

本文轉載自中央研究院「研之有物」,為「中研院廣告」
- 採訪撰文|沙珮琦
- 責任編輯|簡克志
- 美術設計|蔡宛潔
不再是有圖有真相!深偽影像猖獗,我們該如何判別?
你看過美國前總統川普被警方逮捕的影片嗎?又或是英國女王在皇宮中大跳熱舞的片段?多年來,人們普遍相信著「有圖有真相」的道理,然而,隨著圖像與影音相關的生成式 AI 越發成熟,我們似乎再也不能輕易相信自己的雙眼。而在真假影音的差異可說是微乎其微的狀況下,我們究竟該如何判斷資訊真實性?中央研究院資訊科技創新研究中心的副研究員陳駿丞與團隊每天在尋找的,便是有效又好用的解決方案。本次,中研院「研之有物」將透過專訪,從生成式 AI 的原理開始了解,一步步為各位解開深偽影像的神秘面紗。
你已經是個成熟的 AI 了!幫我工作!
一講到生成式 AI,許多人都能立刻喊出「ChatGPT」的大名,足見這個領域之熱門程度。其實,生成式 AI 發展並不是近年才開始的事,可是為什麼直到最近,才受到社會大眾的熱烈歡迎呢?
中研院資創中心的陳駿丞副研究員認為,其中最關鍵的原因,莫過於 AI 程式的優秀表現開始讓一般人很「有感」。由於生成式 AI 的相關研究快速發展,基礎建設在近年來逐漸成熟,使用介面也設計得十分親民,讓大眾能透過極為直覺、簡單的方式去使用,實際體會到應用的效果,例如改善工作效率、處理圖像任務等,再加上大眾媒體的渲染,便帶起了 2023 前半年的 AI 風潮。
陳駿丞笑著說,雖然自己不是文字生成式 AI 的專家,但使用「ChatGPT」時,也發現到它真的能做到很多事,比早期的 Siri 效果更好、更準確。的確,對於我們來說,這款基於 OpenAI 開發的大型語言模型(Large Language Model)的聊天機器人(Chatbot),就彷彿是一個全能小秘書一般,可以整理文案、改錯字,甚至連寫程式碼都不在話下。
場景轉換到影像領域,如今市面上也有同樣由 OpenAI 打造出的圖像生成平台「DALL·E 2」,或是大名鼎鼎的「Midjourney 」,都可以很有效率的將使用者文字描述轉換成圖片。雖然這些平台生成的內容偶爾還是會出現「破圖」的情況,例如頭髮少一塊,或是出現奇怪色塊等,但它們的生成速度極快,也能產生不少令人印象深刻的高品質內容;對於一般大眾而言,自然充滿吸引力。
陳駿丞解釋,過去也有許多以文字產生圖片的嘗試,但品質並不佳,而現在之所以可以顯得如此真實,便是借助了「擴散模型」(Diffusion Model)的強大威力。大約 2019 年左右,「擴散模型」逐漸超越了原本主流的「生成對抗網路」(Generative Adversarial Network,GAN),吸引大量研究人員投入,也因此衍生出「Midjourney」這類的圖片服務,打個字、按個鈕便能生成美美的圖片。進階使用者還可以輸入如同咒語般長的自訂提示詞(Prompt),生成符合需求的圖片,甚至還有人專門訓練生成提示詞的 AI,各種 AI 藝術社群也如雨後春筍般成立。
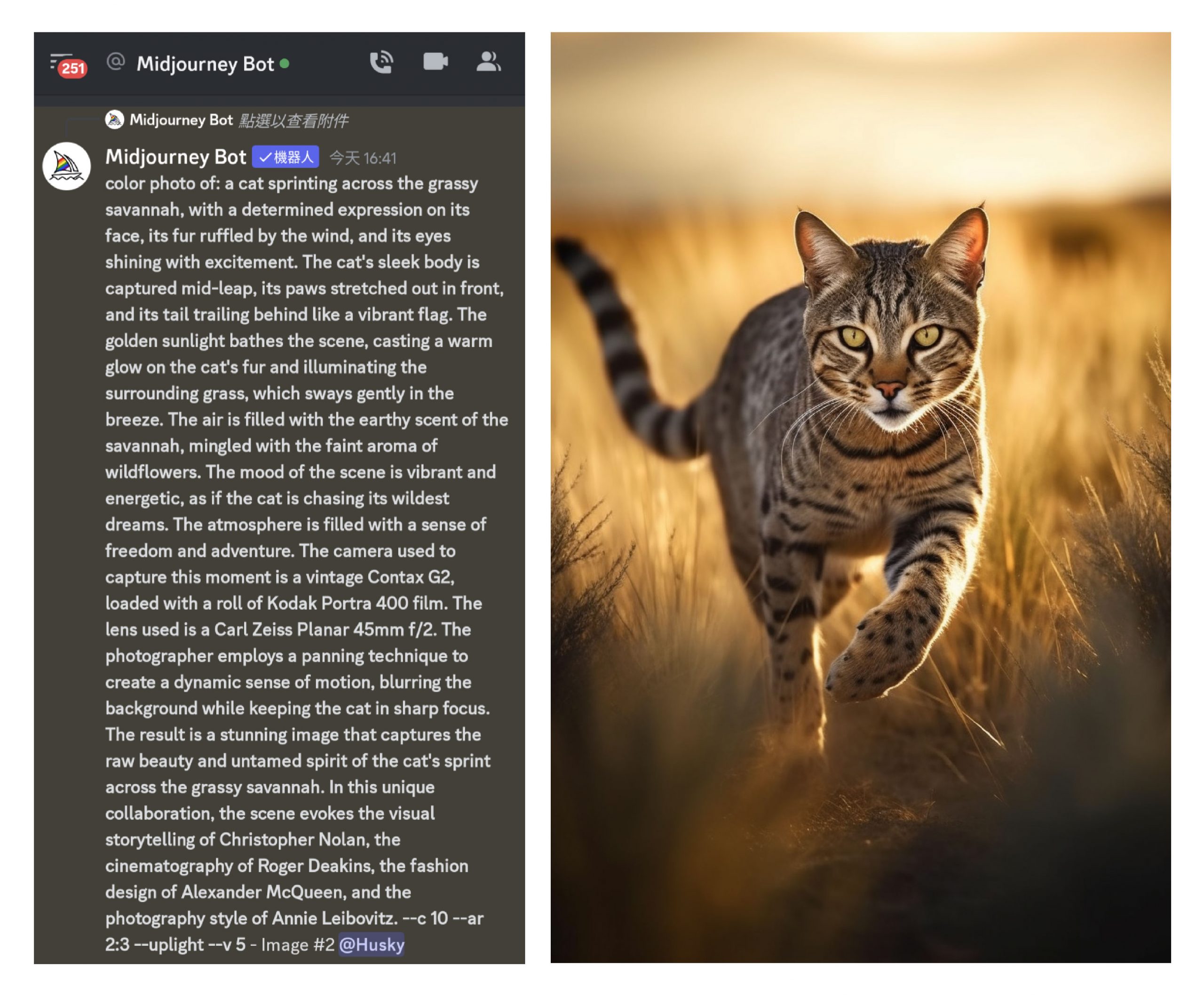
圖|研之有物(資料來源|Midjourney)
神奇 AI 訓練師——「擴散模型」與「生成對抗網路」
等等等等,什麼是「擴散模型」?什麼是「生成對抗網路」?想了解兩者的不同,讓我們先從比較「資深」的那個開始說起。
所謂「生成對抗網路」,其實是由兩個網路所組成的,分別是「鑑別網路」(Discriminating Network)與「生成網路」(Generative Network)。這兩者間的關係就像是考官和學生(亦敵亦友!),學生(生成網路)要負責把圖生出來,交給考官(鑑別網路)去判斷這張圖跟真實圖片的分布究竟像不像,像就給過、不像就退回去砍掉重練。
至於考官(鑑別網路)為什麼能如此精確呢?因為研究員會預先餵給它真實的圖片,好協助鑑別網路做出足夠專業的判斷、給予精準回饋。而學生(生成網路)則在這一次次「交作業、修正、交作業、修正」的過程中,畫出越來越接近真實模樣的圖片。
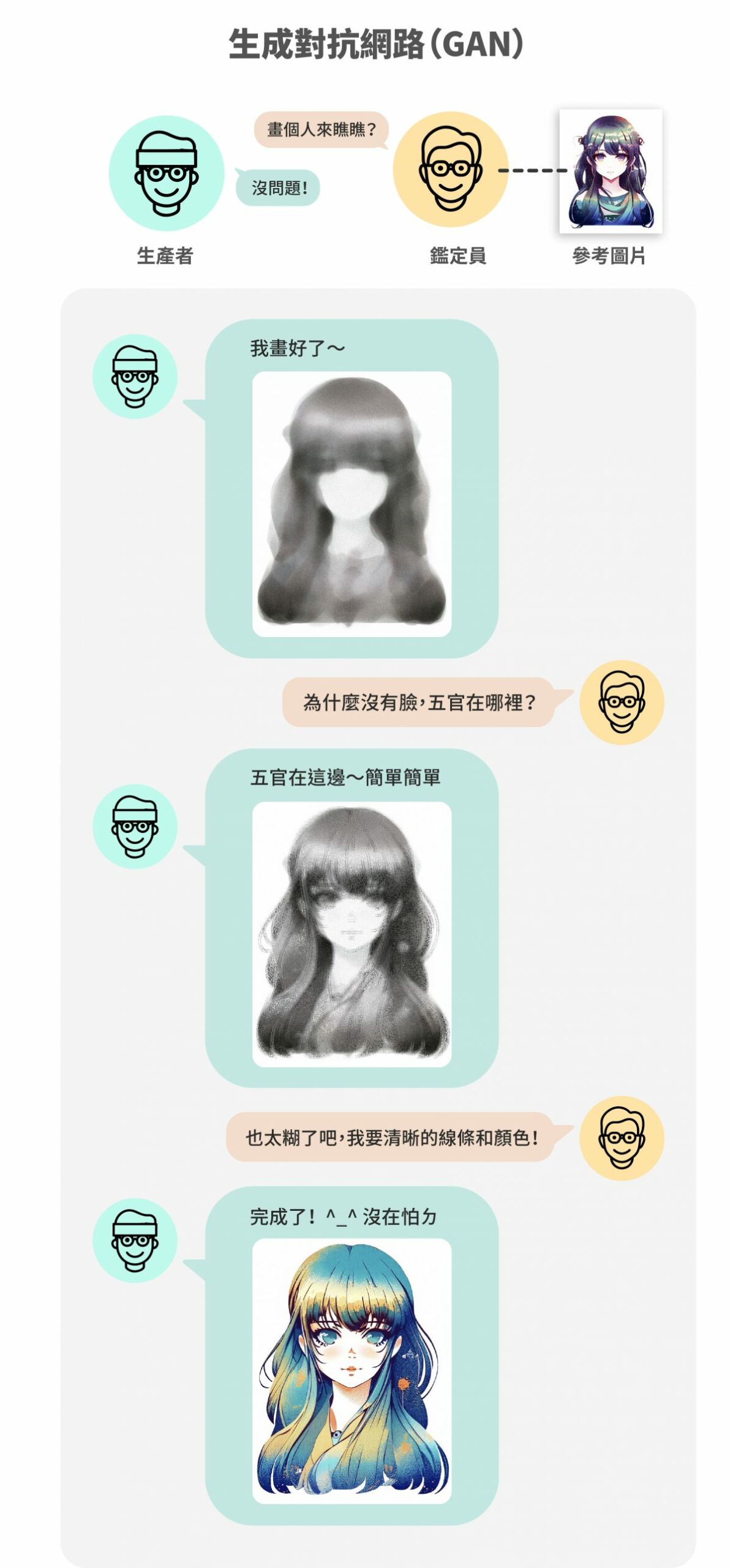
圖|研之有物(資料來源|李宏毅)
相比起 GAN 對錯分明、馬上定生死的特點,「擴散模型」採取的路徑相對而言非常迂迴,但是結果更為精準,如果採用知名電腦科學家臺大電機系李宏毅教授的比喻,擴散模型就像是從一塊大石頭裡面刻出大衛像,圖片就在雜訊當中!
「擴散模型」在訓練期間的第一步是加噪(add noise),以貓為案例來說,擴散模型的原理就是將一張正常的貓咪圖片,用統計方法取樣出一張特定大小的雜訊圖(例如 512*512),過程中研究人員會控制參數去加上高斯雜訊。第二步是去噪(denoise),透過減去預測的高斯噪聲,得到乾淨的原貓圖。模型訓練的越好,預測的高斯噪聲量越準。
訓練好之後,「擴散模型」在輸出的時候,為了輸出符合使用者文字指令的貓咪圖片,模型會從隨機的雜訊圖開始,應用訓練過程的去噪器,像物理的擴散過程一樣,逐漸改變每個像素點的值,反覆去掉噪點,得到最後新的貓咪圖。
如果有用過 Midjourney 的人,應該也會發現 AI 收到文字指令開始產圖的時候,是從一張模糊不清的圖片,一顆顆像素逐漸改變,變成你要的圖。
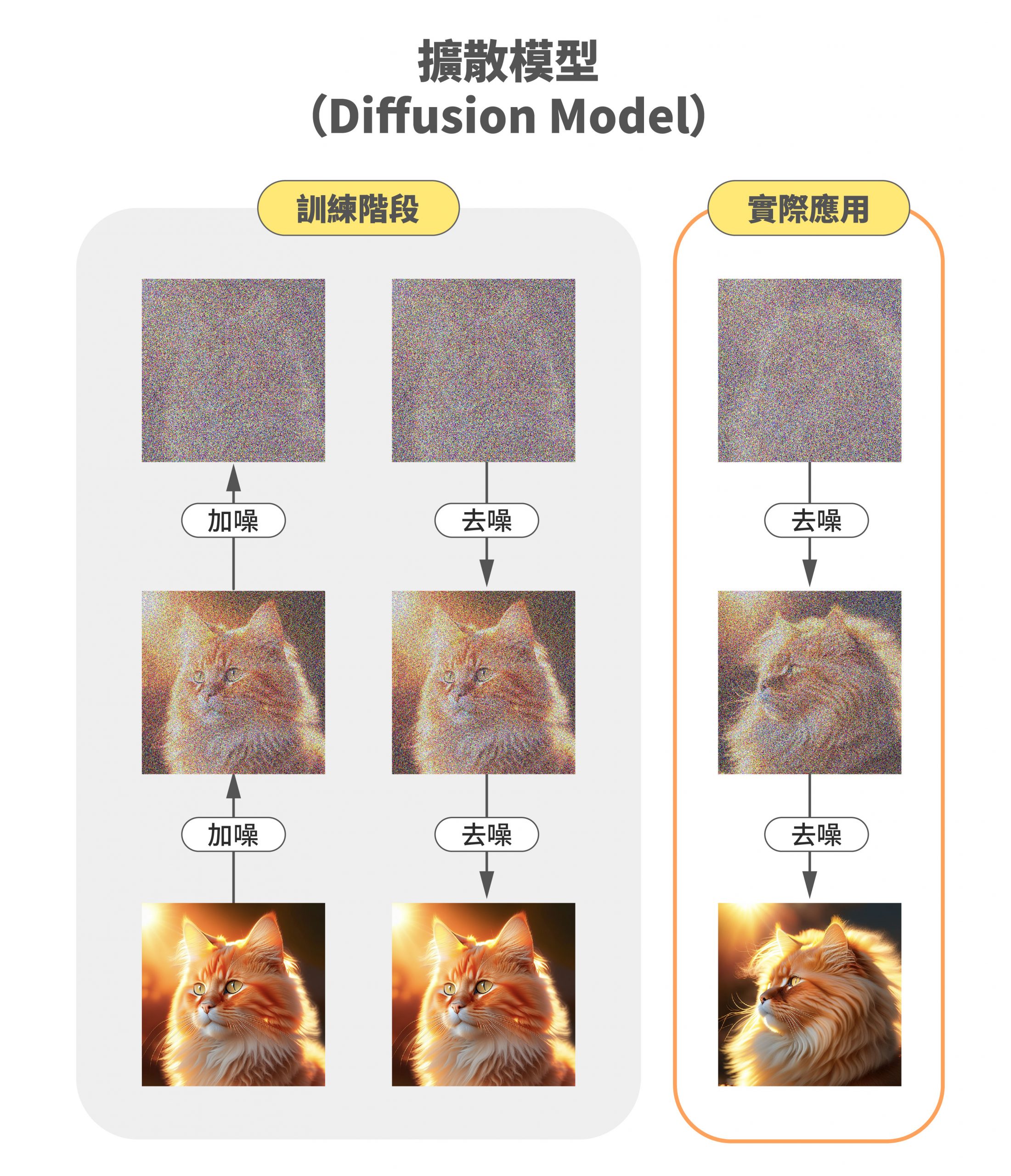
圖|研之有物(資料來源|李宏毅)
陳駿丞指出,由於這些噪聲都是研究員自己加的,所以控制度極高,也可以掌握其中細部的變化過程。而這種「保姆式」訓練法,最大的好處就在於:擴散模型是一種漸進式學習的過程,因此對於細節的掌握度將會更高。
陳駿丞提到,兩種方式的訓練時間其實差不多,但以執行時間來說,「擴散模型」會比較久一點,因為需要慢慢摸索,而 GAN 則是幾乎一步到位。不過,雖說處理時間可能較長,「擴散模型」卻也因為訓練比 GAN 更穩定與更全面這份特質,可以訓練很大的資料集,也能生出較為豐富多元的成果。
侵權與假消息——生成式 AI 的負面影響
能生出細膩而接近真實的圖乍聽之下是好事,但它同時也是一把雙面刃,可能伴隨著侵害智財權、製造假消息等等負面效應。
在訓練生成式 AI 相關模型時,必定需要大量的資料做為參考,而以 AI 繪圖來說,許多資料其實是未經授權的網路圖片;假設宮崎駿的圖片被盜用去訓練開源模型,那這些生成式 AI 後來生出的圖可能就會帶有宮崎駿的風格或曾經畫過的元素,這樣是否會帶來侵權或抄襲的問題?是我們必須思考的重要課題。
而說到假消息,就一定得談到值得關注的「深偽」(Deepfake)技術。雖然這個詞很容易讓人聯想到一些負面的事件,比如新聞報導網紅小玉用深偽技術製作不雅影片。然而,陳駿丞澄清,深偽技術最常出現的場域其實是在電影工業中。其中,最知名的應用,莫過於《玩命關頭》系列電影,在拍攝期間主角保羅沃克不幸意外離世,劇組便透過電腦合成影像技術,讓主角的弟弟替身上陣,主角身影得以再次與觀眾相見。
用你的魔法對付你!反制深偽影像的 AI
深偽技術若運用得宜,便是賺人熱淚的神器,反之,卻也可能成為萬人唾罵的幫兇,面對這樣強大的工具,難道我們只能乖乖束手就擒嗎?才不!既然 AI 如此強大,那我們就訓練 AI 來對付它!
陳駿丞分享道,反制深偽影像常用的方法便是訓練「二元偵測器」,藉由蒐集大量真實與偽造影像資料去訓練 AI,讓它得以判斷影像的真偽。然而,深偽有很多種,而二元偵測器對於沒有看過的資料,表現會大打折扣。
過去人們是用 GAN 來生圖,現在是用擴散模型來產圖,未來也有可能出現新的方式,想要找出一個一勞永逸的方法,其實並不容易。
陳駿丞認真地說,深偽偵測的過程,其實很像在研發一套「防毒軟體」,防毒軟體很難永遠跑在病毒前面,大多是遇到病毒再往下思考解方。但是,面對這樣的情況也不用完全悲觀,因為訓練偵測模型可以透過「非監督式」和「自監督式」等方式去進行模擬,進而得出比較能廣泛應用的工具。
除了偵測深偽的錯處之外,我們也可以針對訓練資料動點手腳,像是加上一些「浮水印」。許多生成式 AI 的訓練資料來自圖庫圖片,其中許多圖片自帶防盜浮水印,假設 AI 蒐集了這些素材,往後生成的圖片中可能就會出現「版權所X」等等字樣。
而我們能做的,便是為訓練資料加上肉眼看不見的浮水印。比如說,在影像領域中,伽碼(gamma)指的是用來編(解)碼照度的非線性曲線,我們可以偷偷將浮水印藏在人眼看不見的伽碼範圍中,唯有調整到特定區域,才能看見浮水印。聽起來是不是很像我們小時候用檸檬汁玩的隱形墨水呢?
同樣是浮水印,我們也可以將它藏在人眼比較不敏感的頻率中,然後偷偷放去圖片中邊邊角角的地方,讓人眼看不出來。 加入浮水印後,我們就可以進一步訓練偵測器去尋找浮水印。假設偵測器能在圖上面找到浮水印,那就可以藉此推斷圖的真偽。
而相對偵測、加浮水印等等「補救」的方式,假設我們已經掌握了一些模型的架構,便能透過添加「對抗樣本」(Adversarial Examples),直接攻入生成式 AI 的大本營,讓這些深偽 AI 只能生出一些亂七八糟、毫無邏輯的圖片,或是強迫生成特定的圖案。例如找出幾個常用、能進行臉部特徵操作的 GAN,針對它們研發相關對抗樣本,如此一來,只要加入了團隊開發的噪聲,便能同時打壞這幾種 GAN 的生成。
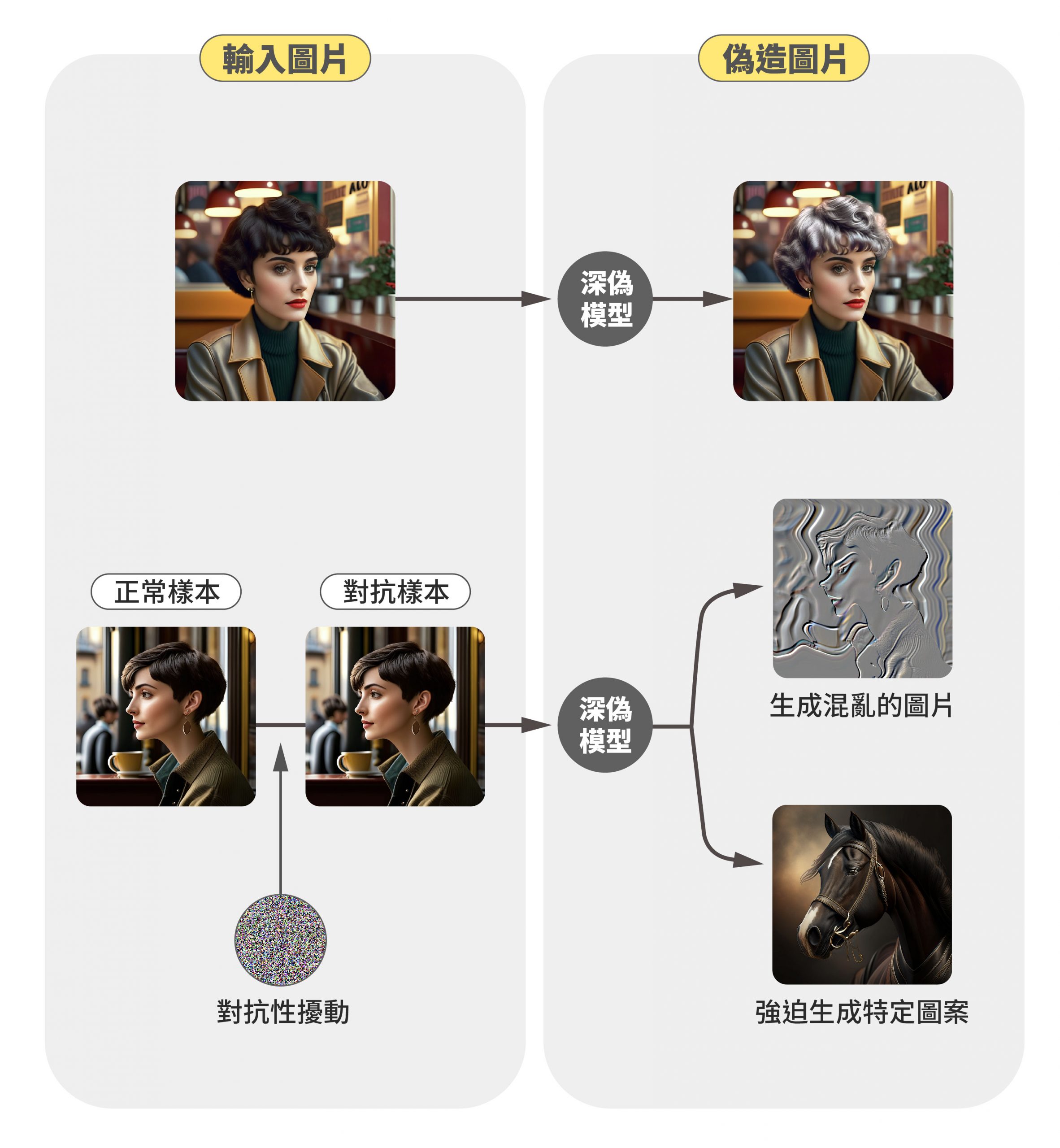
圖|研之有物
假消息滿天飛怎麼辦?交給深偽影像偵測器!
這麼看下來,深偽偵測若想做得好,需包含的面向又多又廣、還很複雜,但請各位別緊張,陳駿丞與中研院、臺灣大學、臺灣科技大學、成功大學、中央大學以及國家高速網路與計算中心其他教授與研究員共同組成的研究團隊,最近才剛打造出一款泛用性相對較佳的「深偽影像偵測器」,團隊其他研究成員包括王新民研究員、曹昱研究員、花凱龍教授、許志仲教授、許永真教授、蔡宗翰教授與國網的郭嘉真研究員。
這款偵測器以慕尼黑工業大學和義大利拿坡里費德里克二世大學共同提出的偽造人臉資料庫「Face Forensic++」為基礎,透過自監督的方式去產生出深偽的各式可能形式。
團隊是如何訓練偵測器的呢?具體的運作方式是:先偵測輪廓、產生一個「面罩」去界定人臉的位置;接著,再讓偵測器透過些許微調去模擬深偽影像的特徵;再來,將這些「模擬的深偽影像」丟回去當作訓練資料。經過訓練的偵測器便能大幅升級,可以根據顏色、頻率、邊緣特徵等等參數,去判斷影像的真偽,甚至可以幫這些深偽影像區分難度呢!
圖│研之有物(資料來源│陳駿丞)
聽起來,這樣的偵測器已經很完美了?陳駿丞笑著說,這樣的內容一經發表,偽造資訊的一方可能又會想辦法繞過這些地方,對雙方來說,這就是場永無止盡的攻防戰,對此,陳駿丞表示,團隊想要完成的,便是:
盡量提供一個比較完整的解決方案,提供普羅大眾各種可能的工具,盡可能讓大家的資料不會被偽造,並幫助他們偵測。

圖|研之有物
深偽技術防護罩——對所有事保持懷疑
這一份深偽影像偵測器凝結了眾人的心血,陳駿丞很期待未來偵測器正式上線後,能透過國家高速網路與計算中心設計的好用介面讓大家方便操作,在詐騙防治方面盡一份心力。同時,也期待各界看到這個工具的潛力,願意成為堅強的支持力量。
那在這麼好用的工具正式上線之前,我們又該如何去判斷影片的真假呢?陳駿丞傳授了我們一些獨家小絕招:首先:注意「姿勢」,深偽影片可能會出現一些不自然的怪異姿勢;其次,可以關注「背景」,比如突然出現裂痕之類的;再來,也要看看「衣服」等等細節,可能會發現破圖的蹤跡。而影片若是出現側臉時,也比較容易發現瑕疵,比如說頭髮動得很怪、眼神不對、牙齒沒牙縫等等。
另一方面,如果影像的解析度太低,也會影響深偽偵測的準確性,所以,對於太過模糊的圖片、影片,都應該格外小心。
陳駿丞也提醒,隨著相關造假技術日臻成熟,圖片、影片中的細微瑕疵將會越來越難以察覺,這時候,一定要謹記以下原則:
不能像以前一樣看到影片就覺得是真的,還是要抱持懷疑的態度。
假設看到一些違反常理或「怪怪」的內容,一定要多方查證,絕不可以馬上就相信。
讀到這裡的各位,想必已經被陳駿丞裝上了一套強而有力的「深偽防毒軟體」,希望大家帶著這層防護罩,在生活中遠離虛假、靠近真相!(p.s. 要記得定期更新啊!)

圖|研之有物



































