

- 作者/奇普‧希思、丹‧希思;譯者/洪士美
想早起卻總是離不開床?
現在來看看麻省理工學院的學生葛莉‧南達(Gauri Nanda)發明的落跑鬧鐘(Clocky)。它可不是普通鬧鐘,它有輪子。你在每天晚上設好鬧鐘,當早上鬧鐘響起時,落跑鬧鐘會從床頭櫃上滾下來,在房間裡亂竄,逼得你非得起床追著它跑。想像一個畫面:穿著睡衣的你在地上爬行,邊追趕邊咒罵一個四處亂竄的鬧鐘。

落跑鬧鐘確保你沒有機會按下賴床鈕,也讓你避免因為賴床釀成災難。顯然睡過頭是個普遍存在的恐懼,因為售價五十美元的落跑鬧鐘上市前兩年,就賣出了三萬五千個(儘管沒什麼宣傳)。
這項發明的成功讓人們見識到人類的心理。其中一個重點是,人人都有精神分裂的毛病。一部分的自我(理智面),想要在早上五點四十五分起床,讓自己在上班前還有時間先去慢跑;另一部分的自我(情感面),一大清早在黑暗中醒來,卻蜷縮在溫暖的被窩中賴床,覺得世界上沒有比再多睡個幾分鐘更棒的事。
如果你跟我們一樣,情感面總是在這類的內心交戰中獲勝,看來你也需要一個落跑鬧鐘。這個產品最棒的地方在於,它可以協助你的理智面戰勝情感面,當一個暴走的鬧鐘在房裡四處亂竄,誰還能安穩的躺在床上。
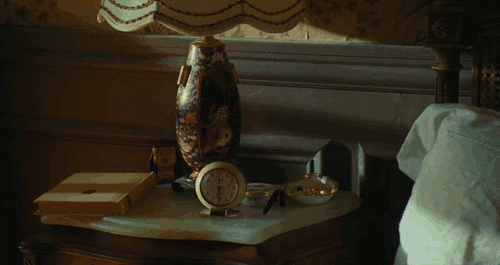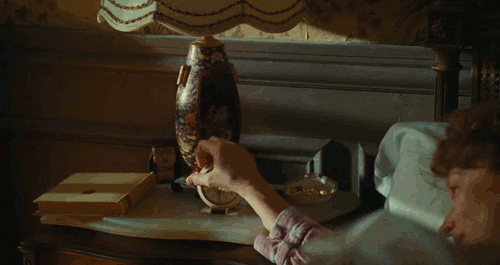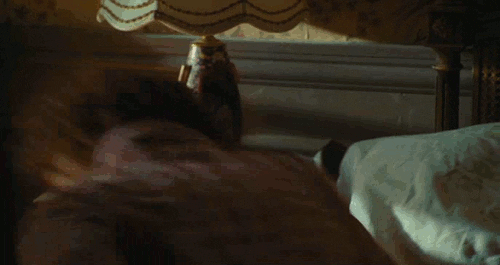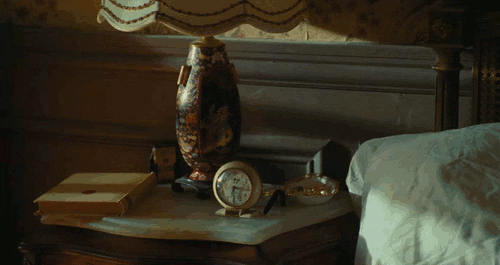
說得直白點:落跑鬧鐘不是為那些理性的人所設計。如果《星際爭霸戰》(Star Trek)中的半瓦肯人史巴克(Spock)(編按:瓦肯人在劇中的設定是能抑制情感的干擾,並以嚴謹的邏輯去思考)想在早上五點四十五分起床,根本不用那麼麻煩,時間一到他就會起床。
人們內在的精神分裂異常詭異,但因為習以為常,也就不以為意。當我們開始新的減肥計畫,會先清空櫃子裡的芝多司起士條和奧利奧餅乾,因為理智面知道,當情感面有了渴望時,往往毫無自制力可言。唯一的辦法是排除所有誘惑。(其實,如果麻省理工學院的學生可以開發出自動躲避減肥者的芝多司,肯定會發大財。)
結論就是:你的大腦無法齊力同心。
情感與理智的愛恨糾葛
其實心理學界普遍認為,人類大腦隨時都有兩個獨立的系統在運作。第一個是所謂的情感面,屬於直覺層面,感受痛苦與歡樂。第二個是理智面,也可稱為反思和意識系統。理智面讓你懂得深思熟慮、重分析,並展望未來。

過去數十年來,心理學家對這兩個系統的研究成果豐碩,但人類對自身的內在衝突早已有所自知。柏拉圖認為,人的大腦中有個理智的馬車伕,他得駕馭一匹桀驁不馴的馬,「唯有用馬鞭、馬刺伺候,才能勉強使其就範。」佛洛伊德則是闡述自私的本我與自律的超我(還有協調兩者的自我);近代則有行為經濟學家將這兩個系統稱為計畫者和行動者。
但對我們而言,維吉尼亞大學的心理學家強納森‧海德特(Jonathan Haidt)在其精彩的著作《象與騎象人》中,對兩者緊張關係的比喻最為貼切。
海德特表示,人類的情感面是一頭大象,理智面則是騎象人。騎象人手握韁繩,坐在大象身上,看似是領導人。但相較於大象,騎象人的身形實在太過矮小,因此他對大象的控制力並不穩定。每當六噸重的大象和騎象人對前進的方向有不同的看法時,騎象人完全不是大象的對手,注定會敗下陣來。

大多數人對於我們內心中的大象壓制騎象人的情況都非常熟悉。倘若你曾睡過頭、吃太多、半夜忍不住打電話給前任情人、做事拖拖拉拉、戒煙失敗、偷懶不去健身房、因為憤怒說出後悔的話、放棄西班牙文或鋼琴課、因為害怕不肯在會議上發言,就意味著你有過這樣的經驗。還好沒人在一旁打分數。
大象與騎象人同心協力,改變會更加容易
大象(人們的情感和直覺面)的弱點明確可見:懶惰又膽小,往往尋求當下滿足(甜筒),而非長期回報(身材苗條)。當針對改變付出的努力得不到成果時,通常是大象的錯,因為人們所追求的改變多半要藉由犧牲短期利益,來換取長期回報(為了明年的資產負債表能有更好的表現,我們現在努力削減開支。為了明年能有更好的體態,今天的我們忍痛不吃冰淇淋)。
改變之所以經常失敗,是因為騎象人無法讓大象乖乖朝著目的地前進。
騎象人的優點正好與大象及時行樂的行徑相反,他擅長跳脫當下,思考並規劃長遠的未來(這些都是你的寵物辦不到的事)。但令人意外的是,大象也有極大的優點,而騎象人也有致命的弱點。
大象不見得總是壞蛋。諸如愛與憐憫、同情與忠誠,都是大象所掌管的情緒。保護自己的孩子免受傷害的強大本能,也來自大象。當你必須為自己挺身而出時內心的那股激動,也是出自大象。更重要的是,如果你正在考慮做出改變,大象才能負責完成任務。

無論你的目標是否崇高,都需要大象的能量和動力才能達成。這個優點正好對照出騎象人的弱點:原地踏步。騎象人往往過度分析、想太多。你很可能認識一些有騎象人毛病的人:你的朋友可以為了晚餐要吃些什麼,掙扎二十分鐘;你的同事花了好幾個小時腦力激盪,卻遲遲無法做出決定。
如果你想做出改變,就得兩頭並進。由騎象人提供計畫與方向,大象提供動能。
因此,如果你找到了團隊的騎象人,這些人只有理解力,沒有行動力。如果你搞定的是團隊的大象,他們空有熱情,卻缺乏方向。無論是哪種情況,各種缺失都足以阻礙改變。一頭不情不願的大象和一個原地踏步的騎象人,都讓改變無從發生。但當大象和騎象人同心協力,改變可以是件容易的事。
- 下一篇,帶你了解:〈想要改變,單靠自制力是不夠的!何不試試讓理智與情感合作?——《學會改變》下〉
 ——本文摘自《
——本文摘自《



































