


文/ 陳紹慶(慈濟大學人類發展學系專任助理教授)
區間估計,或稱信賴區間的計算程序,是許多運用統計分析資料的知識領域常用的分析方法,也是一般大眾最常接觸的推論統計資訊。這篇文章假設讀者了解如何進行區間估計程序,我想討論用在心理科學研究分析有何好處與限制,這個限制使得進行假設檢驗型的研究還是需要假設檢定。
首先舉兩個使用區間估計的例子。第一個例子配合寫這篇文章時的時事,引用台灣指標民調在太陽花學運退出國會隔天發佈的新聞稿,熟用統計方法者大概會像我一樣,看各項調查結果前,先找到調查過程的描述:
本項調查是 TISR 台灣指標民調公司在 2014年4月7日至9日進行,以隨機跳號抽樣及電腦輔助人員電話訪問,完訪 1004 位居住在台澎金馬、年滿 20 歲的民眾,在95%信賴水準時抽樣誤差±3.1%。上述各項結果已對受訪者性別、居住縣市、年齡、教育程度,進行樣本代表性檢定與加權處理(raking)。
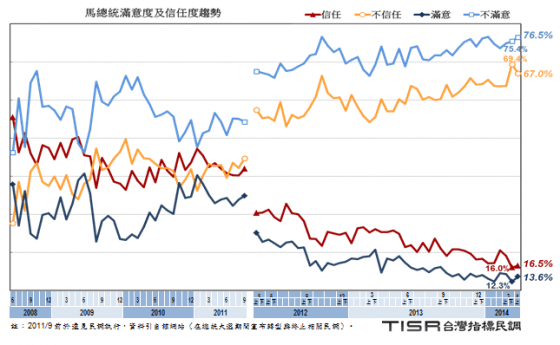
從新聞稿中的圖表,我們看到這段時間民眾對馬英九總統的滿意度來到 13.6%。如果要問如何正確解讀這個統計資訊,我能提出的問題是:這份民調能否證實馬總統是否還是抗爭人士聲稱的 9% 總統?但是從科學研究方法的觀點來問,這份民調可否證實馬總統確實有負投票給他的選民?
第二個例子是太陽花學運結束時刊登在 POLS one 的英文與德文詞彙變遷研究,研究者比較 18 世紀到 20 世紀英文與德文語料的變遷。統計的單位是具備相同詞素的字詞,在三百年之間的消長,例如英文出現「run」之後,「runner」、「runway」等詞出現的情況。
同詞素的字詞可能會有越來越多的新詞出現,也可能有字詞隨時代前進不再被使用,因此統計模型要估計的是同詞素字詞在調查的年代之間「出生率」與「死亡率」。評估的模型之一假設「出生率」與「死亡率」相等,所以先對所有語料記錄的字詞「出生率」與「死亡率」比例,進行區間估計,確認符合這項模型的假設(估計結果見此文件,Figure S2)。究竟是那個模型最符合字詞出生與死亡的趨勢,我以後有空會寫篇文章說明,現在先請好奇的讀者自行閱讀。這個例子同樣要由科學研究方法的觀點提出問題:語料符合模型的假設,對結果的推論真正的幫助是什麼?
要回答這兩個例子帶出的問題,要回頭深入討論前一篇提到的概念:研究的問題樣態會決定研究結果轉換為可靠知識的程度。政治人物的施政滿意度與詞彙在幾百年之間的消長,共同之處是樣本有一個固定的來源(台灣地區有選舉權的公民;相同年代彙集的英文與德文語料),樣本的量數成為計算信賴區間的成份。兩個問題的差異不只是求出的估計值代表的意義,還有求估計值的出發點:在開始搜集資料之前,分析者有沒有預期會得到多少估計值?也就是研究的動機是不是具備特設性假設。從民調中心研究員的角度來看,每次民調都是獨立的過程,一開始沒有預期調查的對象或議題,能從受訪者的回應獲得多少百分比或分數,才能不偏的抽樣。對語料研究人員來說,他們安排計畫時已經有一套模型判別變遷的程度,需要確認資料具備符合模型參數的估計值,才能進行下一步工作。兩造人員的研究過程都符合科學方法的基本精神:以不帶偏見的方式蒐集和分析資料,兩造的關鍵差異在於有沒有一開始具備符合邏輯的「特設假設」(ad hoc hypothesis),這類假設的存在也導致一件研究會是假設探索型,還是假設檢驗型。
維基百科對特設假設的說明相當簡易(中文、英文),而英文的說明比中文多了一段。這段大意是為了填補當前知識的不足之處,需要讓會被證偽的觀察資料(falsifying observations)能在研究過程的中間階段有存在的意義。特設假設的功能就是賦予這種觀察資料存在的意義,後續的研究過程會推翻特設假設,讓研究者能肯定要放棄無法解釋資料的理論或模型,使真正能解釋資料的理論或模型成為肯定的知識。大膽的說,假設檢驗型研究是要推翻不可能成立的特設假設,而假設探索型研究是找出所有可能與理論相反的特設假設。當然這是個人看法,歡迎讀者賜教。
政治人物的滿意度是行為與社會科學研究課題中,最不可能進行假設檢驗的例子。俗話說「民意如流水」,一位政治人物的政治生涯有起有落,不同人物的際遇也很難化約比較。民意調查的功能是呈現當下時空條件的選民意向,調查人員不會設定任何特設假設,或者接受任何結果都有相同的發生機率,如馬總統的每次調查得到 100% 到 0% 任何一個分數的機會都是相同,才能產生可靠的民調結果。詞彙變遷研究已經設定數種預測語料變化的統計模型,以上提到研究者提供的區間估計資訊是確認所有待評估的模型都站在相同的起跑點,接下來的分析才是看那個模型能勝出:最符合資料的分配。這個勝出的模型就能告訴我們英文與德文詞彙在三百年間的消長是什麼樣的故事。
看到這裡應該能了解,為什麼求取創新或更新知識的研究不傾向採用區間估計分析資料,是因為這種方法沒有鑑別特設假設與目標理論的能力。而信賴區間或信賴水準的訊息經常出現在與生活條件相關的抽樣調查之中,因為估計值帶來的資訊只在調查當下的時空條件才有意義。不過心理科學也逐漸理解要保障知識的正確性,需要新的運用統計思維,這個需要的趨勢是來自假設檢定方法的誤用與濫用,是下一篇的討論重點。






































{kind=link}