛發現希格斯玻色子時的數據,藍色表示至 2015 年的數據,而黑色表示至 2018 年的數據。從圖可見,耦合強度的精確度在過往十年被大幅改善,並且其值與標準模型預測(κ =1)一致。
未來對希格斯玻色子的探測 圖八:基本粒子與希格斯玻色子的耦合强度量度進度及未來展望。(本圖出自參考文獻1) 圖八總結了至今對不同基本粒子與希格斯玻色子的耦合強度的量度進度以及未來展望。正如以上所述,我們已確定 W 、Z 玻色子,以及第三世代費米子與希格斯玻色子的耦合強度與標準模型一致。對於第二世代費米子,由於它們比第三世代費米子輕很多,因此與希格斯玻色子的耦合強度也小很多,所需的數據也多很多。
對於緲子,我們預計在未來五至十年間能確定它與希格斯玻色子的耦合強度是否與標準模型一致。在將來 15 至 20 年間,在升級後的高亮度 LHC(HL-LHC)中,圖六中未被觀察到的過程都會被觀察到,如同時兩顆希格斯玻色子的產生。可是,這都不足以測量出希格斯玻色子的自耦合強度。要量度魅夸克與希格斯玻色子的耦合強度,或希格斯玻色子的自耦合強度,我們需要 LHC 以外的新一代對撞機。
對於奇夸克和第一世代夸克,由於它們非常輕,現時並沒有確切方法探測它們與希格斯玻色子的耦合強度。未來的正反電子對撞機或有機會探測到電子和奇夸克與希格斯玻色子的耦合強度。對於上夸克和下夸克,我們可能需要對撞機以外的方法,如對原子物理的精確量度,但這都只處於討論階段。
有助解開的物理學謎團 我們對希格斯玻色子的進一步認識很可能有助解開一些現今粒子物理學和宇宙學的謎團,這些未解問題可大概歸為以下五個主要問題:
1. 層級問題 在標準模型裡,弱交互作用比重力交互作用強 1032 倍。為何重力這麼弱?這問題稱為層級問題(hierarchy problem)【註 6】。基於重力如此弱的事實,可以在理論上證明,如果在弱電尺度(~200 GeV)附近沒有標準模型以外的新物理的話,在未知的終極理論裡的基本參數須被準確微調至 32 個小數位。很多物理學家把這種基本參數的精確微調視為不自然,從而推斷在弱電尺度附近必定有新物理。
因此,林林總總的新物理理論被提出,如一派理論提出希格斯玻色子並非基本粒子,而是由更基本的粒子組成的複合粒子;另一派理論提出在高能量尺度下存在超對稱【註 7】;還有一派理論提出宇宙存在額外維度。希格斯玻色子的發現以及至今對它特性的量度,排除了很大部分這些新物理理論。現今的理論家提出新理論時需要更謹慎,使得新理論與有關於希格斯玻色子的實驗數據吻合。
2. 正反物質不對稱 在我們身處的宇宙中,物質都由正物質組成。可是,根據量子場論,一切粒子皆有其對應的反粒子【註 8】,而反粒子可組成反物質。那麼,為什麼宇宙中的物質只有正物質,沒有反物質呢?從理論推斷所知,在宇宙初期的高溫情況下,正反物質數量大致相同。現在我們所見到的正物質,是在宇宙因膨脹而冷卻後,正反物質互相湮滅後剩餘的。也就是說,宇宙很早期的時候正反物質數量存在些微不對稱,導致現今宇宙中只有正物質。
正反物質不對稱的大小依賴於宇宙早期弱電相變的細節。相變現象在日常隨處可見,如水蒸氣遇冷時凝結成液態水,或天然磁鐵遇熱時喪失磁性。在宇宙初期,溫度極高,希格斯場得到連續激烈的激發,因而其值不會停留在勢能(圖四)的最低點,而是作大幅度擺動,導致其平均值(即統計期望值)為零。隨著宇宙膨脹,溫度下降,希格斯場的擺動減小,直到某臨界溫度以下時,希格斯場的期望值取勢能的最小值處。希格斯場的期望值從零變為非零,這是一個相變過程,稱為弱電相變(electroweak phase transition)。
在標準模型裡,希格斯勢能導致的弱電相變為一連續相變(即所謂的二階相變),其結果是所造成的正反物質數量不對稱太小,不足以解釋所觀察到的不對稱值。因此,物理學家提出了一些新理論,這些理論涉及到新粒子的引入,而這些新引入的粒子會與希格斯場發生交互作用,從而改變希格斯場的勢能形式(如圖四中的藍線),使弱電相變變得不連續(一階相變),這也順帶的改變了希格斯玻色子的自耦合強度。所以,未來實驗對希格斯玻色子的自耦合強度的量度將有助解開正反物質不對稱之謎。
3. 暗物質 我們從天文觀察中得知,宇宙中存在著大量暗物質,其總質量約為普通物質的五倍。可以肯定,暗物質並非由標準模型粒子組成。因此,很多新的粒子理論被提出,當中引入了新的粒子。一個很自然的問題是,既然希格斯場負責給予標準模型粒子質量,它會不會也負責給予暗物質粒子質量呢?如果真的是這樣,那麼這些新的粒子會以量子迴圈的方式改變希格斯玻色子的壽命和自耦合強度,或者希格斯玻色子會衰變成這些新粒子,而這些都有機會在未來被測量到。
4. 費米子質量問題 在標準模型裡,費米子分為三個世代,三個世代的質量截然不同:第二世代比第一世代重,而第三世代比第二世代重(見圖一)。標準模型並不能對此作解釋。為此,物理學家提出一些新理論,而在這些新理論中希格斯玻色子具有一些標準模型不允許的衰變模式,如 H →μ + τ – 。如果這些新的希格斯玻色子衰變模式存在的話,有可能在未來被實驗探測到。
此外,在標準模型裡,微中子沒有質量。可是,我們從近年的微中子振蕩實驗中得知,微中子具有微小質量。希格斯場有可能在賦予微中子質量上扮演重要各式。
5. 宇宙暴脹之源 我知道,希格斯場的真空期望值取決於它的勢能形式,這是希格斯場與其他場截然不同的特點。有趣的是,根據現時所知的希格斯玻色子質量,我們可以推斷現今的希格斯場真空期望值只是勢能的局部最小值(又稱為錯真空(false vacuum)),而不是全局最小值(即真真空(true vacuum))。也就是說,我們所處於的真空並非最低能量態,而且不穩定,有機會衰變成更低能的最低能量態。
可是,這個錯真空衰變的機率極小,導致錯真空的壽命遠長於宇宙年齡,即我們所在的真空處於一種亞穩定狀態。我們知道,在宇宙的極早期曾經發生過暴脹,即宇宙以指數式急速膨脹,而這導致了現今宇宙在大尺度下的平均性。我們很自然會問,是甚麼導致暴脹呢?理論上,類似於希格斯場的錯真空衰變現象很可能就是暴脹的原因。究竟希格斯場與宇宙早期的暴脹有關嗎?物理學家對此仍未有答案。
結語 希格斯玻色子的發現為粒子物理學研究展開了新一頁。在希格斯玻色子被發現後的十年裡,透過在對撞機實驗中對它的深入探測,我們對希格斯場和希格斯玻色子有了更豐富的認識。至今,一切有關希格斯玻色子的量度均與標準模型預測一致。我們可以肯定的說,正如標準模型所述,希格斯場的確賦予質量給W、Z玻色子以及第三世代費米子。這證明宇宙中存在第五種基本交互作用——希格斯交互作用。在未來的實驗裡,對希格斯玻色子的進一步探測將有助解開一些未解決的物理學謎團。
註釋 對於基本粒子,電磁交互作用的強度約為重力交互作用的 1030 至 1043 倍。因此,在粒子物理裡,重力交互作用可以完全被忽略。 希格斯場能具有非零真空期望值,關鍵在於它的自旋為零,從而非零真空期望值不會與勞侖茲不變性抵觸。希格斯場取非零真空期望值,是一種自發規範對稱破缺,這使得 W 和 Z 既是傳遞交互作用的粒子,又帶有質量。這種賦予規範玻色子質量的機制稱為希格斯機制(Higgs mechanism),是弱電理論能成為一自恰理論的關鍵。 事實上,我們可以把希格斯玻色子與其他粒子的直接交互作用視為第五種基本交互作用,稱為希格斯交互作用,或湯川交互作用(Yukawa interaction)。 注意,質子和中子內除了夸克還有大量膠子,而質子和中子的質量絕大部分源於這些膠子的交互作用能,但這部分的貢獻在質子和中子裡是幾乎相等的。 歸一化耦合強度 κ 定義為耦合強度除以標準模型的耦合強度。因此,對於標準模型,歸一化耦合強度為 1。 關於層級問題是否一個合理的物理學問題,學術界仍存在爭論。 超對稱是一種理論上可能存在的時空對稱和內在對稱的混合,至今未被實驗發現。 反粒子與其對應的正粒子有相同質量和自旋,但帶相反的荷,如電荷。 參考文獻 G. P. Salam, L. T. Wang, and G. Zanderighi, Nature 607 (2022) 7917, 41-47 ATLAS Collaboration, Nature 607 (2022) 7917, 52-59 CMS Collaboration, Nature 607 (2022) 7917, 60-68