

每天煩惱三餐要吃什麽、出門要怎麽穿、回家後有沒有舒適的被窩可以鑽,應該是我們大部分人的日常。然而,在社會的某些角落,「貧窮」卻可能讓人連基本生理需求都難以滿足。
要消除貧窮,免不了增加資源消耗,但全球暖化危機當前,人類又不得不展開節能減碳的行動。面對「對抗貧窮和調適氣候變遷,兩者是否相互衝突」的疑問,科學家們提出了一個直指核心的問題:我們需要多少能量,才能讓所有人過上體面的生活?
打造放諸四海皆準的人類基本福祉指標!
為了解答這個大哉問,來自國際應用系統分析研究所(IIASA)的研究者們,提出了一個新的指標——「體面生活標準」(Decent Living Standards,DLS )。它源自於基本人權與公平正義的普世理念,定義為任何人都應享有的一系列基礎物質與社會滿足要件;不論你出身何處、對好的生活有何想法,或擁有什麽訴求。
這些基礎條件,可以分為五大面向:營養(Nutrient)、庇護所(Shelter)、健康(Health)、社會互動(Socialization)及可移動性(Mobility)。在食衣住行方面,除了三餐溫飽及空間大小充裕的住處外,DLS 更貼心地考慮生活的細緻之處,例如乾淨的衛浴、可以烹飪、保存食物的基礎家電,以及高緯度地區在冬、夏兩季不可或缺的溫控設備等等。DLS 也不止步於基本物質需求,更涵括一個健全生活的人應享有的醫療服務、義務教育,使用基本通訊和交通設施,以及進行社交聯繫和政治參與的權利。

逐項列出統一化的 DLS 各面向的要求後,研究者們會根據不同國情,例如氣候、都市化程度、文化及科技經濟結構的程度,去計算各國達成這些基準的閾值能量。除了國與國的差異,在計算上,也會納入在地的城鄉差距。
舉例來説,訂定了擁有足夠空間和熱舒適的房屋通用標準後,研究者會把它換算成各地所用的不同建材,及建設與維持各類民生服務的基礎設施(如水電廠、運輸系統等)所需耗費的能量。有了 DLS 的理想標竿值,再與每個國家目前用於實現 DLS 的能源進行比較,就可估算出填補 DLS 缺口所需的能源需求。
為什麼要以「能量」衡量生活標準?
過去,我們總是以滿足生活標準的最低收入,來制定貧窮線的水平。但 DLS 作為最低限度理想生活的基準,採用的是計算能源消耗量(energy consumption)常用的單位,即千兆焦耳(Gigajoule,GJ)或十萬億焦耳(Exajoule,EJ)。一般國家的能源消耗量,都與基礎建設有關,大部分來自化學燃料的燃燒,以及水力發電、核電、風力發電、太陽能發電等。
值得注意的是,DLS 分析結果顯示,無法過上體面生活的人,數量遠比處在貧窮線底下的人來得多!這說明:現有衡量貧富的指標,跟實際情況是脫節的。以金錢收入作為生活水平的衡量單位,是預設個人能透過消費,去換取相應的生活品質。但現實中,有一大部分的人,即使收入高於貧窮門檻,現今社會所投入建設的能源,卻未必足以讓他們過上體面的生活。
因此比起以金錢為單位,DLS 由下而上(bottom-up)去推算建設和維持基本物質需求所耗費能量的模式,也許更適合作為反映人類生活品質的指標。以消耗能量為單位的 DLS 不只有物質條件,也納入社會層面的需求,因此可以為政策制定者在思考資源規劃時,提供更直接、全面的參考。
世界並不公平,尤其在所需耗費的能量上
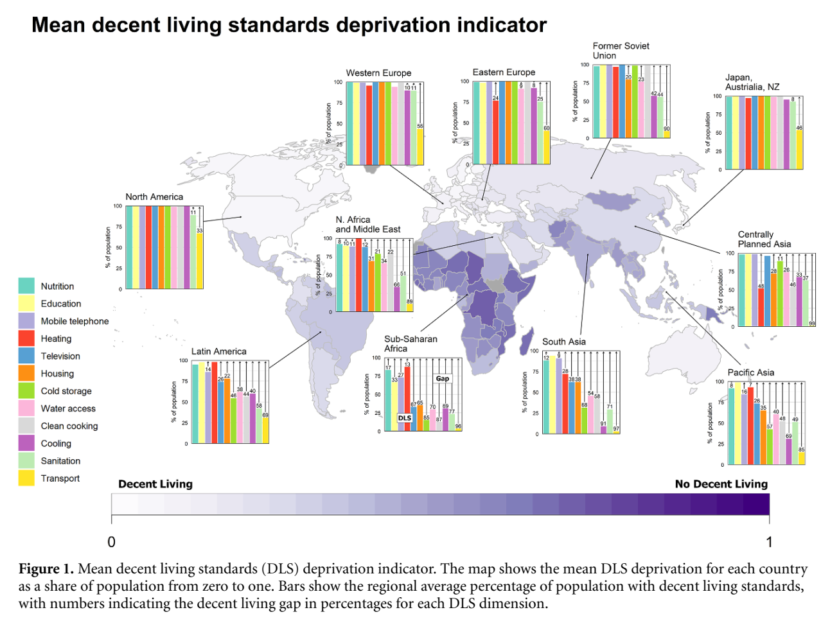
搭配各國戶口統計調查、世界銀行(World Bank)發展指標等數據,研究者推算出世界各國在不同面向上與 DLS 的差距。結果顯示,北半球的北美與歐洲,大部分人民都過著與 DLS 相距不遠的生活。然而,南方卻呈現截然不同的境況。
在撒哈拉以南的非洲國家,有超過 60% 的人口在居家、溫控、衛浴與飲用水設施上,都相當匱乏。部分南亞與太平洋地區也面臨類似困境,尤其缺少乾淨的保暖與烹飪設施。這與他們使用的傳統生質能源帶來的不良健康影響有關。此外,部分亞洲、中東、拉丁美洲地區,也存在不便取得飲用水和保暖設施等等的缺口。
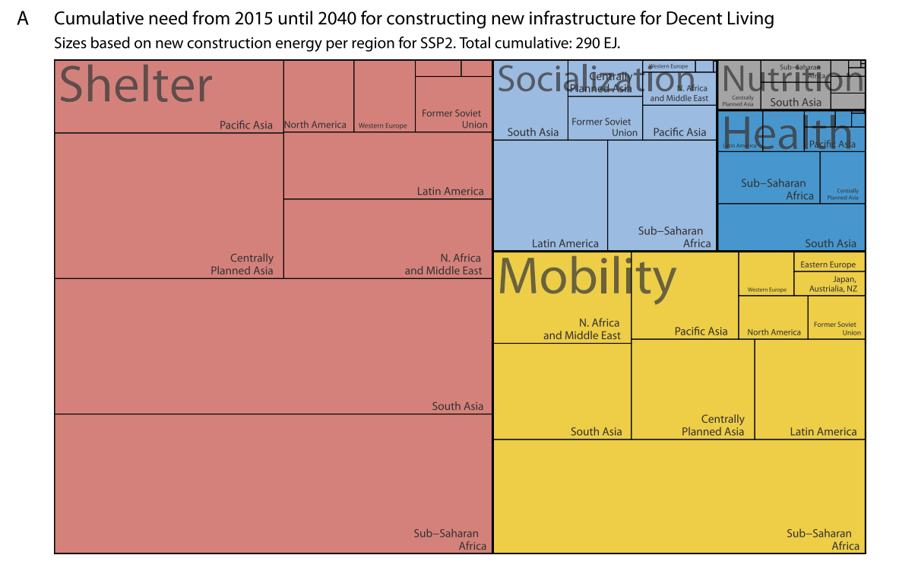
那麽,要投入資源做新建設,弭平當今與未來人口與 DLS 之間的距離,我們還需要多少能量呢?研究者設定情境估算,在 2040 年前,我們總共需要 290 EJ 的累積能量——大概是如今全世界每年所消耗能量的四分之三!是的,當今世界平均所消耗的能量,其實早已超過滿足每個人 DLS 的額度。在提升生活標準的耗能中,有大半會是拿來打造適宜的居所,四分之一用以建設以公共交通為主的交通設施,而改善健康營養所需的能量,會比推動社會互動來得少。
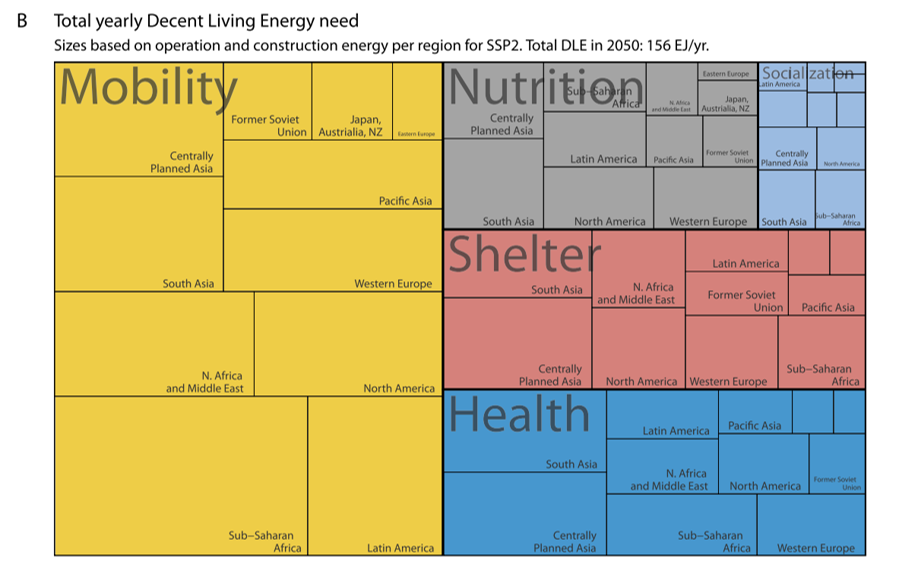
如果我們能成功在 2040 年時,讓所有人都達到 DLS,那在 2050 年時達到體面生活,最終需要年均 156 EJ 的能量,其中 108 EJ 會是供南方世界所用。到時候,人類生活的耗能大抵都會用在移動、通勤上,其次是維持健康及居住品質,而投入在維持社會互動所需的能量所占比例最低。
另一個研究的重要發現是,由於各地的氣候、文化和交通管道不同,即使在同一套 DLS 下,有些地區就是會比其他地區耗費更多能量,才能達到相同的基準,這個能量差異甚至可達 4 倍!例如,高緯度國家會需要耗費更多能量,來維持相同舒適的室内溫度;同樣的通勤距離,公共交通覆蓋率高的國家不需太多能量就能完成,但在個人擁車率高的地區,就會產生更多耗能。
結論:消除貧窮與對抗氣候變遷不衝突
總體而言,DLS 的研究結果,在貧富懸殊與氣候正義議題上提供了新的視野,告訴我們:投入消除貧窮的能量,並不會對調適氣候變遷的行動產生威脅。現今人類社會所產生的能量,其實大都挹注在讓原本就充裕的生活更好,而非幫助仍在體面生活基準下的人。因此,各國如何在經濟成長與耗能規劃上取捨,找出更公正、有效率的資源重分配方式,才是關鍵解決之道。
參考資料
- Decent living gaps and energy needs around the world
- Decent Living Standards: Material Prerequisites for Human Wellbeing
- Energy requirements for decent living in India, Brazil and South Africa
- 让全球老百姓过上体面生活不会拖累气候减排目标
- How much energy do we need to achieve a decent life for all?
- 維基百科:貧窮門檻





































#/media/File:Dune_(2021_film)_poster.jpg){kind=link}