本文轉載自中央研究院「研之有物」,為「中研院廣告」
- 採訪撰文|林庭葦
- 責任編輯|田偲妤
- 美術設計|蔡宛潔
上古中國最常見的武器是「戈」?
說到中國的兵器,你可能會想到金庸武俠小說中的倚天劍、屠龍刀。事實上,我們熟悉的劍是從歐亞草原傳入中國。早在劍成為主流兵器前,在上古中國的戰場上,廣泛使用的兵器是青銅製的「戈」。中央研究院「研之有物」專訪院內歷史語言研究所李修平助研究員,透過研究殷墟出土的「銅三角援戈」,分析這些兵器之於墓主的意義,並解開晚商社會與區域互動的謎團。
 中央研究院歷史語言研究所李修平助研究員,手上揮舞著仿銅戈模型,介紹源自上古中國的尖端兵器。
中央研究院歷史語言研究所李修平助研究員,手上揮舞著仿銅戈模型,介紹源自上古中國的尖端兵器。
圖|研之有物
在中央研究院歷史語言研究所的研究室裡,李修平助研究員揮舞著一把仿銅戈模型,一邊講解、一邊模擬商代士兵的作戰情形。
銅戈這類青銅器是用銅、錫、鉛為主的礦物冶煉鑄造而成,跟非金屬材料做的兵器截然不同。第一,銅戈相當鋒利,就算沒有正中敵人要害也會造成大量失血,攻擊效率極高。第二,石器要花時間打磨,但銅戈只要有夠多模具,就能大規模量產。第三,石器斷了就斷了,但銅戈就算鈍掉,磨一磨就能再用;就算爛掉,也能重鎔再製。
「銅戈彰顯了商代的軍事和科技實力,你不覺得這類兵器超猛的嗎!」李修平讚嘆古人的智慧,娓娓道來自己對銅戈與青銅器著迷的原因:
青銅器的鑄造技術就像當代的半導體,是上古中國最尖端的科技!
的確,與石器、玉器或陶器相比,青銅器的製造技術更複雜,從開採礦物、冶煉金屬,乃至鎔鑄器物,整套製程都需要高超的知識體系和工藝技術。
此外,李修平更從銅戈觀察到複雜的區域互動關係。目前,學界普遍認為「戈」是中國本土發展出的兵器,源自黃河流域,並往四周流傳。而青銅鑄造則是來自歐亞草原的外來技術,傳入中國後逐漸本土化,被用來製作各式禮、兵器,也包括銅戈。
根據目前的考古發現,在被視為「晚夏時期」的二里頭文化(西元前約 1750 至 1520 年)、「早商時期」的二里岡文化(西元前約 1510 至 1300 年)就已出土少量的銅戈。到了中、晚商時期,銅戈不僅大量出現於黃河中游的小屯文化(包括「花園莊期」與「殷墟文化」,西元前約 1320 至 1050 年),更散布於上古中國境內各地。不同地區銅戈的形制變化與出土脈絡,成為考古學家研究上古中國區域互動的重要材料。
 中央研究院歷史文物陳列館展出從殷商到東周時期的銅戈,從中可觀察銅戈形制的變化。到了西周中期以後,戈的形制逐漸固定,戈頭末端已普遍流行名為「胡」的延長設計,可增加鑽孔空間,方便穿繩將握柄牢牢綁在戈頭上。圖為東周的長胡戈。
中央研究院歷史文物陳列館展出從殷商到東周時期的銅戈,從中可觀察銅戈形制的變化。到了西周中期以後,戈的形制逐漸固定,戈頭末端已普遍流行名為「胡」的延長設計,可增加鑽孔空間,方便穿繩將握柄牢牢綁在戈頭上。圖為東周的長胡戈。
圖|研之有物(拍攝自中央研究院歷史語言研究所歷史文物陳列館)
考古學家如何還原文物身世?
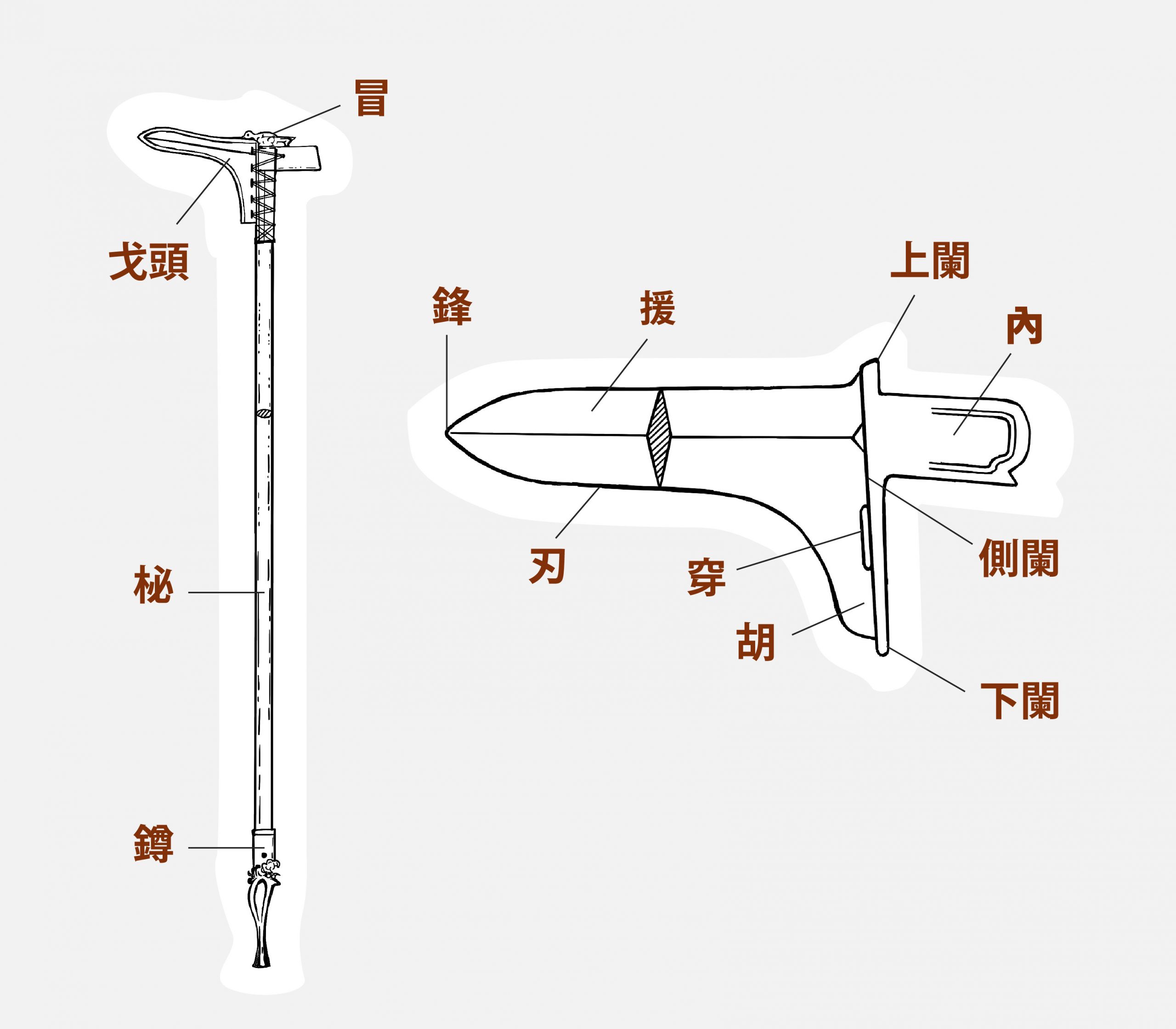
在殷商時期,銅戈已是中國廣為使用的兵器,一支銅戈基本上具備:青銅製的「戈頭」、固定戈頭並可手執的「柲」、柲上端的「冒」,與柲下端的「鐏」。
戈頭又可大致分為用來攻擊的「援」、支撐柲的「內」(常見的造型有直內、曲內、管銎),以及位於兩部位銜接處的「闌」(分為上闌、側闌、下闌)。
為了讓戈頭在作戰時不會從柲上脫落,會在「援」或「內」上設計稱為「穿」的孔洞,可穿繩將戈頭和柲綁在一起。後來更出現了合瓦形的「管銎」,是形狀如兩塊瓦片圍成的孔洞,可讓柲直接穿過戈頭固定。
 銅戈的「內」常見的造型有:直內、曲內、管銎。
銅戈的「內」常見的造型有:直內、曲內、管銎。
圖|研之有物(拍攝自中央研究院歷史語言研究所歷史文物陳列館)
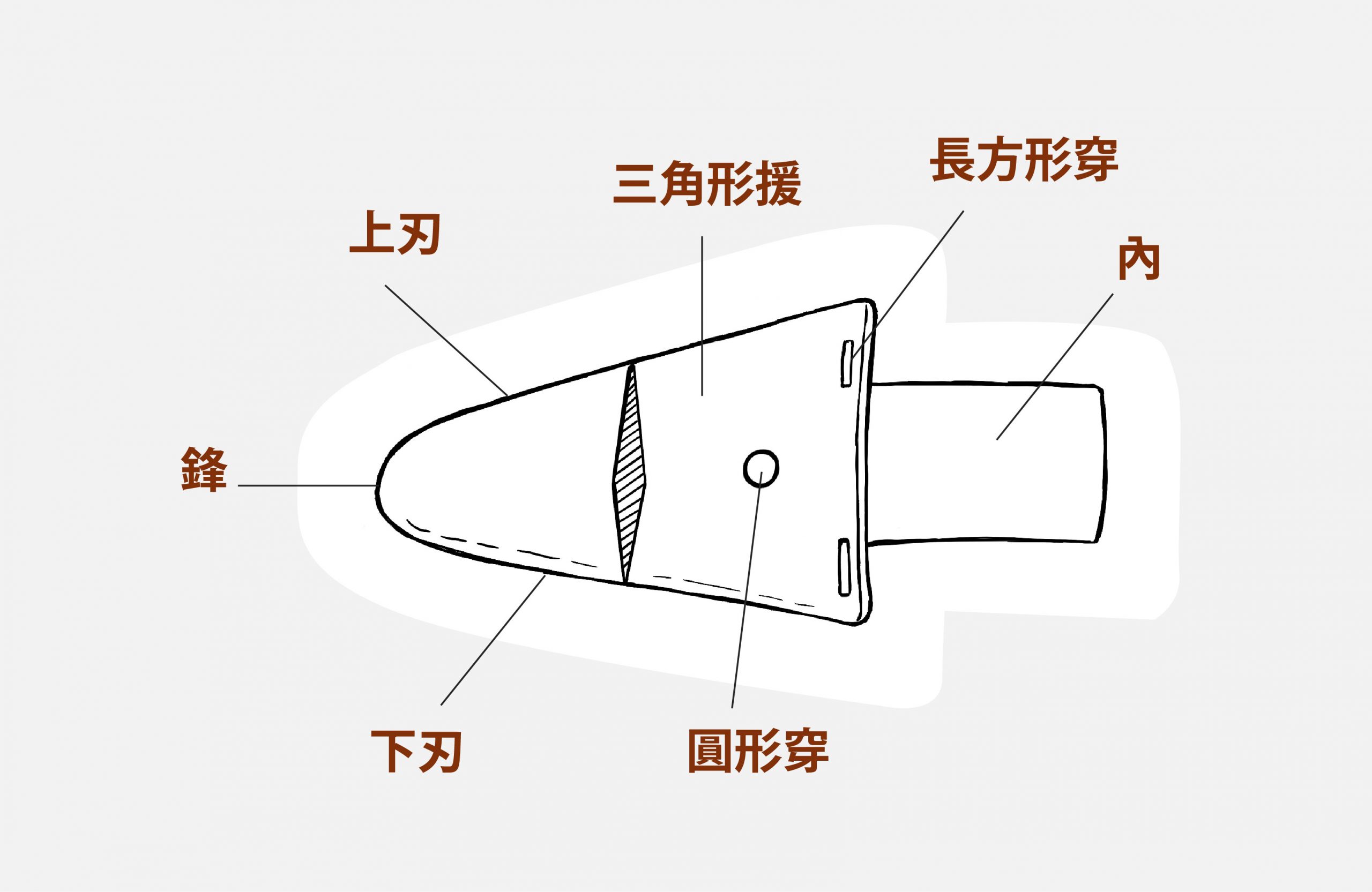
在形態各異的銅戈中,李修平注意到一種形狀特殊、數量稀少的「銅三角援戈」。與一般銅戈相比,銅三角援戈的主要特徵為:援呈三角形、援末有長方形穿、無上下闌。
銅三角援戈不僅造型特殊,更令人矚目的是,學者對於銅三角援戈的起源意見紛陳,目前至少包括「漢中盆地說」、「中原說」、「漢水流域說」與「涇渭三角地帶說」等不同說法。這也連帶影響其背後所反映的不同區域互動關係,形成眾說紛紜的局面。
根據目前的考古證據,在距今 3000 多年前的商代,銅三角援戈已見於上古中國各地,包括今日黃河流域的河南、河北、山東、山西、陝西,與長江流域的湖北、湖南與陝西南部等地。此外,殷墟所在的河南省安陽市,則出土近 20 件銅三角援戈。
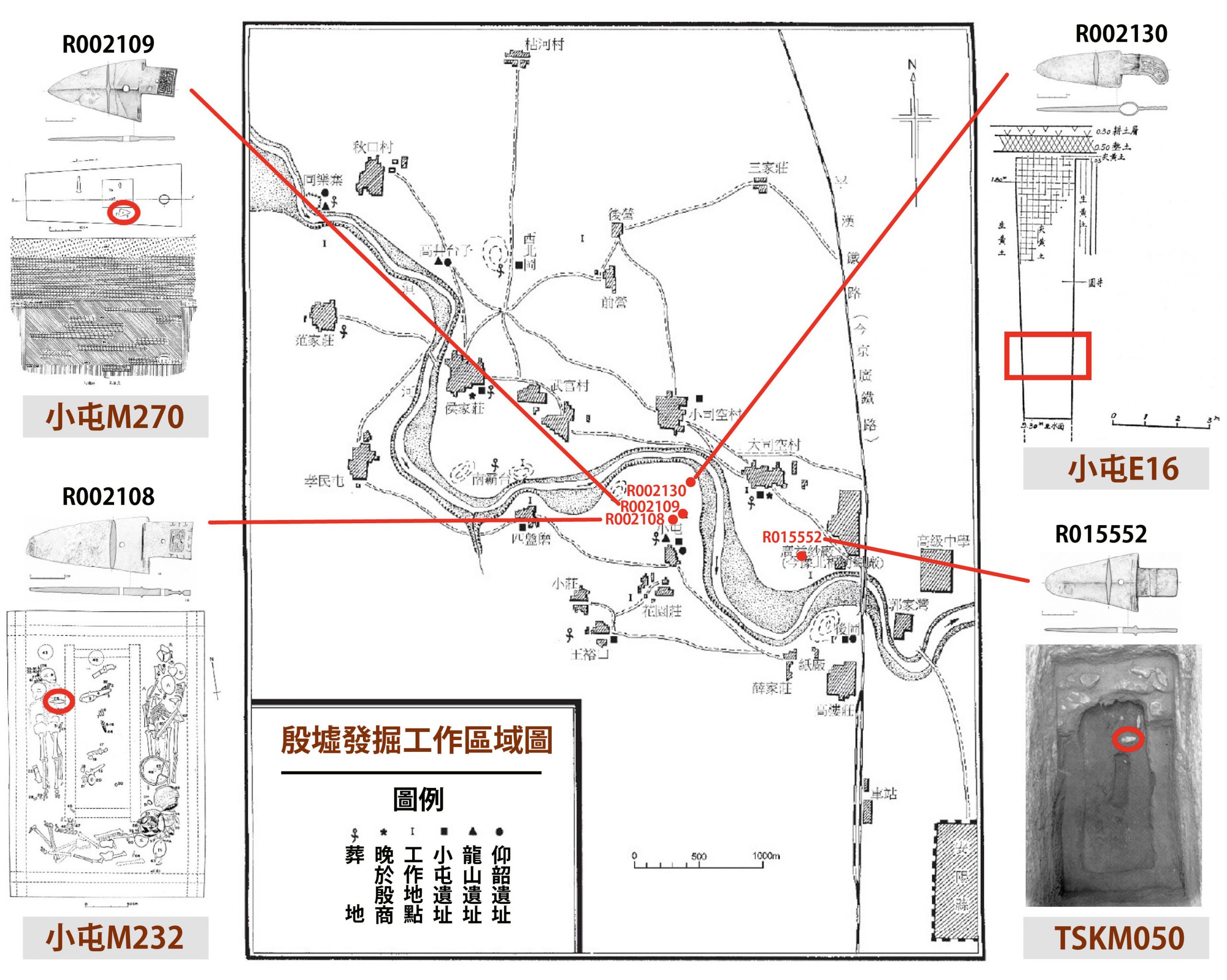
為了藉由銅三角援戈此一個案,進一步探索商代複雜的區域互動關係,李修平首先分析史語所典藏的 4 件殷墟出土銅三角援戈。當中有 2 件「直內三角援戈」和 1 件「曲內管銎三角援戈」發現於洹河以西的小屯東北地(即一般所謂的「宮殿區」)。另有 1 件「直內三角援戈」發現於洹河以東的大司空村。
研究的起點,就得先從殷墟的地理位置,與文物的出土脈絡說起。
 圖為 4 件銅三角援戈在殷墟的發現地
圖為 4 件銅三角援戈在殷墟的發現地
圖|中央研究院歷史語言研究所、李修平提供
殷墟是商代晚期的王都遺址,其歷史可追溯至距今 3000 多年前,位於今日中國河南省安陽市的洹河流域,佔地廣袤,遍布大大小小的遺址。
史語所自 1928 至 1937 年間,陸續在殷墟進行 15 次考古發掘,在當年是首次由官方學術單位,在單一遺址中,進行長時間、大規模、系統性的考古發掘工作,奠定了中國考古學往後 90 餘年的發展。
為了尋找中國最早的文字──甲骨文,經過多年調查,史語所的考古學家前往安陽市西北部的小屯村,進行田野考古工作。由於小屯村以北發現大量的夯土台基,顯示此處曾是商代晚期的宮殿和宗廟的所在地,因而稱之為「小屯宮殿區」。此外,更在小屯宮殿區的西北方、洹河以北的侯家莊以北,發現了「西北岡王陵區」。
考古學家藉由解讀出土於殷墟的甲骨文,證實了歷史文獻上殷商王朝的存在。墓葬中更找到各式青銅製的禮、兵器,與《左傳》「國之大事,在祀與戎」的記載相符。毫無疑問,在不晚於殷商時期,「祭祀」和「戰爭」就是一個國家立足的根本。
 1936 年春,史語所考古團隊在小屯村北的張家七畝地,發掘關鍵的 YH127 坑,出土 17,096 片記載殷商王室祭祀活動的甲骨。圖為工作人員正在將整塊埋有甲骨的土層挖出,準備裝箱運回南京的研究室清理。右方踞於箱上為李濟,其後穿淺色背心坐者為高去尋,其後為李景聃。
1936 年春,史語所考古團隊在小屯村北的張家七畝地,發掘關鍵的 YH127 坑,出土 17,096 片記載殷商王室祭祀活動的甲骨。圖為工作人員正在將整塊埋有甲骨的土層挖出,準備裝箱運回南京的研究室清理。右方踞於箱上為李濟,其後穿淺色背心坐者為高去尋,其後為李景聃。
圖|中央研究院歷史語言研究所
在殷墟發掘的文物,皆有賴考古學家就其出土「脈絡」,還原身世背景。
除了觀察文物本身的形制、材質、刻紋等外在特徵之外,文物出土的地層、在遺址中的位置、周圍的其他遺存等,都是協助考古學家研究古人思想行為的關鍵。
李修平舉例,一件銅器在遺址的不同地方被發掘,可能暗示它所處的不同生命週期。例如在作坊附近發掘,可能是半成品或廢料;在居住區發掘,可能是使用中的物品;在垃圾坑發掘,可能是毀棄品;在墓葬中發掘,則可能是陪葬品。
 「戈」除了作為兵器,也可做禮器使用。圖為殷墟小屯宮殿區 331 號墓出土的「玉援銅內戈」,其援部是玉製,功能可能類似領導者手持的儀仗。
「戈」除了作為兵器,也可做禮器使用。圖為殷墟小屯宮殿區 331 號墓出土的「玉援銅內戈」,其援部是玉製,功能可能類似領導者手持的儀仗。
圖|研之有物(拍攝自中央研究院歷史語言研究所歷史文物陳列館)
從墓葬風格推算墓主身份地位?從戈的形狀看出區域互動可能性?
史語所典藏的 4 件殷墟出土銅三角援戈,有 3 件出自墓葬、1 件出自水井。首先,李修平從墓葬所在的位置、墓室的規模、陪葬品數量,以及是否有殉葬者,推測墓主的身分,與文物對墓主的個人意義。
舉例來說,直內三角援戈 R002108、R002109 皆出自小屯宮殿區的墓葬(這兩座墓葬的年代,均埋於「小屯宮殿區」形成之前)。雖然這兩把銅戈都做工精美、鋒利依舊,但出土墓葬的「排場」卻有所落差。
R002108 出自墓葬 M232,規模頗大,不但有殉葬者,還有眾多銅、石兵器,暗示墓主的身分地位與眾不同,生前可能有指揮作戰的能力。R002109 則出自墓葬 M270,規模較小、陪葬品也少,推測墓主在當地社群大概屬低階貴族。
李修平指出,上述兩件「直內三角援戈」雖然都出自墓葬,但這兩件兵器對於它們的擁有者來說,意義可能大不相同。
對墓葬 M270 墓主來說,R002109 是他為數不多的陪葬品中相對珍貴的器物。反觀墓葬 M232 墓主,不只陪葬品豐富,胸前還放了一把比 R002108 更精美、鑲有綠松石的曲內銅戈。此外,就陪葬品放置的位置來看,M232 墓主可能重視鑲嵌綠松石銅戈,更勝於 R002108。
 「直內三角援戈」R002108(上)、R002109(下)都出自墓葬,風格各具特色,但從出土脈絡推測,這兩件兵器對於它們的擁有者來說,意義可能大不相同。
「直內三角援戈」R002108(上)、R002109(下)都出自墓葬,風格各具特色,但從出土脈絡推測,這兩件兵器對於它們的擁有者來說,意義可能大不相同。
圖|研之有物(拍攝自中央研究院歷史語言研究所歷史文物陳列館)
此外,李修平也透過分析出土脈絡,為大司空村發掘的「直內三角援戈」R015552 拼湊出不同身世。
R015552 的前鋒圓鈍、內上沒有可穿繩的孔洞,作戰時戈頭容易與握柄分離。因此,李修平推測,這把銅戈可能不是實用兵器,而是作為儀杖或有其他用途。
此外,R015552 所在的墓葬位於殷墟的「東部工業區」,該地已發現生產各式骨器、陶器的作坊,或許也鑄造銅器,而此墓葬的位置正好位於骨器作坊的範圍。
因此,墓主的身分地位和所屬社群,可能與小屯宮殿區的政治菁英較遠,而與大司空村南地的工匠社群較近。
 「直內三角援戈」R015552,發掘自大司空村墓葬,當地在商代晚期是作坊區,因而推測墓主身分應與工匠社群有關。
「直內三角援戈」R015552,發掘自大司空村墓葬,當地在商代晚期是作坊區,因而推測墓主身分應與工匠社群有關。
圖|研之有物(拍攝自中央研究院歷史語言研究所歷史文物陳列館)
另一方面,李修平也從造型特殊的「曲內管銎三角援戈」R002130,觀察到區域互動的可能性。
R002130 的出土地點特殊,位於小屯宮殿區北部的一處水井內。這座水井出土的考古遺存數量豐富、材質多元,包括占卜用的甲骨、銅渣(代表附近可能有鑄銅活動),以及至少 21 件青銅兵器與工具。李修平推測,這些青銅器物的擁有者可能是生活或服務於小屯宮殿區的人員。
為什麼說「曲內管銎三角援戈」反映出區域互動的可能性呢?
首先,在二里頭文化時期至小屯文化時期,中原地區(黃河中下游、今日中國河南省一帶)出土的銅戈,其援部大多呈長條形,外觀呈現三角形者相對較少。如前所述,援部呈三角形的銅戈,究竟源於何地,仍有進一步討論的空間。
此外,能插入握柄的管銎設計,是北方式青銅器的特色,殷墟雖然有出土管銎銅戈,但數量遠不及無管銎設計的銅戈。
最後,曲內設計是中原地區銅戈常見的造型,最早見於二里頭文化時期,但融合「三角形援」和「曲內」這兩種設計的銅戈卻非常罕見。
李修平認為,「曲內管銎三角援戈」展現了各地物質文化元素在晚商王都交融的現象,也體現了商代工匠勇於實驗各種創新的銅戈設計,致力打造出能讓戈頭和握柄緊密結合的完美兵器。
 「曲內管銎三角援戈」R002130,展現各地物質文化元素在晚商王都交融的現象,也體現商代工匠勇於實驗各種創新的銅戈設計。
「曲內管銎三角援戈」R002130,展現各地物質文化元素在晚商王都交融的現象,也體現商代工匠勇於實驗各種創新的銅戈設計。
圖|中央研究院歷史語言研究所(擷取自李修平,〈從考古脈絡論史語所藏殷墟出土銅三角援戈〉;施汝瑛拍攝)
「研究史語所收藏的殷墟出土銅三角援戈,只是研究的起點。」李修平表示:「直到今日,殷墟的考古工作已持續進行約 100 年,不僅累積龐大的材料,更發現種類豐富的『舶來品』。此外,在上古中國境內各地,也陸續發現五花八門的外來遺存。換句話說,運用脈絡比較分析法來研究上古中國的區域互動,其實才正要起步。」
跳脫「華夏中心史觀」!區域互動有多複雜?
 李修平自 2020 年起,接手史語所安陽工作室的主持工作,他試圖跳脫「華夏中心史觀」,將上古中國的區域互動關係進行更細致的梳理。
李修平自 2020 年起,接手史語所安陽工作室的主持工作,他試圖跳脫「華夏中心史觀」,將上古中國的區域互動關係進行更細致的梳理。
圖|研之有物
「區域互動」的研究看似有很多材料可做,但李修平坦言,如果單純相信眼前的證據,很可能會誤入陷阱。
舉例來說,假設 3000 年後,外星人來到地球考古,發現臺灣是全世界晶片製造廠最密集的地方,他們可能會以為臺灣是半導體的發源地,但其實真正的發源地在美國。光是當代社會的物質文化都能推敲出多種可能,要推斷 3000 年前殷墟文物背後的區域互動關係,就更加困難。
李修平進一步指出,在中國考古學的研究中,當墓葬中出土了外來遺存,經常採用較籠統的說法。例如,某地「影響」了某地,又或者兩地之間存在某種「關係」,但詳細原因無法具體說明。特別是進入了夏、商、周時期,「華夏中心史觀」成為詮釋區域互動的基本預設。
其中一個例子,就是被學界視為夏朝晚期的二里頭文化與周邊地區的關係:一般認為,二里頭的物質文化就像太陽般輻射四方,只要在周遭地區看到類似的物質文化,很可能就是受到二里頭的「影響」。
「但這樣的論述其實有待商榷。」李修平點出爭議:「只因為看到這邊出土的陶器跟二里頭的陶器類似,就能斷定它被二里頭「影響」嗎?物質文化流傳的動力,是文化?是政治?是經濟?還是偶然的巧合?又或者是其它多重、複雜的因素?」
有關區域之間的「互動關係」,其內涵充滿各種可能性,諸如交換、模仿、貿易、移民、戰爭或殖民等原因,真相並沒有那麼單純。
因此,自 2020 年接手史語所安陽工作室以來,李修平就試圖跳脫「華夏中心史觀」,將上古中國的區域互動關係進行更細緻的梳理。
然而,研究過程並不容易,因為做研究必須跟著材料走,而不是跟著既有的、主流的論述走。如果有新的材料出土,就要接受已有的認識很可能被挑戰、甚至推翻的可能性。
「現代社會都這麼複雜了,古代社會也有它複雜的一面。」李修平望著眼前正在進行的研究,僅管還有許多難題未解,卻擋不住他躍躍欲試的心情。
「新的考古材料持續出土,不斷更新我們對古代世界的認識。儘管如此,考古學家仍要竭澤而漁,盡力蒐羅所有材料,試圖在相對穩固的基礎上,還原古代社會的複雜性,並提出比較合理的解釋。這是我做研究的基本態度。」