
本文轉載自顯微觀點
主持台大生醫光學實驗室的朱士維,在 2023 年初兼任台大學務長。他一面落實以學生為核心的大學價值,一面持續鑽研光學與生物組織、奈米結構的互動。
近年朱士維參與的研究包含觀察「活的小鼠大腦」如何自我調節、以光激發出奈米材料的新物理性質等。這些研究登上《自然通訊》(Nature Communication)、《先進科學》(Advanced Science)等重要期刊,以尖端光學技術為腦科學、奈米材料探照未知之處。
對於生醫領域的精密光學應用,朱士維說明,光學顯微技術介於醫學造影和電子顯微鏡之間:醫學造影提供即時成像,但解析度不夠精密。電子顯微鏡可以達到奈米解析度,卻無法保持樣本活性。而持續發展的光學顯微術則開始達成快速的高解析度活體影像,讓科學家看到真實生理。
活體顯微影像的追求不出四大方向:對比、解析度、穿透深度、速度。
– 朱士維
雙光子顯微術搭配人工智慧 追上神經生理
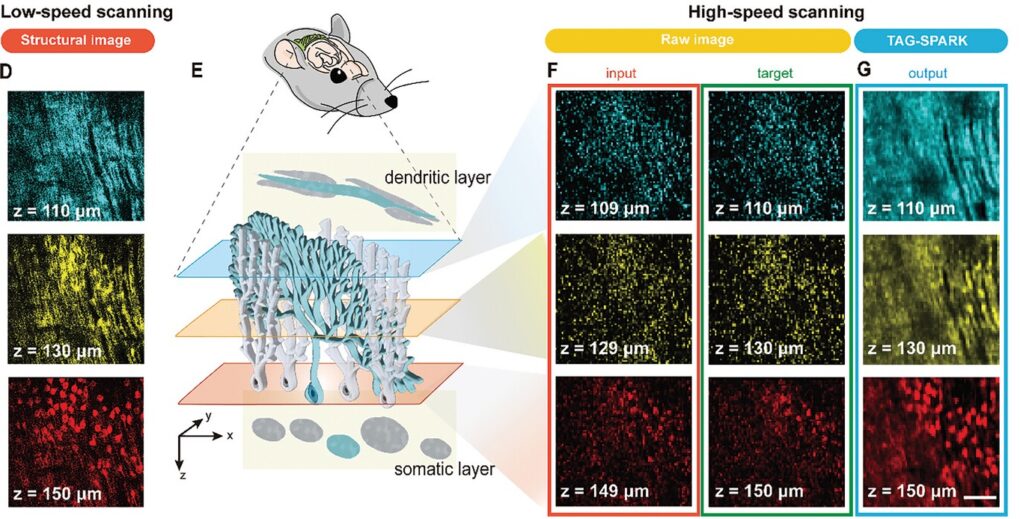
2024 年,朱士維領銜的台大、清大聯合團隊研發高速體積成像系統 TAG-SPARK (TAG-lens-based SPAtial redundancy-driven noise Reduction Kernel),以可調式聲學梯度變焦透鏡(Tunable Acoustic Gradient, TAG lens)結合自我監督式深度學習演算法,顯微影像成果比單用雙光子顯微術清晰 10 倍,掃描速度快上近 1000 倍。
TAG-SPARK 的聲學梯度變焦透鏡,以聲波控制特殊透鏡內的液體振動、改變折射率,使雙光子顯微光路可以在 1 秒內完成多個深度的對焦,快速建立 3D 影像。在高速體積成像的支援下,研究團隊設計的演算法利用每層平面影像間豐沛的空間冗餘(spatial redundancy)資訊進行去噪(noise reduction),讓影像訊噪比改善7倍以上。
 TAG-SPARK 以不同速度對活體小鼠的腦部進行鈣離子掃描成像,可以看見在不同深度的樹突、細胞體構造以及運作時的電位變化。來源/TAG-SPARK: Empowering High-Speed Volumetric Imaging With Deep Learning and Spatial Redundancy
TAG-SPARK 以不同速度對活體小鼠的腦部進行鈣離子掃描成像,可以看見在不同深度的樹突、細胞體構造以及運作時的電位變化。來源/TAG-SPARK: Empowering High-Speed Volumetric Imaging With Deep Learning and Spatial Redundancy
高速度和高品質的立體顯微影像,讓科學家以接近神經運作的速率,觀察活體小鼠的小腦動態。研究團隊以小腦中的柏金氏細胞(Purkinje cells)作為觀察目標,它們是小腦皮層唯一的輸出神經元,掌控小腦的訊號傳輸與身體日常運作。柏金氏神經細胞的樹突緻密分布於小腦皮質最外側的分子層(molecular layer),細胞體則聚集在更深處的分子層與顆粒細胞層(granule cell layer)之間,獨立形成柏金氏層。
傳統顯微方法不易穿透其深度觀察細胞體動態,若使用共軛焦顯微術,強力激發光卻容易傷害腦細胞。但雙光子顯微術在觀察活體組織時,則可以提供較深的焦平面和較低的光毒性。
透過 TAG-SPARK, 研究團隊不僅詳細記錄柏金氏細胞動態,更發現相同的樹突訊號能導致柏金氏細胞體產生不同反應,呈現前所未見的有趣訊號模式。朱士維相信「意識是資訊的集合」,高速立體光學成像系統能讓我們看見腦中資訊的聚散,更進一步接近「何謂意識」這個世紀之謎。
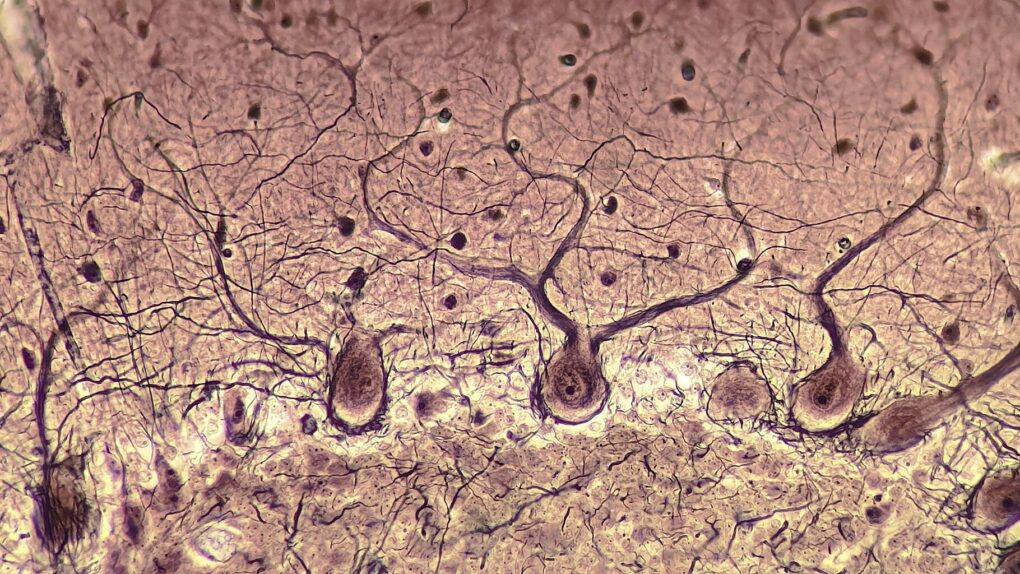
 柏金氏細胞卵狀的細胞體位於小腦皮層較深處,緻密的樹突則延伸至表面的分子層,因此要觀察其運作時的全貌,需要能夠快速地變換焦點深度。來源/Wikimedia
柏金氏細胞卵狀的細胞體位於小腦皮層較深處,緻密的樹突則延伸至表面的分子層,因此要觀察其運作時的全貌,需要能夠快速地變換焦點深度。來源/Wikimedia
朱士維也參與由台大生科系教授陳示國領導的跨校團隊,以雙光子顯微術結合梯度折射(Gradient-Index, GRIN, 物鏡內有不同折射率的微型透鏡平行排列)內視鏡,觀察小鼠的晝夜節律神經系統的真實運作狀況。
這支結合生命科學、物理以及工程科學的研究團隊測試大腦底部「視交叉上核」(suprachiasmatic nucleus,SCN)神經細胞對光線變化的反應。在團隊中,朱士維負責提供精密顯微影像,研究活體腦神經元生理不可或缺的觀察工具。
團隊利用朱士維研發的雙光子-GRIN顯微內視鏡(雙光子顯微術搭配GRIN內視鏡),從樹突叢集的鼠腦表層看進神經細胞體聚集處。他們發現,即使樹突受到相同光訊號刺激,節律神經細胞體可能以不同的方式回應,並由複數神經元整合資訊,再行輸出訊號給下游神經元。
研究團隊認為,在多種神經元的交織協力下,晝夜節律的神經生理呈現高度動態變化。神經細胞活動與光照的關係並非傳統想像的線性模式,而是雙穩態(bi-stability, 系統中有 2 個調節開關)的靈活調控,而單一類型神經細胞對光照的反應難以預測,生理時鐘內還有許多奧秘等待探索。
與跨領域學者合作,並非一帆風順。朱士維坦言,跨足生物學領域,他還有很多知識要補充、溝通門檻要跨越。
他笑稱,「光是合作對象經常討論的果蠅蕈狀體,我聽了 3 年才認為自己真的懂了。」對他來說,跨領域合作最重要的收穫之一,就是尊重不同領域之間的知識含量。其次,則是溝通的技術。
我維持了幾年的一知半解才了解合作對象的語言,那我務必要讓自己說出來的話非常容易理解。
– 朱士維
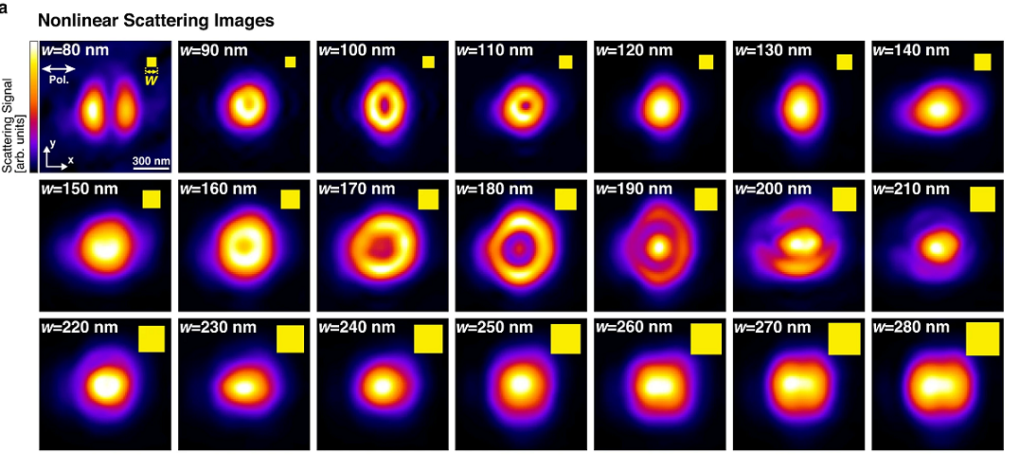
除了生醫應用,朱士維也在物理工程領域探索新的光學現象。他與中國、日本學者合作研究奈米材料上的非線性光學,發現與米氏散射原理相關的移位共振,能夠激發矽奈米結構的多極模態(multipolar modes)。
透過共軛焦反射顯微鏡光路達成的多極模態,讓奈米材料展現幾項嶄新的光學效應,如更低的光學非線性閾值、光開關的訊號反轉(sign flip)、空間解析度提升等。不僅開啟了操控米氏共振的新方法,也擴張了超過百年的經典光散射理論。
 以共軛焦顯微鏡觀察高強度雷射照射下的矽奈米立方體的非線性散射,上圖中矽立方體寬度為180奈米(中央圖)時,可以得到最強的移位共振效果。圖/Multipole engineering by displacement resonance: a new degree of freedom of Mie resonance.
以共軛焦顯微鏡觀察高強度雷射照射下的矽奈米立方體的非線性散射,上圖中矽立方體寬度為180奈米(中央圖)時,可以得到最強的移位共振效果。圖/Multipole engineering by displacement resonance: a new degree of freedom of Mie resonance.
這些精采研究涵蓋跨領域、跨國界的合作,並非巧合,而是出於朱士維的世界觀。他深信,「真實世界的所有問題,都是跨領域問題。」在大學教室裡,他也以此觀念為學生設定學習方向。
討論與實作優先的大學教育
在大一、大二的基礎課程中,朱士維就會要求學生提出研究計畫、動手進行研發。他強調,讓學生從具體而明確的問題出發,親手進行研究。在研究中遇到挑戰、企圖解決時,學生自然會尋找需要的知識。
朱士維回想,「修課學生果然從很務實的角度發想,有人的提案是『保證起床的鬧鐘』,結合物理知識和現實可行的元件,做出不會被輕易關掉的鬧鐘,讓他可以準時上課。他在學期末真的做出了這個鬧鐘。」
朱士維認為,在豐富的現代資訊環境中,幾乎所有理論知識都可以線上學習,在教室上實體課程的必要性遠不如以往。至於實體課程最珍貴的部份是讓人當面討論、激盪想法,讓積極學習的學生們能夠聚集、交流,而非要求學生安靜聽課、被動吸收。
朱士維相信,大學教育的重要目標之一,是訓練學生主動採取行動的習慣,並讓他們知道必須主動追求,才能完成自己心中的期待。因此親自規畫、動手(腳)實踐,是他所有課程的必備基礎。
除了物理系,朱士維也在臺大創新設計學院(College of Design and Innovation,簡稱 D-School)開設課程,引導學生以「設計師」、「使用者」觀點建構自己的大學生活與生涯規劃。
朱士維特別說明,D-School 設有創新領域學士學位學程,讓學生能夠跳脫舊有領域框架自訂學習主題。讓學生能實現自己對知識的構想,或許比舊有科系分野更能適應快速變化的社會。他強調,「學生原創的課程組合,是可以得到學士學位的。」
主修社團,副修電機
談及學習經驗,朱士維說,「我常常說自己大學主修『嚕啦啦社』,副修電機系。大學4年中至少有1年在山上過,成績排名也因此往往是後半段。」但他認為,自己重要的「能力」如溝通協調、事前規劃、親手解決問題的信念,都是在社團經歷中學到的。
朱士維回想,他在高中時參與了救國團服務隊舉辦的山區營隊,活動內容相當刻苦簡樸,但他十分羨慕服務隊成員們能住在優美山林間,心想「等我上大學,一定要成為其中一員。」
進入台大嚕啦啦社並擔任服務隊員後,朱士維不僅培養了在山野間帶隊行進的嚮導經驗,也經常為了團康活動面對群眾。他說,「服務員經常得一手掌握團隊氣氛,活動才會成功。」他回想,當年為了達到這樣的能力,投入許多時間認真練習,經過跌跌撞撞的多次嚐試,才塑造出自己的風格。
後來得到「優良導師」與多次「教學優良教師」獎項的朱士維分析,這種能力其實就是「溝通」。但是他當時並非盤算著,「有天我會成為教師,能把這種技巧發揮在教室裡。」而是對當下的任務很投入,進行一件自己真的很想做的事情,在過程中內化了這項能力。
做學術研究不可或缺的計畫書,我也是在社團學到怎麼寫的,因為當時想申請更多經費來辦活動。朱士維
 朱士維說自己「主修社團,副修電機」,但並非認為學業與成績不重要,而是希望學生投入當下自己真正想做的事情,不論是學術、社團或是其他事物,只要真心投入都會有所回報。攝影/楊雅棠
朱士維說自己「主修社團,副修電機」,但並非認為學業與成績不重要,而是希望學生投入當下自己真正想做的事情,不論是學術、社團或是其他事物,只要真心投入都會有所回報。攝影/楊雅棠
因為自身經歷,朱士維相信,讓學生能投入自己真的想做的事情,才能培養長期的能力與素養。為了帶給學生自由探索的時間與空間,朱士維也強力支持 D-School 中的「探索學習」計畫。
選擇「探索學習」的學生,不再受到學期學分下限要求,可以自行前往校園外進行探索,建構自己的志向與經驗。選擇此計畫的學生,有人加入 NGO、有人進入動物園與馬場實習,還有人搭乘無動力帆船橫跨大洋,獲得課堂中無法給予的重要體驗。
朱士維認為,親身體驗,遠比聽講的學習效果更好。而離開校園探索世界的深刻體驗,未必會讓人遠離學術。
提及學術起點,朱士維不好意思地說,當年之所以報考台大光電研究所,「是因為想要繼續參加社團,要是離開台大,社團生涯就結束了。」
研究所開學不久,921 大地震撼動台灣,中部災情尤其嚴重。朱士維聽聞大學時期經常前往、充滿熟悉與認同的南投山區也遭受重創,便和指導老師孫啟光請假,前往災區協助賑災。
朱士維回憶,孫啟光乾脆地答應他的請求,即使他離校超過一個月才回歸實驗室,也不曾額外施加壓力。經過了在南投山區鎮日搬運物資、不時目擊傷亡狀況的賑災經驗,他回到台大光電研究所時,同學們大多已在研究軌道上運作。
朱士維說,「當時我並沒有對研究成果想太多,而是想回報孫老師。因為他給我很大的彈性、研究主題又有趣,就專心投入他的計畫。想不到,幾個月後研究成果竟登上國際期刊。至今我還記得看到自己名列期刊之中的感動,也在那時開始覺得『我或許可以走學術這條路!』」
因為充滿因緣際會的生涯際遇,朱士維相信,「全心投入的事情,都會在生涯某處開花結果。比起嚴密生涯規畫更重要的,是當下的自己、周遭的人與環境,找到自己想投入的事情。」
從「好好生活」出發的學務長
一進入朱士維的學務長辦公室,能看到一幅對聯「好好生活。感恩助人」,書桌後方則並列三幅春聯「好好生活」、「好好吃飯」、「好好睡覺」。
朱士維說,學務處實際上掌管學生除了成績外的所有在校事務,而大學除了學業成績外,更應該協助學生培養人格和價值觀。因此,他將學務處設定為學生在校期間的支持與賦能來源。
 台大學務長辦公室中的朱士維。攝影/楊雅棠
台大學務長辦公室中的朱士維。攝影/楊雅棠
台大學務處網站上的理念「好好生活,吃飯睡覺運動交友;感恩助人,學生互助回饋社會。」就是朱士維為學務處設立的目標。他強調,將學生推向世界,能夠與自身、週遭人事物建立真實的連結,是比追求課業成績更優先的大學價值。
因此他規劃學務處擴改善硬體設施、增加軟體服務,從社團資源、宿舍、餐廳、心輔中心到新的經濟支持計畫,提供學生友善、包容的生活環境。他期待學生能夠在生活中感到安定,進而察覺值得感恩的事,得到感激並協助他人的能力,形成助人的循環。
朱士維回想,自己在台大的社團與求學經驗都讓他心懷感恩,包括在台大擔任教師也是非常幸運的事。現在,他致力為台大學生建立可以安心探索自我與真實世界的大學環境,以充滿感動的學習經驗,取代孤獨且競爭激烈的人生賽道。


 當造影、監視或刺激散射介質(scattering medium)中的樣本時,即使最強力的光學顯微鏡及探針也遭到擴散極限(diffusion limit)的阻礙,超出此極限的入射光會失控散射。為了克服上述極限,有些技術將通過樣本時的波陣面(wavefront)集中。其他技術則反複使光定形,來放大目標信號。
當造影、監視或刺激散射介質(scattering medium)中的樣本時,即使最強力的光學顯微鏡及探針也遭到擴散極限(diffusion limit)的阻礙,超出此極限的入射光會失控散射。為了克服上述極限,有些技術將通過樣本時的波陣面(wavefront)集中。其他技術則反複使光定形,來放大目標信號。






































.jpg){kind=link}