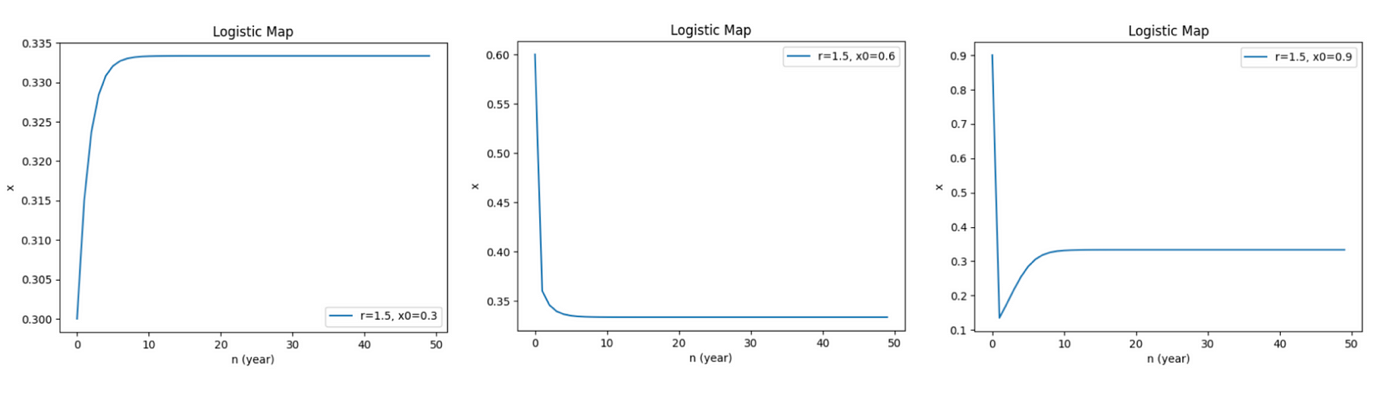
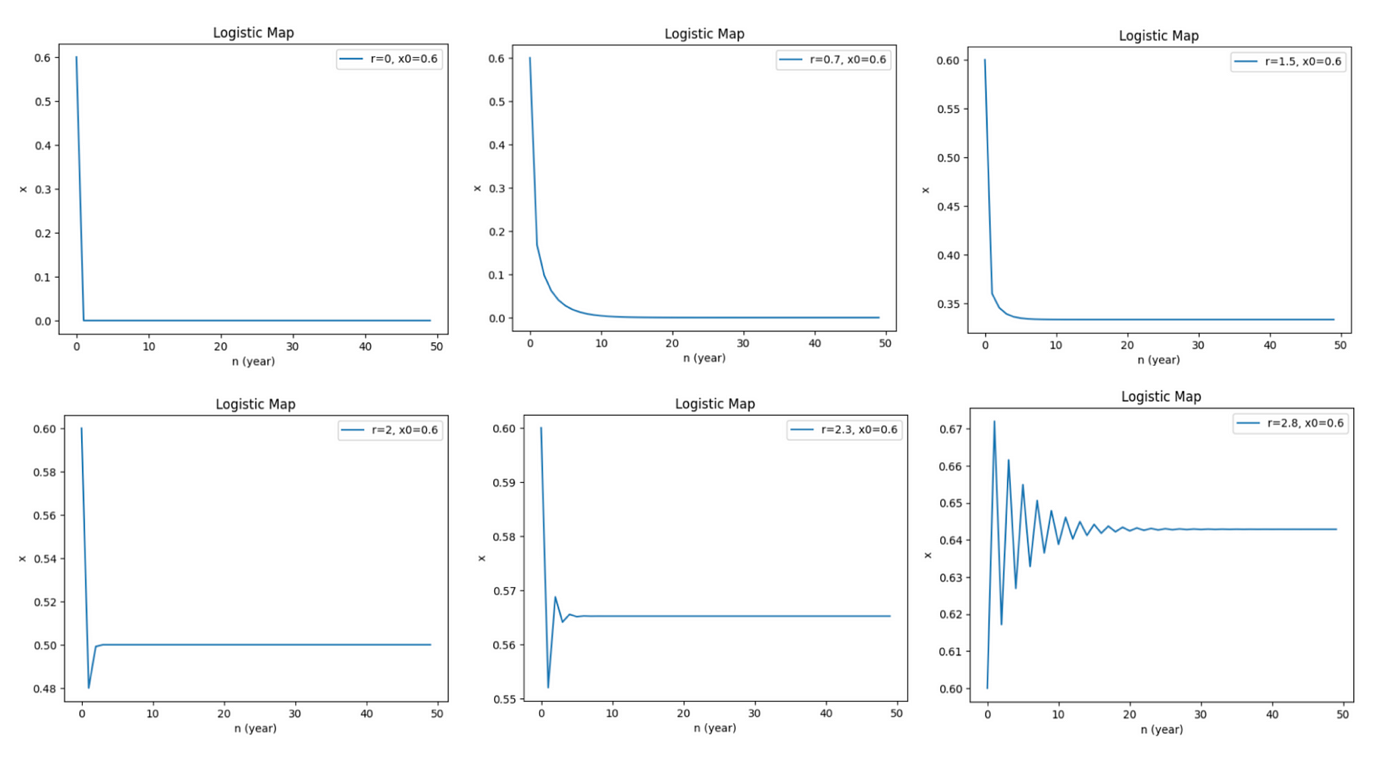
這裡呈示了 r=0 到 2.8 之間的圖表,可以看出在 r 超過 2.5 時,振盪發生,即使如此、依舊回歸平衡值。
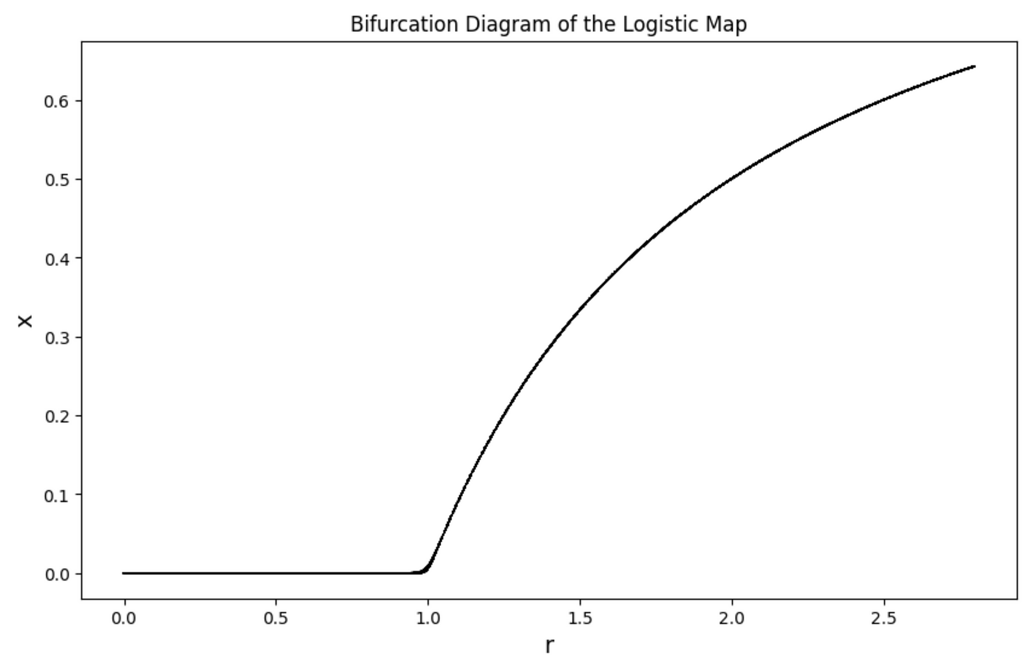
當我們將 r 值逐步增加,一切看似並無異常;當 r=2.8 時,我們發現圖形出現了週期性的振盪,但最後依舊回歸平穩。順帶一提,我們可以藉由「分枝圖」(bifurcation diagram) 來觀察 x 的穩定值與 r 的關係,在 r=0 至 2.8 之間,x 穩定值有攀升趨勢;在 r=1.5 時,根據前述的例子,x 的穩定值落在 0.33 左右,從下圖也可以直接看出:
呈現 x 穩定值與 r 之間的分枝圖,r=0 與 r=2.8 之間,穩定值有攀升趨勢;在前述例子中,r=1.5 對應到的穩態相當於 x=0.33 上下。
我們繼續調大 r 值。正當一切看似正常發展時,詭異的事情發生了:
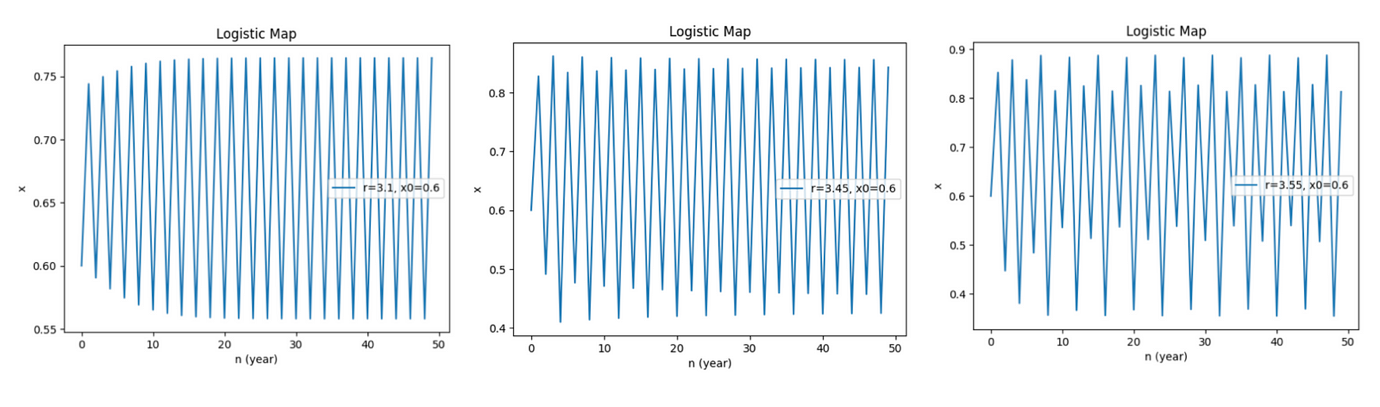
當 r 大於 3 時,週期性的振盪發生,且不再回歸平穩值。由左至右分別是 r=3.1、r=3.45、與 r=3.55 的圖表。
在此之前,一切族群的數量都是平穩的,但在 r 超過 3 左右,持續的振盪出現了,且自此「平衡點」不復存在;不僅如此,當 r 值不斷調升,顯示出來的圖像從原本 2 個值、4 個值、到更多值之間來回振盪。值得一提的是,這種「週期性振盪」的現象在生態圈與人口變化中是確實存在的,很有可能前一年數量減少、今年數量增加、明年數量又再減少。讓我們來看看對應的分枝圖:
-----廣告,請繼續往下閱讀-----
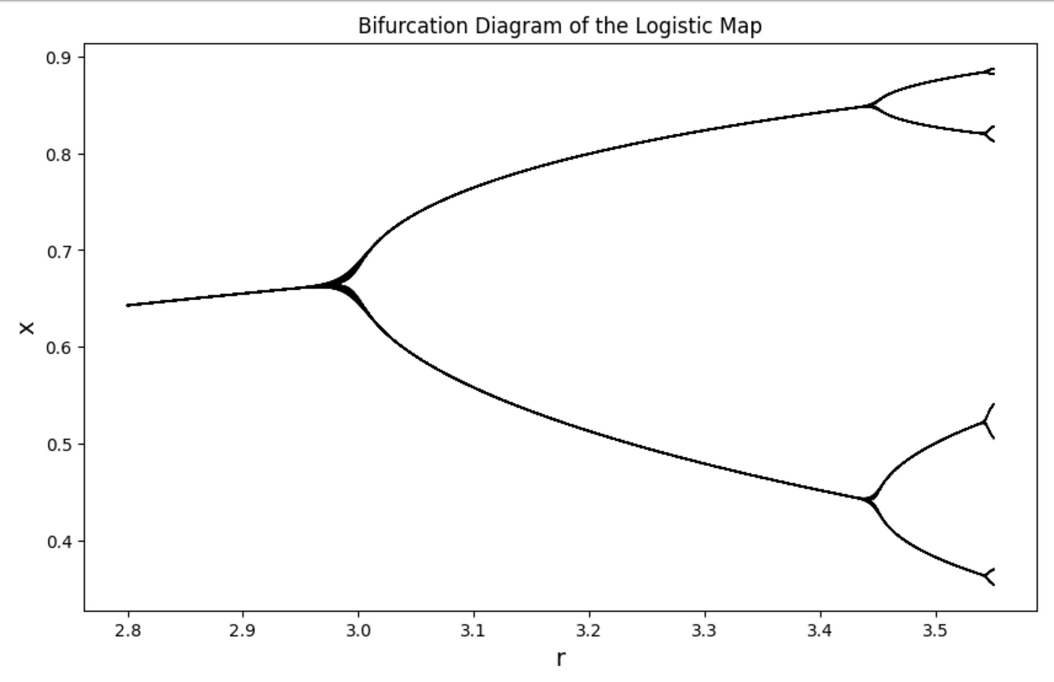
圖為 r=2.8 至 3.55 之間的分枝圖,可以發現數目振盪導致的「分岔」。
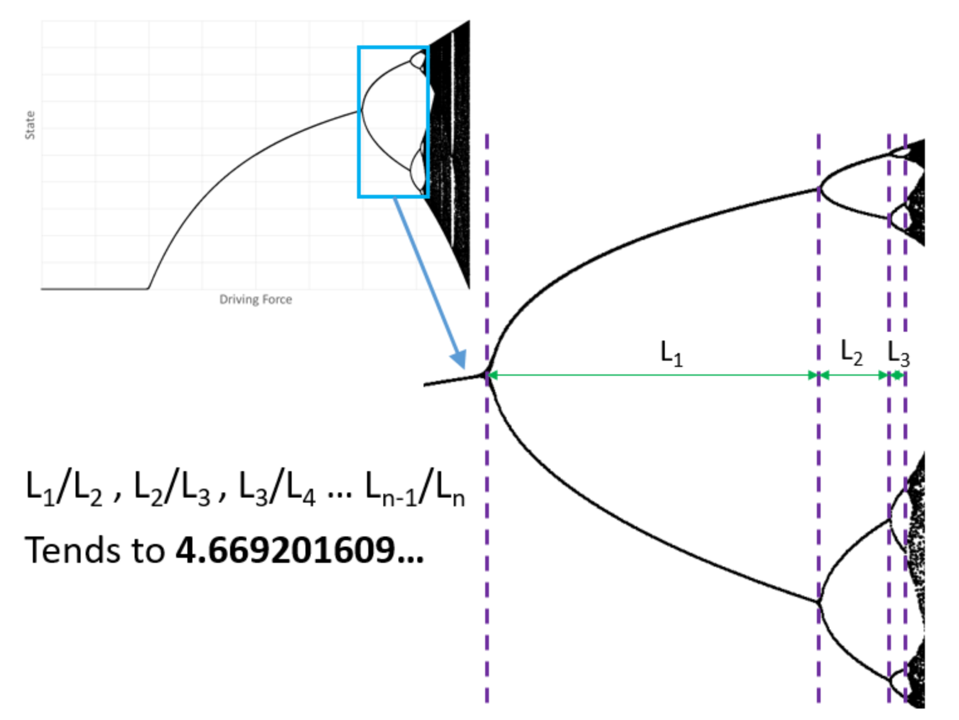
這對應於原本從 2 個值之間的擺盪、分岔成 4 個值之間的擺盪、再分岔成 8 個值之間的擺盪……如此往復。此外,如果你留意橫軸 r 之間的間隔,會發現:當 r 愈大時,分岔的速度也愈快!
現在讓我們繼續將 r 值調升,來看看會發生什麼事:
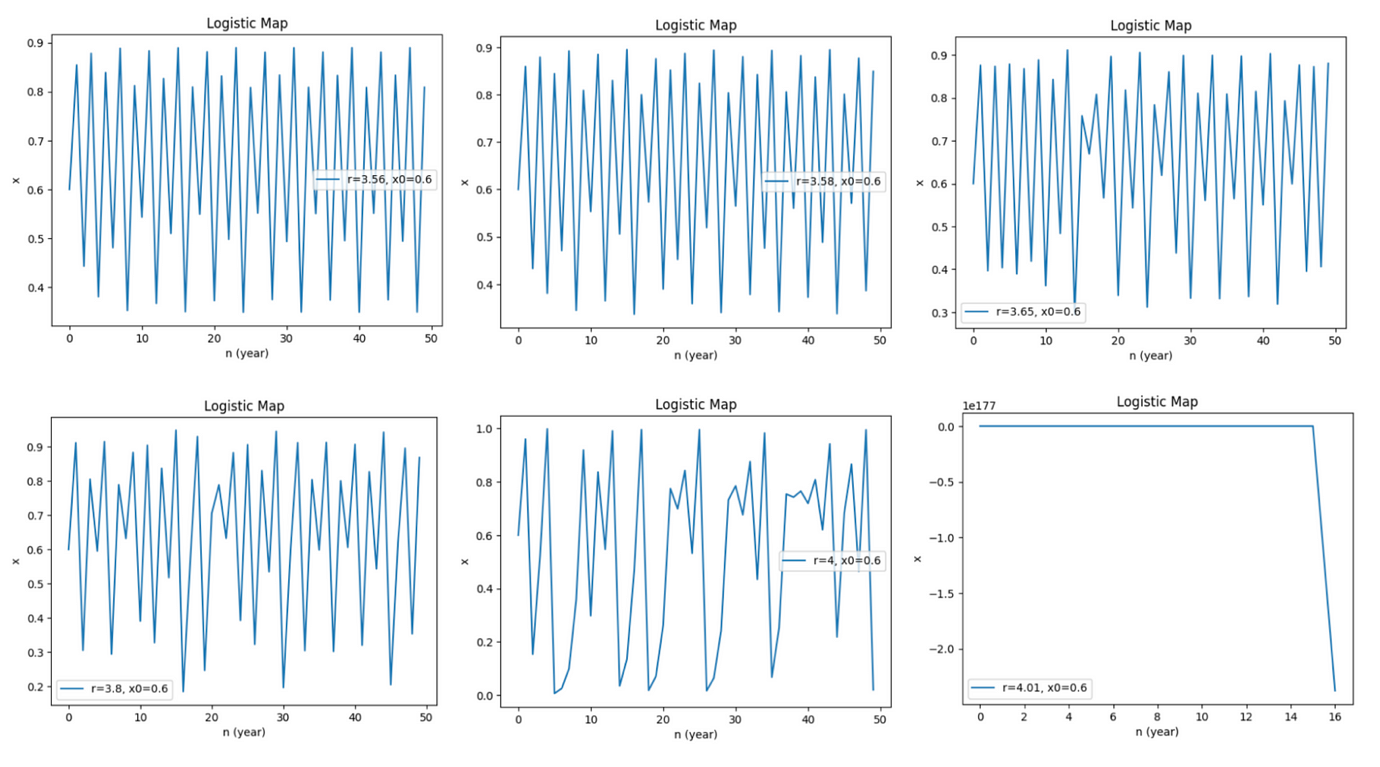
隨著 r 不斷提升,系統呈現隨機的跡象,在 r 超過 4 時系統發散。上圖分別演示了 r=3.56、r=3.58、r=3.65、r=3.8、r=4 與 r=4.01 的情景。
話不多說,我們直接來看看分枝圖:
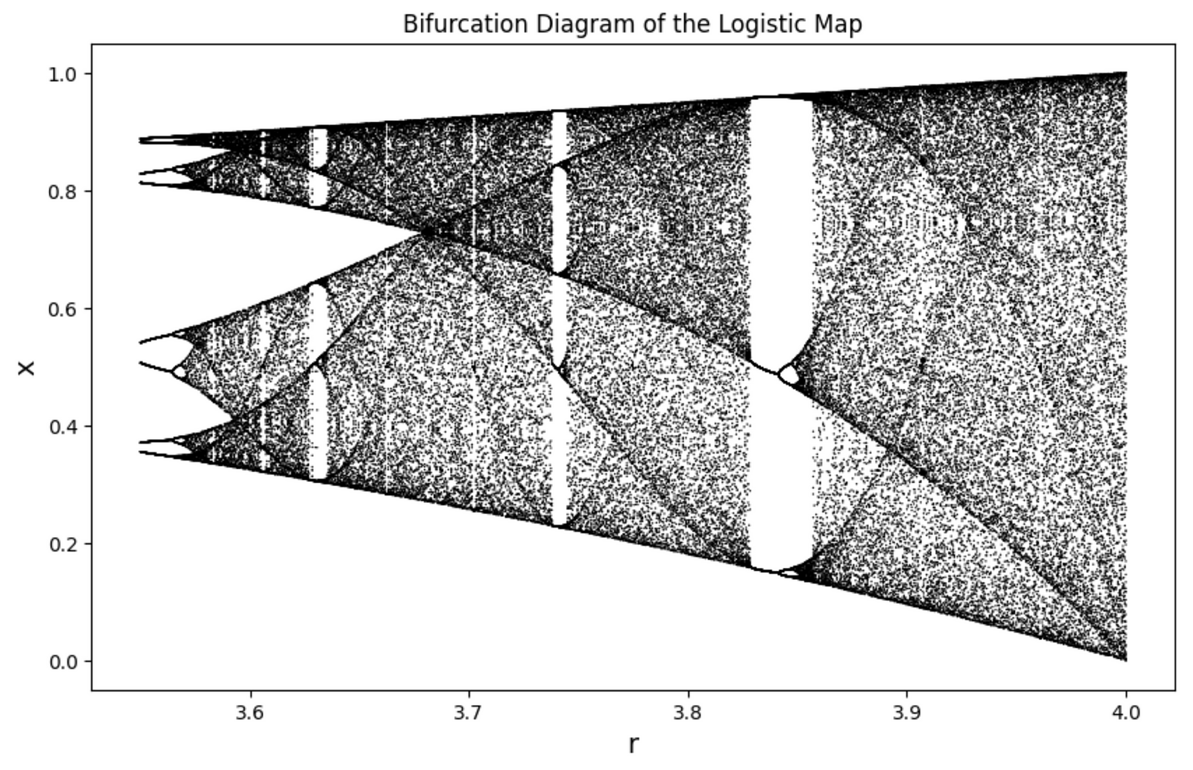
在 r=3.55 至 r=4 之間的分枝圖,分岔不斷衍生、並進入隨機的模式。
令人毛骨悚然的結果出現了!前面我們觀察到,當r提升時,系統會出現週期性的振盪,對應於分枝圖中的「分岔」,且分岔的速率會不斷增快、再增快;而在 r 超過 3.5699 時,規律的振盪、分岔將不復存在,取而代之的是一團無法預測的隨機——這就是所謂的「混沌」(chaos)。
-----廣告,請繼續往下閱讀-----
混沌、股票市場、以及蝴蝶效應
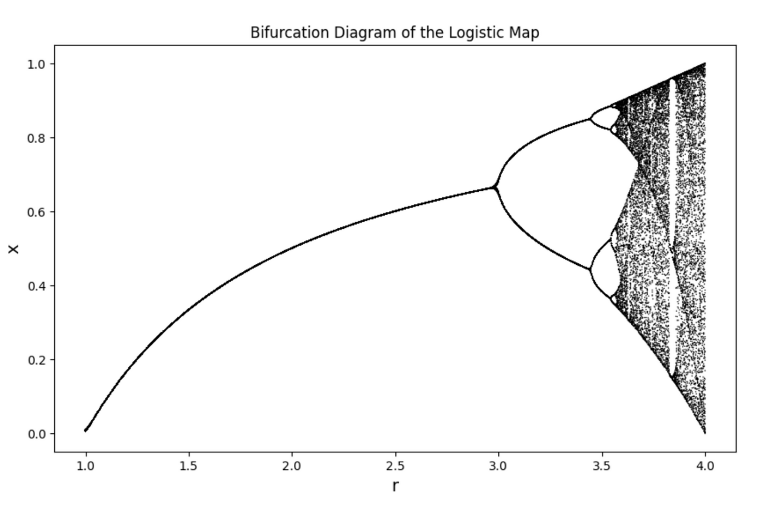
現在讓我們看一下完整的分枝圖長什麼樣子:
單峰映射的分枝圖,從 r=1 至 r=4,可以看出系統在 r 超過一定值後進入混沌狀態。
換而言之,當系統的變量到一定程度時,將會變成隨機且無法預測的。以人口為例,一開始我們假設的情況很簡單,就是 60 萬人口與 r=1.5 的成長率;接著我們發現,無論人口基數如何,只要 r 維持原狀,數年、乃至於數十年後的平衡點都是相近的。然而,當r值提升後,平衡點的值便會浮動了,r=3 之後週期性的振盪便出現了、且分岔點不斷加速倍增;緊接著,我們赫然發現:
科學研究者,1999年生於台北,目前於美國佛羅里達大學(University of Florida)攻讀物理學博士,並於費米國家實驗室(Fermilab)從事高能物理相關研究。2022年於美國羅格斯大學(Rutgers University)取得物理學學士學位,當前則致力於學術研究、以及科學知識的傳播發展。 同時也是網路作家、《隨筆天下》網誌創辦人,筆名辰風,業餘發表網誌文章,從事詩詞、小說、以及音樂創作。