

- 文/陳立欣
你知道亞洲第一次成功的核分裂實驗是在臺灣完成的嗎 ?
1934 年 7 月 25 日晚間,就在今天的臺灣大學二號館 101 室,舉行了一項令人興奮的偉大實驗。科學家用高壓直線型加速器使質子加速前進,撞擊鋰原子而得到了兩個 α 粒子!這是亞洲第一次,也是世界第二次成功分裂原子核的實驗。而進行這項實驗的科學家,就是時任臺北帝大物理學講座首任教授——荒勝文策(Bunsaku Arakatsu)。
醉心物理學研究,歐洲行開啟高能物理之路
荒勝文策出生於 1890 年 3 月 25 日,日本兵庫縣印南郡的一個小漁村。他從御影師範學校與東京高等師範學校畢業後,一度曾在佐賀縣擔任教職。後來在興趣的推動下,1915 年進入京都帝國大學物理學系就讀。1918 年他從京都帝國大學物理學系畢業,並旋即擔任該校講師。其後陸續擔任京都帝國大學物理學系助理教授、甲南高等學校教授、臺灣總督府高等農林學校教授。
從事教職之後,他還是對研究比較感興趣,後來因緣際會之下,他以臺灣總督府在外研究員的身分前往歐洲留學,正式開啟了他與高能物理學的淵源。
荒勝到了歐洲之後,曾經短暫留學於德國的柏林大學(今柏林洪堡大學),跟隨物理學巨擘阿爾伯特・愛因斯坦(Albert Einstein)作研究,當時也正是哥本哈根詮釋風靡全世界的時候。荒勝在自傳中表示,無論在物理或是思考面,都受到愛因斯坦相當大的影響,使得原本矢志攻讀理論物理學的他,轉而對原子核實驗產生了相當大的興趣。

因此,一年後他到瑞士蘇黎世聯邦理工學院師從保羅・謝樂(Paul Hermann Scherrer),並進行有關鋰原子中自由電子分布的研究。緊接著他到英國劍橋大學卡文迪西實驗室,師從約瑟夫.湯姆森(Sir Joseph John Thomson)、歐尼斯特・拉塞福(Ernest Rutherford)、詹姆士.查兌克(Sir James Chadwick)等人共二年半的時間。(編按:此三人正是中學物理課本中介紹近代物理中,對原子核構造發現有重大貢獻的三位物理學家。湯姆森以陰極射線實驗發現了電子、拉塞福以金箔實驗確立了原子核的存在、查兌克則發現了中子。)
他於 1928 年 8 月獲得京都帝國大學理學博士學位,而畢業論文的主題,就是運用愛因斯坦狹義相對理論裡的「質能互換公式」理論,撰寫出以原子釋出巨能的理論公式。他從事高能物理學研究之路,自此開啟。
臺灣首任物理學教授,完成亞洲首次核分裂實驗
1928 年 12 月,荒勝來到了臺灣總督府轄下的臺北帝國大學,擔任物理學講座的首任教授,並開設普通物理與原子論等相關課程,也是臺北帝國大學首次開設物理學相關課程。荒勝趁著在歐洲進修的機會,大肆採購了許多教學研究相關的圖書與器具,為臺北帝國大學的物理學發展帶來很大的幫助。
1932 年 4 月《自然》雜誌裏有一篇論文,描述英國劍橋大學卡文迪西實驗室怎樣用 Cockcroft-Walton 的加速器,製造快速質子,打入鋰(Lithium)原子核後引發核反應,產生一對 α 粒子來促成鋰蛻變。

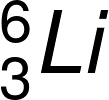 )與氘(
)與氘(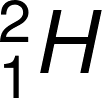 )反應,形成高度激發狀態的中間產物
)反應,形成高度激發狀態的中間產物 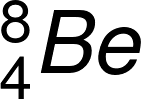 原子核,並立即再衰變為兩個 α 粒子(
原子核,並立即再衰變為兩個 α 粒子(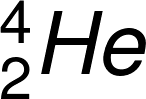 )。圖中的紅色球體代表質子,藍色球體則代表中子。圖/wiki
)。圖中的紅色球體代表質子,藍色球體則代表中子。圖/wiki在瞭解了這個過程內容後,荒勝就對助手木村毅一說:「這是個大變動之事,我們也來試看看吧!」
荒勝決定在臺北帝大二號館 101 室建造 Cockcroft-Walton 型加速器。當時臺灣設備簡陋資源不足,有許多問題需要克服。除了器材需要打造,實驗室裡面也沒有天然的放射線源,荒勝借鑑臺北帝國大學理農學部無機化學講座的研究,嘗試從北投石中提煉釙充當 α 線源。此外實驗中需要的重水,也自行設計器材提煉取得。
最後就是電力的問題,Cockcroft-Walton 型加速器需要穩定而充沛的直流電力,進行實驗電壓不足將無法擊碎原子核。幸虧當時臺北工業職業學校提供器材奧援,才解決了直流電的問題。在萬事皆須重頭準備的臺北帝大也能完成此一實驗,由此可見荒勝文策不屈的意志。
1934 年 7 月 25 日夜裡,荒勝成功完成人工撞擊原子核(Li(p, α)He)的實驗。該次實驗重現並證實了 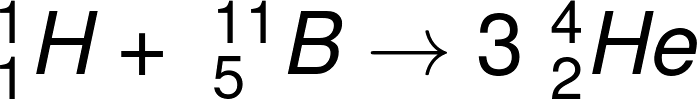 的反應,並發現用高速「氘離子」撞擊「鋰」,也能使鋰同位素產生
的反應,並發現用高速「氘離子」撞擊「鋰」,也能使鋰同位素產生 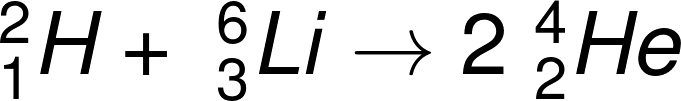 的反應。
的反應。
這次實驗在當時轟動整個日本的物理學界。這是日本史上第一個加速器(全世界第二座這一型的加速器),而這一次追試成功,距離《自然》雜誌刊登論文也只不過經過 2 年。
與原子彈無法迴避的淵源 二戰未能成功的 F 計畫
1941 年,荒勝成功使鈾原子與釷原子產生核分裂反應,這使得荒勝註定要在原子彈計畫的篇章中留下身影。二戰後期,大日本帝國海軍招集荒勝進行研究,成立了一個研發小組,成員也包含了湯川秀樹。
荒勝一開始就決定採用離心機來提煉鈾 235,而不是世界上普及的熱擴散法。他的研究成果,也曾被美國研究原子彈的曼哈頓計劃作為數據計算參考。
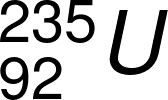 )的核分裂反應示意圖。鈾-235 受到中子(n)撞擊後,形成極度不穩定的鈾-236,此不穩定的鈾隨後分裂為兩個較輕的原子(Ba-144 與 Kr-89)、產生三個新的中子,並伴隨能量釋放。這些新的中子會再去撞擊周圍其他的鈾-235,如此不斷重複進行,產生連鎖反應,引發巨大的能量。圖/wiki
)的核分裂反應示意圖。鈾-235 受到中子(n)撞擊後,形成極度不穩定的鈾-236,此不穩定的鈾隨後分裂為兩個較輕的原子(Ba-144 與 Kr-89)、產生三個新的中子,並伴隨能量釋放。這些新的中子會再去撞擊周圍其他的鈾-235,如此不斷重複進行,產生連鎖反應,引發巨大的能量。圖/wiki荒勝文策曾自言:
我自小喜歡旋轉的東西,也許這是我選擇離心機的真正原因。我一輩子喜歡的研究,就是轉動體。
然而,由於當時日本政府內部的混亂以及資源的相對缺乏,致使日本核計畫未能如美國、英國與納粹德國一樣發展迅速。以至於在荒勝的 F 計畫先從日本遷到朝鮮,後因大戰結束也被迫中止了 F 計畫。
1945 年 8 月 6 日,美軍在廣島投下原子彈,驚人的爆炸力與毀滅性的災難,引起了日本學界的重視。日本陸軍動員了東京理化研究所的仁科芳雄前往觀察研究,而日本海軍則是委任京都帝國大學的荒勝文策,並組織「京都帝國大學原爆災害調查班」進行調查。
荒勝與仁科皆震驚於爆炸威力之強悍,且不斷進行爆炸的計算分析,兩人共同的結論就是「這應該就是原子彈」,經過計算荒勝精確指出爆炸時的高度與位置,並得出閃光時間約在五分之一秒和二分之一秒之間,其調查報告數據計算之精確,震驚世界。
可惜的是,雖然有著最頂尖的相關學識,卻因戰爭的局勢而不得不被迫放棄研究。
戰後,聯合國軍最高司令官總司令部(GHQ)於 1945 年 9 月 28 日下令禁止日本進行有關原子物理與航空學的研究,並拆除京都大學荒勝研究室的迴旋加速器,將之傾倒入琵琶湖。荒勝文策的大量報告與研究筆記也遭到沒收,該次拆除行動也引來了國際間的一陣撻伐。甚至引發了包含美國麻省理工學院在內的科學家們對美國陸軍的抗議,美國陸軍長官並因此引咎道歉,承認拆除行動的錯誤。
雖然在戰後無法持續相關的研究,荒勝文策仍影響了日本高能物理學的發展。無論是在京都大學發展的 Cockcroft-Walton 型加速器,或是發表在《自然》雜誌與木村和植村一同利用宇宙射線進行的研究。甚至是湯川秀樹,也在畢業後特地回母校旁聽其課程,並深受其影響。荒勝的努力為日本高能物理學在荒野中展開了道路,也讓原子能科學在日本持續發展。

在 1949 年湯川秀樹獲得諾貝爾物理學獎後,荒勝感嘆到道:
晚輩得了諾貝爾獎一切都值得了(後輩がノーベル賞を受賞したことで全てが埋め合わされた)。
雖然是欣慰之語,或許也透露出這位奠基者心中仍有所遺憾。
角落也無法掩蓋裡的光芒,開創日本高能物理的荒野道路
鑽石即使擺放在角落,也會發出迷人的光芒。我想,用這句話來形容荒勝文策再適合也不過了。身處日本學術邊陲的臺北帝國大學開設理科講座,在講座成員只有 4 個人的情況下,在不到兩年的時間內就完成了 Cockcroft-Walton 型加速器的設置;甚至完成了全球第二次、亞洲第一次的核分裂實驗,真的非常的不容易。在人手不足、資源不足、連放射線源都沒有的狀態下,還能使用北投石完成實驗,荒勝的堅持態度也為科學研究鍥而不捨的精神立下標竿。
荒勝文策在臺北帝國大學物理科講座的原子核加速實驗,在物理史上的意義是多重的。對臺灣而言,這是臺灣的名字第一次在物理學學術論文期刊。而遺留在臺灣的加速器殘骸與相關器材,成為戰後臺灣成立物理系、發展核子物理實驗的契機。雖然荒勝藉著這次的實驗重返日本,就未再返回臺灣,但他對於臺灣高能物理學發展,仍舊猶如荒野中的第一道腳印,留下了不可磨滅的痕跡。
參考文獻
- 鄭伯昆,〈台大核子物理實驗室 (四)有關的日本科學家〉,《物理雙月刊》,卅卷五期,2008 年 1 月,頁 574-580。
- 松本巍著,蒯通林譯《臺北帝國大學沿革史》,頁 7-11。
- 張幸真,〈臺灣知識社群的轉變——以臺北帝國大學物理講座到臺灣大學物理系為例〉,2003 年 7 月 31 日,頁 101。
- 轉引木村毅一,〈廣島原爆後日譚〉,《神陵文庫》第五卷,1988 年 2 月 29 日,京都三高自昭會,頁 14。
- 張幸真,〈臺灣知識社群的轉變-以臺北帝國大學物理講座到臺灣大學物理系為例〉,2003 年 7 月 31 日,頁 106。
- Info,(阿文開講——F計畫〉,《臺灣物理學會雙月刊》,2016 年 9 月 7 號。







































{kind=link}
{kind=link}
{kind=link}
{kind=link}