- 文/Te-Yi Hsieh|現為英國 University of Glasgow 博士生,主修 Neuroscience and Psychology。研究領域介於心理學、機器人學、神經科學的交界處。
科技日新月異,我們或多或少都在新聞、報章雜誌中看過外貌激似真人的人型機器人。
例如,日本石黑浩(Hiroshi Ishiguro)教授建造與自己如同雙胞胎的機器人、第一個獲得公民權的阿拉伯機器人蘇菲亞(Sophia) ,以及日本長崎奇怪飯店(Henn na Hotel)的人型機器人房務。

現今科技之進步確實讓人瞠目結舌,有一些機器人甚至擁有柔軟的矽膠皮膚呢!
但也許很多人跟我一樣,在看到這些人型機器人時有種詭異、不寒而慄的感覺,尤其是那些越接近真人的機器人,越令人毛骨悚然!
事實上,這樣的不舒服感受有個專有名詞可以解釋,叫做「恐怖谷理論」(亦稱詭異谷,Uncanny Valley)。
什麼是恐怖谷理論?
「恐怖谷」最早由日本機器人學教授 Masahiro Mori 於 1970 年提出1。該理論以一曲線(下圖)說明,人們面對越像自己(人類)的對象,好感度會越高。
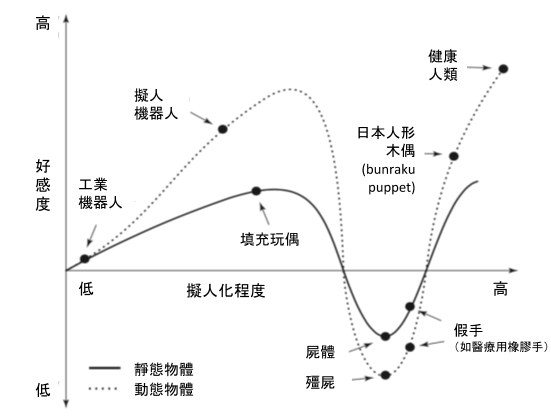
但是當對方的樣貌是幾乎和自己(人類)一樣,卻又出現幾個意外的「非人」特徵時(像是,關節處顯露的機械構造),好感度就會驟降,掉到曲線圖中的谷底。
只有當對象是跟我們完全一樣、是活生生的人類時,好感度才會攀升至最高點。
我們看著機器人幾乎和真人無異的外貌,以及難免顯露的非人特徵,像是機器人僵硬的表情、顯露的機械構造,或是空洞的眼神,內在觀感極為容易被帶入恐怖谷中,抗拒感油然而生。

此外,對於靜態、動態的對象,此理論也做出不同假定:動態的對象會比靜態的帶來更強烈的恐懼感。
顯而易見地,會動的殭屍比靜止的屍體恐怖好幾百倍啊!
我們的恐懼,究竟從何而來?
自 1970 年以來,學者也試著對恐怖谷提出不同解釋。
首先,Mori 本人認為這樣「恐怖」的感覺來自於一種生存的本能,因為這些似人非人的訊息通常透露著生存上的「危險」,像是看見屍體、殘缺的人體軀幹等等,大腦會反射性地產生恐怖的感受、讓自身避開此情境。

Bartneck 與同事3則是用「框架理論」(Framing theory)來解釋此曲線,他們認為這樣令人反感的情緒來自於與自身「基模」(schema)相衝突的刺激物。
也就是說,當我們第一眼看到一個極似真人的人型機器人,腦中關於「人類」的基模會被促發,此基模包含我們對於人類此概念的豐富的知識,因此一旦察覺到任何「非人」的訊息,都會造成認知上的強烈衝突、預期落空,進而產生反感。
此解釋更近一步得到功能性磁振造影(functional Magnetic Resonance Imaging,fMRI)的證據4,以及貝氏數學模型(Bayesian model)的結果5支持。
然而時至今日,研究人員對於恐怖谷產生的真正原因、甚至恐怖谷是否存在,都尚未達成共識。
除了恐怖谷,還有恐怖懸崖!
事實上,Mori當初是根據自身研究經驗、個人觀點提出這個恐怖谷「假說」,並非根據實證資料推論出的結果。
因此,有些研究者在親自進行實驗、數據分析後,竟得到完全不一樣的曲線!
例如,Bartneck與其團隊3為了驗證恐怖谷理論的正確性,採用一系列不同對象的照片,包含:
- 取自ELLE時尚雜誌的真人模特兒照
- 修圖後皮膚顏色變綠的真人照片
- 電繪人像
- 擬人機器人(android):如Actroid、EveR、Repliee Q1
- 人形機器人(humanoid)註:如QRIO、ASIMO
- 動物型機器人:如AIBO、PaReRo、iCat
他們讓 58 位受試者分別觀看這些圖片,並回答「它有多像人」、「我對它的喜好程度」等等的問題。

研究團隊原先預期,受試者應該最不喜歡綠皮膚真人、擬人機器人的照片,因為這兩種照片跟真人照片幾乎沒有差別,僅有少數非人的特徵。
殊不知,統計數據的結果顯示,雖然動物型機器人的擬人程度最低,卻是最受喜愛的對象;人形機器人雖擬人程度位居倒數第二位,受喜愛程度僅次於動物機器人。
完整的喜好排名為:動物型機器人、人形機器人、電繪人像、綠皮膚真人、擬人機器人,最後才是真人。
在這個排名中,最令他們驚訝的是,人們對綠皮膚真人與擬人機器人的好感度,不但沒有比較低,甚至還高於真人模特兒的照片!而且對人形機器人的照片的喜好同樣也高於真人照片。
這樣的數據,與Mori的理論大相徑庭。
基於這樣的數據結果,他們推測真實的曲線可能並非恐怖谷,而是恐怖懸崖(Uncanny cliff),並且建議機器人設計者不應一味追求高度擬人化外觀,而應注重外型與功能間的平衡。
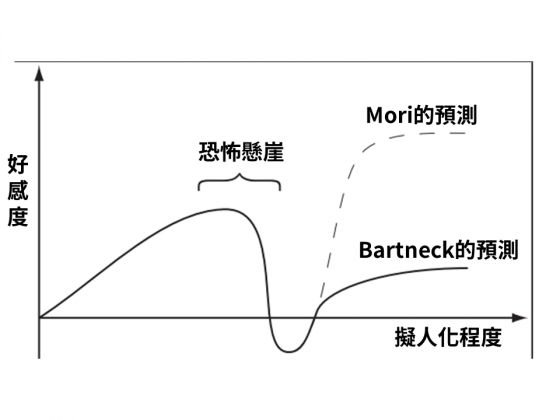
然而 Bartneck 研究中令人較為存疑的是,受試者評定真人照片的擬人化程度竟比其他照片都還要低!究竟 58 人的評分是否具代表性? Bartneck 團隊從 ELLE 時尚雜誌選用的真人照片是否偏誤?都有待商討釐清。
此外,也因為人類擁有豐富的社交經歷,對「真人」的喜好較明確,也受個人經歷、文化等因素影響。因此,單一、特定的人類照片或許無法代表概括性的「人類」此一種類。
細數那些「背叛」恐怖谷理論的研究
比起「恐怖」的情緒,也有研究團隊提出了幾乎相反的結果。
Cheetham、Suter,和 Jancke6發現,當我們無法用肉眼判斷這張圖到底是真人,還是電繪人像(avatar)時,這些越似人非人的臉,越與人們的正向情緒連結,因此,該研究團隊認為恐怖谷實際上應該是「快樂谷」(Happy valley)。
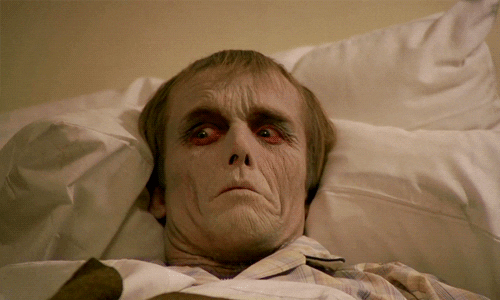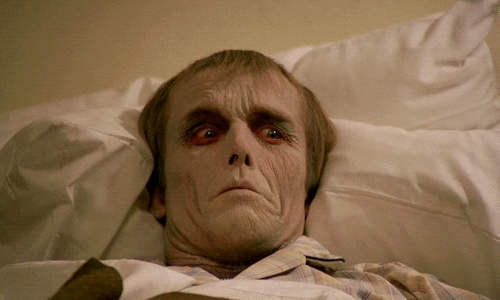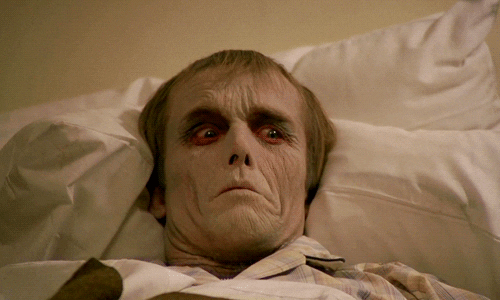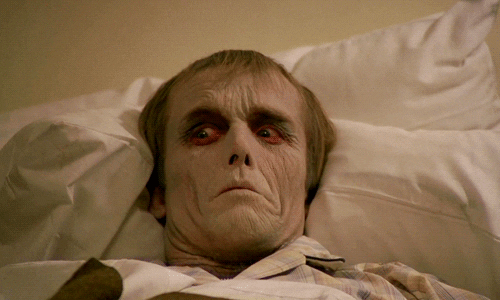
最後,雖然有研究利用「靜態圖片」驗證了恐怖谷的曲線,但是當刺激物改成「動態短片」呈現時,曲線反而趨於平坦,與 Mori 原先假定的「動態物體將帶來更為極端的恐怖谷現象」完全相反2。
然而我們在解釋單一研究結果時,仍不能忘了:不同實驗素材(例如,研究者選用的圖片、影片)、不同受測對象(例如,受試者是大學生?西方人?)都會對結果產生影響。
另外不可忽略的是, Mori 教授在 1970 提出恐怖谷理論時是以日文撰寫,他當時用「親合感」 (shinwa-kan)來描述本文中的「好感度」,英文裡較適切的翻譯為「affinity」或是「likability」。
但有許多研究中都選用「familiarity」,而 familiarity 一字強調的是過去經驗,而非情感連結,使測量的效度受到質疑1,3。
哼哼,咱人類可不只是外貌協會!
雖然要統一總結個別研究的結果並不容易,但研究者目前仍普遍認同:要打造能自然與人社交的機器人,一味追求外觀的擬人化並非一個明智的解法,反而更需著重在外觀與功能上的平衡1,3,7。
因為似人的外貌,會讓使用者期待能以似人的社交方式與之互動,然而要模擬人類社交互動是一項極具挑戰性的工作,例如,機器人的細微表情、情感表達、語言理解、表達、認知歷程、身體律動等等都須加以控制、設計。

從我們目前有的人型機器人來看,此項挑戰似乎尚未成功過,即使是那些乍看下與真人無異的機器人,一但開口、與人互動,不自然與漏洞百出的應對便顯而易見。
在人機互動中,我們能探討的面向仍相當多,像是機器人的語言能力、情緒表達、行為模式、互動者人格特質、個人經歷,絕非是「外觀擬人化程度」一項因素能決定整體互動品質的8,9。
當機器人總是被貼上「毀滅世界」的標籤
此外,我們對機器人的態度、好感度也受到媒體文化制約著,許多人不喜歡機器人可能是因為電影經常把機器人塑造成「人類物種的威脅」。
曾在訪談中開玩笑要毀滅人類的蘇菲亞,被全球媒體熱烈的報導。
然而,運用科技本身無善惡之分,好與壞終究在於使用者。
更何況,我們目前現有的機器人跟科幻電影中的、一般人期待的都差距非常、非常多。
像是在日本長崎的奇怪飯店(Henn na Hotel),雖在四年前目標成為世界上第一家由機器人組成的飯店,卻在2019年因為大多數機器人無法妥善回應房客期待、錯誤百出,而決定逐漸轉回聘用人類員工。

即使現有的社交機器人大多只能做為輔助工具,無法全取代人力,但是研發機器人對人們生活品質的益處,仍是顯而易見的。
例如,在人口老化社會中,機器人能補足長照資源不足的問題,取代大部分勞力工作,減輕照顧者的負擔10。
想讓機器人更貼近人類?千萬不可只注重外表
回到本文所探討的問題中心,人型機器人是否會無一避免地掉入恐怖谷中?就目前的研究證據來看,我們似乎尚未能給出一個肯定的答案。如同大多研究問題,正反方的證據同時存在於文獻中。
再者,恐怖谷曲線很可能會因個人偏好、生活經歷而有所不同。
如 Mori 將「日本人形木偶」(bunraku puppet)放在相當靠近真人親合度的位置。雖然在 Mori 的理論原文中,他也承認這樣的木偶其實說不上是高度擬人化的,但是當在看木偶戲時,會不自覺忘卻木偶非人的外觀特徵,深深融入故事情境與人物情感中。

相對地,我們每個人會覺得親近、懼怕的對象、特徵,也與我們人生經歷緊緊連結,這為探討擬人化外表與互動者好感度關聯的議題上,增添了許多變項與困難。
然而,不管恐怖谷存在與否,都提醒了機器人設計者,不該一味追求高度擬人但可能造成反效果的外貌。
皮克斯動畫「瓦力」(WALL-E)裡的瓦力跟伊芙、迪士尼「大英雄天團」(Big Hero 6)裡的杯麵,它們長得都完全不像人類,卻仍深得觀眾的喜愛。

要打造良好人機關係、提高大眾對機器人的接受度,或許該更強調於情緒表達9、互動模式11、社交技能7,以及使用者在長期人機互動中的心理歷程12,13,畢竟,人類在社交互動中也不是單看外表的膚淺生物吧!
備註
humanoid 和 android 雖然時常混用,用來指稱似人的機器人,但事實上兩詞定義有些微不同。
- humanoid:泛指擁有部分人類外型特徵、受人型啟發設計的機器人,不管擬人程度高或低都能稱為humanoid。
- android:特指完全模仿真人外觀的機器人,會擁有似人的皮膚、頭髮、身材比例,與互動方式等等,如大阪大學(Osaka University)與 Kokoro 公司製造的 Actroid 機器人。
參考文獻
- 1Mori, M., MacDorman, K. F. & Kageki, N. The uncanny valley. IEEE Robot. Autom. Mag. (2012) doi:10.1109/MRA.2012.2192811.
- Piwek, L., McKay, L. S. & Pollick, F. E. Empirical evaluation of the uncanny valley hypothesis fails to confirm the predicted effect of motion. Cognition 130, 271–277 (2014).
- Bartneck, C., Kanda, T., Ishiguro, H. & Hagita, N. Is The Uncanny Valley An Uncanny Cliff? in RO-MAN 2007 – The 16th IEEE International Symposium on Robot and Human Interactive Communication 368–373 (2007). doi:10.1109/ROMAN.2007.4415111.
- Saygin, A. P., Chaminade, T., Ishiguro, H., Driver, J. & Frith, C. The thing that should not be: predictive coding and the uncanny valley in perceiving human and humanoid robot actions. Soc. Cogn. Affect. Neurosci. 7, 413–422 (2012).
- Moore, R. K. A Bayesian explanation of the ‘Uncanny Valley’ effect and related psychological phenomena. Sci. Rep. 2, 864 (2012).
- Cheetham, M. Perceptual discrimination difficulty and familiarity in the Uncanny Valley: more like a “Happy Valley”. Front. Psychol. 15.
- Dautenhahn, K. Socially intelligent robots: dimensions of human-robot interaction. Philos. Trans. R. Soc. B Biol. Sci. 362, 679–704 (2007).
- Hortensius, R. & Cross, E. S. From automata to animate beings: the scope and limits of attributing socialness to artificial agents: Socialness attribution and artificial agents. Ann. N. Y. Acad. Sci. 1426, 93–110 (2018).
- Hortensius, R., Hekele, F. & Cross, E. S. The Perception of Emotion in Artificial Agents. IEEE Trans. Cogn. Dev. Syst. 10, 852–864 (2018).
- Zsiga, K. et al. Home care robot for socially supporting the elderly: Focus group studies in three European countries to screen user attitudes and requirements. Int. J. Rehabil. Res. (2013) doi:10.1097/MRR.0b013e3283643d26.
- Feil-Seifer, D. & Matarić, M. J. Socially assistive robotics. Robot. Autom. Mag. IEEE 18, 24–31 (2011).
- Hortensius, R. & Cross, E. S. From automata to animate beings: The scope and limits of attributing socialness to artificial agents. Ann. N. Y. Acad. Sci. (2018) doi:10.1111/nyas.13727.
- Henschel, A., Hortensius, R. & Cross, E. S. Social Cognition in the Age of Human–Robot Interaction. Trends Neurosci. S0166223620300734 (2020) doi:10.1016/j.tins.2020.03.013.
作者資訊
Te-Yi Hsieh|現為英國University of Glasgow 博士生,主修 Neuroscience and Psychology。研究領域介於心理學、機器人學、神經科學的交界處。
欲知更多作者的研究相關資訊可關注:http://www.so-bots.com/
Twitter: @TeYiHsieh
- 責任編輯|儀珈