運用「經濟學」研究健保
中研院經濟所的楊子霆助研究員,分析實際資料發現:「免除三歲以下兒童的部分負擔」制度,會讓三歲以下兒童到大醫院看門診的次數大幅增加,而且新增加的門診大多是應在診所治療的輕症(如感冒)。這顯示調高部分負擔,將有助於抑制輕症病患到大醫院就醫次數,減少醫療資源的浪費。

大家都想知道健保制度好不好,但好或不好該如何證實?在平常觀看新聞的過程中,楊子霆發現衛服部於 2002 年推動「免除三歲以下兒童的部分負擔」制度,便運用健保資料分析這項政策的實際影響,也檢視健保制度能如何更好。
「免除三歲以下兒童的部分負擔」,發生了什麼改變?
「部分負擔」的意思是當大家就診時,除了由全民健保負擔醫療費用外,我們也需要自行負擔一部份費用。除了門診的部分負擔,藥品、復健治療及住院也都有部份負擔。

政府一直想了解「部分負擔」的變化如何影響「醫療利用」與「健康」,但如果直接比較部分負擔「付較多」與「付較少」的兩群人,他們在醫療利用與健康的差別,可能無法正確估計部分負擔的影響。因為這兩群人可能在家庭收入、先前的健康狀況、或其他特性本來就有不同,研究者無法斷定這兩群人在醫療利用與健康的差異,是來自部分負擔不同所造成的?還是其他因素導致的?
因此,為了正確估計部分負擔的效果,我們選擇從「免除三歲以下兒童的部分負擔」這個制度,來看部分負擔的變化如何影響兒童的醫療利用。我們用「滿三歲前一天」與「滿三歲後一天」的資料做比較,因為三歲前後幾天的健康狀況、家庭收入或是其他因素應該不會有太大差異。
三歲前一天與三歲後一天,唯一差別在於「是否需要付部分負擔」。因此,可以去看同一群人在兩種情況下,醫療利用行為有無改變、及健康狀況是否有差異,藉此就能估計部分負擔的效果。
我們研究結果發現,如果免除三歲以下兒童的部分負擔,「門診」的總醫療花費增加 7%,總就診次數則是增加 5% ,但家長大多是帶小孩去大醫院看小病。而「住院」則沒有明顯變化。
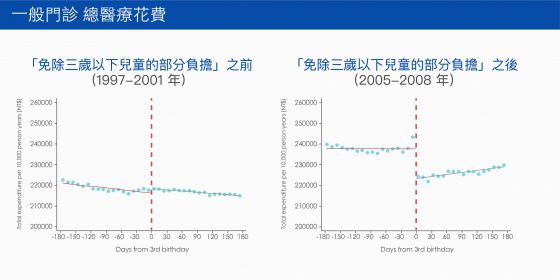
原本在大醫院看門診的部分負擔是比較高的,因此,免除部分負擔後,三歲以下兒童到大醫院看門診似乎更為划算:既能得到更多補貼(因為免除的部分負擔金額較高),又能獲得更好的醫療。我們發現到大醫院看門診的次數大約多了 50%~60%,而且新增加的大醫院門診,大多是可以在診所治療的小感冒等疾病。
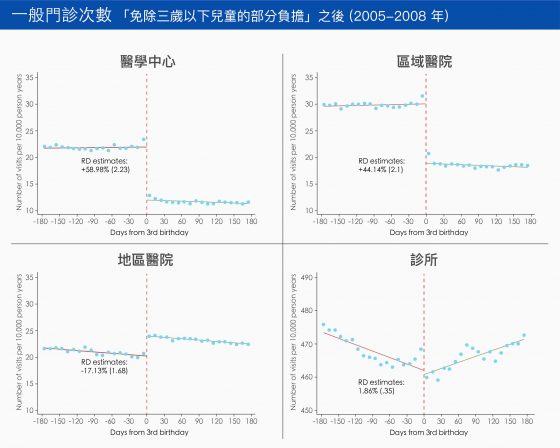
這個健保政策立意當然是好的,但從數據上來看,免除三歲以下兒童的部分負擔,似乎扭曲民眾就醫的選擇,增加他們直接到大醫院就醫的誘因。
比較好的方式是「定額補貼」,不分醫療院所的層級,皆補貼一個固定的費用。例如去診所或大醫院,門診都是補貼一百元,避免誘導民眾選擇大醫院。
三歲以下兒童「住院」,應免除部分負擔嗎?
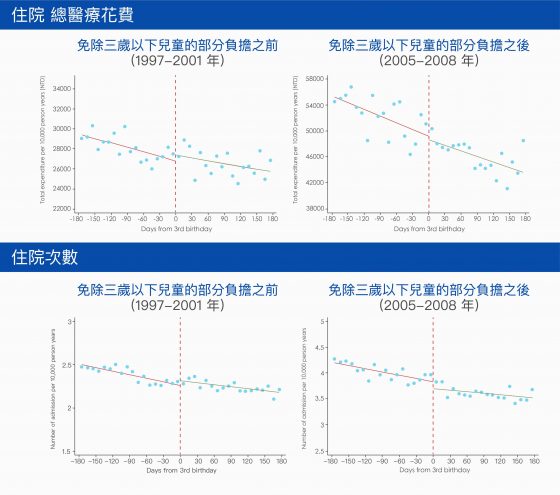
從我們的研究來看,如果幼童需要住院,無論是否有免除部分負擔,父母都會選擇讓他住院。這也是很合理的,因為幼童一旦需要住院,大多是要治療較重大的疾病,父母應該不會在意部分負擔是否免除。
因此,根據研究結果,如果政府想要繼續補貼三歲以下兒童的部分負擔,我們會建議:首先,「門診」的部分,應該用「定額」補貼部分負擔,才不會造成去大醫院得到的「補貼」比較多,反而變向鼓勵民眾多去大醫院就診。
其次,既然對重大疾病幼童來說「住院」是必要的,其決策不受部分負擔高低的影響。關於兒童住院的部份負擔,我們建議應該「全額補助」。
若門診不是用「定額」,而是以「定率」計算部分負擔?
但許多人認為現行的「定額部分負擔」做法仍無法抑制民眾小病到大醫院就診的情況,應按照《全民健康保險法》 第四十三條「保險對象應自行負擔門診或急診費用之 20% ,居家照護醫療費用之 5% 。但不經轉診,於地區醫院、區域醫院、醫學中心門診就醫者,應分別負擔其 30% 、 40% 及 50% 」之規範,以「固定比率(定率)」來收取部分負擔的費用。
改成上述「固定比率(定率)」的部分負擔,會更能降低輕症病患在大醫院的門診次數嗎?
根據我們的研究結果,我們並不贊同這樣的改法,因為現行的「定額部分負擔」大約能減少 50-60% 輕症在大醫院的門診量;換句話說,現行的「定額部分負擔」相當程度地能夠抑制到大醫院看小病的醫療浪費行為。事實上, 2017 年 4 月調漲前的醫學中心的部分負擔為 360 元,若是去看小病(例如感冒),那時的自付額已佔該次門診醫療支出的 75% ,遠高於「定率部分負擔」的 50% 。
若醫學中心部分負擔改為自付 50% 的醫療費用,反而會讓到醫學中心看輕症的自付額下降,可能導致民眾更愛選擇到大醫院看小病。
相反地,若是改成「定率部分負擔」,將會讓民眾不敢去大醫院治療「重大疾病」。
因為不像「定額部分負擔」,民眾能事先知道要付的金額,例如:一次醫學中心的門診就是付 420 元,在「定率部分負擔」下,民眾要等所有檢查做完,才知道自己要付多少錢;如果醫療費用是一萬元,要自行負擔 50% ,就是五千元,反而降低重大疾病的病患,到大醫院就醫的意願,然而這類病患才是大醫院應該治療的對象。
還有哪些感興趣的題目,卻因資料不足無法進行?
有的,但這個題目現在我也蒐集到比較多資料了。是關於台灣「人才外流」的議題。

我想知道甚麼類型的人會到海外工作,人才外流造成多少稅收損失、以及造成國內多少勞動力的短缺?光是想像就發現所需的資料量非常龐大:我要先知道他在台灣的工作與背景,再者是有多少人出國「工作」,這點就無法確定政府是否有準確的數據資料。
會有契機可以重新著手這個題目,是因為前行政院院長張善政的緣故,他在任內對「政府資料開放」抱持非常正面的態度,鼓勵各部會開放更多資料,也提供學術界申請政府行政資料 (administrative data)的機會。由研究團隊針對各部會的感興趣的議題,撰寫研究計劃書與提出所需資料,通過審核後,便可以至「國家高速網路與計算中心」的監控室使用資料。必須要強調這些資料都是經過「去識別化」,無法識別特定個人。
現在,我們申請到了研究所需的資料,不過,由於資料龐大,這些資料都還在處理中。無論如何,我非常高興能有機會探索這個重要議題。
台灣政府開放資料是否足夠?
近年來在張善政與唐鳳的推動下,台灣的開放資料確實進步很多。
除了開放資料外,有些政府行政資料對政策分析與學術研究也很有幫助。像衛福部就做得很好,願意釋出健保資料讓研究者到資料中心使用,健保資料非常地詳細,可以做出精確的分析結果,這在全世界非常少見。更重要的是,很少有國家強制全民納入健康保險制度,像是美國就沒有,所以無法取得全民的醫療健康紀錄資料。
政府手上有非常多很好的資料,研究這些議題需要資料,所以政府要先把這些資料開放出來,不然無法了解發生什麼事。
像健保資料只能得到醫療資訊,如果我想分析「收入」與「醫療利用」的關係,就還需要收入與家庭的資料,如果沒有跨部會資料的話,研究就無法進行、或可能結果不精確。
但目前台灣遇到的最大困難是:各部會的資料無法串聯在一起。各部會的本位主義有點強,如果要跨部會資料的串連,把資料放在哪裡也是一大問題。(冒汗)
我前陣子去瑞典參訪,觀察到他們將資料統一放在一個第三方獨立的機構:國家統計局。他們跟台灣一樣, 會給予每位國民類似身分證字號的代碼,並用這個代碼串聯各部會所屬的資料。
運用國家統計局擁有的整合資料,每年可以直接計算數據、發佈普查結果,取代了台灣還要人工額外進行的人口普查、勞動力調查、收支調查等。其實台灣政府做這些調查都是「重複的」調查,如果整合各部會現有的數據資料,反而可以省下更多行政成本。
延伸閱讀